






豆瓣电影Top250
一、显示影片基本信息
访问豆瓣电影Top250,获取每部电影的中文片名、排名、评分及其对应的链接,按照“排名-中文片名-评分-链接”的格式显示在屏幕上。
1. 打开豆瓣电影Top250网页
2. 在网页上右击我们所要获取的信息;
例如:要获取《肖申克的救赎》电影的导演,将鼠标移至该电影的导演处,右击鼠标出现。
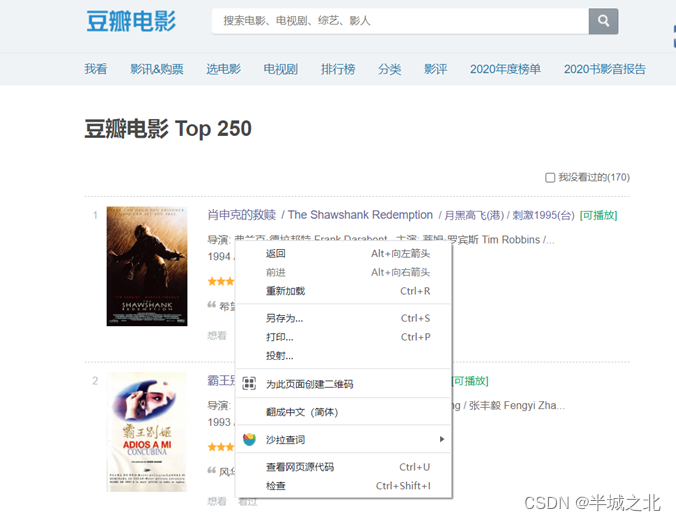
3. 点击检查,即可定位该信息在html网页源码的具体位置;
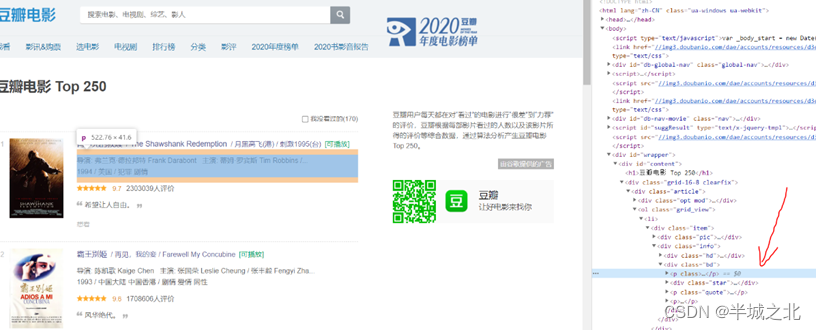
4. 右击对应标签,选择Copy -> Copy selector,即可获得对应元素的CSS选择器。
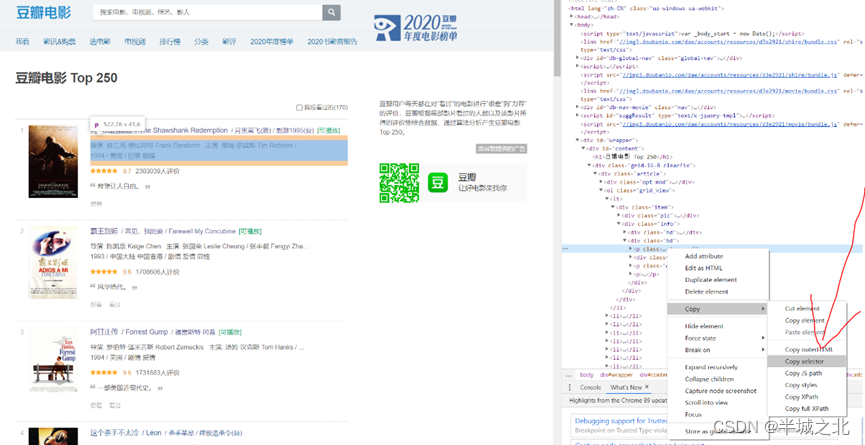
5. 将复制得到的CSS选择器粘贴在soup.select()中即可。
-
参考步骤及代码:
- (1) 在PyCharm中新建项目,命名为webCrawler;
- (2) 在webCrawler项目里新建doubanCrawler文件夹;
- (3) 在doubanCrawler文件夹中创建getTop250.py文件;
- (4) 获取豆瓣Top250基本信息代码如下:
import requests
from bs4 import BeautifulSoup
import time
# 请求网页
def page_request(url, ua):
response = requests.get(url=url, headers=ua)
html = response.content.decode('utf-8')
return html
# 解析网页
def page_parse(html):
soup = BeautifulSoup(html, 'lxml')
# 获取每部电影的排名
position = soup.select('#content > div > div.article > ol > li > div > div.pic > em')
# 获取豆瓣电影名称
name = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)')
# 获取电影评分
rating = soup.select('#content > div > div.article > ol > li> div > div.info > div.bd > div > span.rating_num')
# 获取电影链接
href = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
for i in range(len(name)):
print(position[i].get_text()+'\t'+name[i].get_text()+'\t' + rating[i].get_text() + '\t' + href[i].get('href'))
if __name__ == "__main__":
print('**************开始爬取豆瓣电影**************')
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4421.5 Safari/537.36'}
# 豆瓣电影Top250每页有25部电影,start就是每页电影的开头
for startNum in range(0, 251, 25):
url = "https://movie.douban.com/top250?start=%d" % startNum
html = page_request(url=url, ua=ua)
page_parse(html=html)
print('**************爬取完成**************')
二、存储影片详细信息
访问豆瓣电影Top250,在先前的基础上,获取每部电影的导演、编剧、主演、类型、上映时间、片长、评分人数以及剧情简介等信息,并将获取到的信息保存至本地文件中。
1. 创建downloadTop250.py;
在先前创建的项目webCrawler下的doubanCrawler文件夹中创建downloadTop250.py
2. 参考代码
import requests
from bs4 import BeautifulSoup
import re
import docx
from docx.oxml.ns import qn
# 请求网页
def page_request(url, ua):
response = requests.get(url=url, headers=ua)
html = response.content.decode('utf-8')
return html
# 解析网页
def page_parse(html, ua):
soup = BeautifulSoup(html, 'lxml')
for tag in soup.find_all(attrs={'class': 'item'}):
data = []
# 序号
num = tag.find('em').get_text()
data.append(num)
# 电影名称
name = tag.find_all(attrs={'class': 'title'})[0].get_text()
data.append(name)
# 豆瓣链接
href = tag.find(attrs={'class': 'hd'}).a
url = href.attrs['href']
data.append('豆瓣链接:' + url)
# 评分与评论数
info = tag.find(attrs={'class': 'star'}).get_text()
info = info.replace('\n', '').lstrip()
# 使用正则表达式获取数字
mode = re.compile(r'\d+\.?\d')
i = 0
for n in mode.findall(info):
if i == 0:
# 评分
data.append('豆瓣评分:' + n)
elif i == 1:
# 评分人数
data.append('评分人数:' + n)
i = i + 1
# 进入子网页,获取每部电影的具体信息
sub_page_requests(url, ua, data)
print('第%s部电影信息爬取完成' % num)
# 子网页处理函数:进入并解析子网页/请求子网页
# 获取影片详细信息
def sub_page_requests(url, ua, data):
html = page_request(url=url, ua=ua)
soup = BeautifulSoup(html, 'lxml')
# 影片信息
info = soup.find(attrs={'id': 'info'}).get_text()
data.append(info)
# 影片简介
summary = soup.find(attrs={'property': 'v:summary'}).get_text()
summary = summary.replace('\n', '').replace(' ', '').lstrip()
data.append(data[1] + '影片简介:\n' + summary)
# 保存影片信息
save(data)
def save(data):
file = docx.Document()
# 设置字体格式
file.styles['Normal'].font.name = u'Times New Roman'
file.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'Times New Roman')
# 将爬取到的数据写入word中
for element in data:
file.add_paragraph(element)
file.save('result/' + data[0] + '、' + data[1] + '.docx')
if __name__ == "__main__":
print('**************开始爬取豆瓣电影**************')
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4421.5 Safari/537.36'}
# 豆瓣电影Top250每页有25部电影,start就是每页电影的开头
data_List = []
for startNum in range(0, 251, 25):
url = "https://movie.douban.com/top250?start=%d" % startNum
html = page_request(url=url, ua=ua)
# 获取每部影片的信息
page_parse(html=html, ua=ua)
print('**************爬取完成**************')

















 2380
2380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









