






1 引言
1.1 背景介绍
在如今的信息时代,搜索引擎几乎无处不在:从我们每天使用的百度、Google,到电商平台上的商品搜索、短视频平台中的内容推荐,搜索已经从传统的“文本匹配”演进到更复杂的“语义理解”。
与此同时,多模态学习——也就是同时处理图像、文本、音频等多种信息形式的任务,逐渐成为人工智能领域的重要研究方向。特别是在图文匹配、图文检索、图文生成等场景下,单一模态已难以满足复杂的信息需求。
本项目正是基于这样的背景出发,目标是构建一个本地部署的图文搜索引擎,核心依赖 OpenAI 提出的 CLIP 模型(Contrastive Language–Image Pretraining)。这个搜索引擎可以让你:
-
✅ 通过一句话描述,快速找到与之最相关的图像;
-
✅ 将自己的图像-文本数据作为素材,建立属于自己的“私人图文搜索系统”;
-
✅ 学习和理解图文对齐、多模态表示、语义搜索等关键技术原理;
-
✅ 甚至将搜索引擎嵌入到你自己的产品或应用中。
无论你是:
-
✅ 想从头实现一个小型搜索引擎;
-
✅ 希望入门多模态表示与相似度检索;
-
✅ 或者单纯希望尝试部署一个离线运行的 AI 项目;
这篇文章都将为你提供一个完整、可操作的思路,帮助你从 0 到 1 构建一个简单但实用的多模态搜索系统。如果各位读者觉得还算有点参考价值,麻烦点赞收藏,谢谢各位啦。
本文同时给出相关完整代码与数据集在GitHub,有实验需要可以自取:
GitHub - ZhengDongHang/Local-Search-Engine: 本项目开发了一个本地搜索引擎基于CLIP模型实现,实现了图文的推荐算法查找,并提供实验数据。
1.2 技术动机
在构建搜索引擎时,核心技术的选择至关重要。传统的搜索方法(如 TF-IDF、BM25 等)依赖词语的精确匹配,往往难以理解语义层面的关联。而近年来,深度学习尤其是 跨模态模型 的兴起,使得我们可以将搜索扩展到图文之间,真正实现“以文搜图”或“以图搜文”。
CLIP(Contrastive Language–Image Pretraining) 模型正是这类跨模态技术中的佼佼者。它由 OpenAI 提出,通过在大规模图文配对数据上进行预训练,学会了如何将图像和文本映射到同一个语义向量空间。在这个空间中,相互匹配的图文对会彼此靠近,而无关的图文则会被推远。
CLIP 的几个关键优势:
-
✅ 跨模态表示能力强:CLIP 可以同时理解图像和自然语言,将两者转换为可比较的向量;
-
✅ 零样本泛化能力:即使遇到未见过的文本描述或图像类型,CLIP 仍然能够进行合理的匹配;
-
✅ 无需训练即可搜索:使用 CLIP,只需要预先提取图像和文本向量,就能直接进行相似度检索,适合搭建轻量级、离线的本地搜索系统;
-
✅ 推荐算法中的“语义匹配”能力:在推荐场景中,CLIP 可用于评估用户输入(如一句描述)与候选内容之间的语义相似度,选择 Top-K 最相关项返回,实现“多模态推荐”。
基于上述优势,CLIP 被越来越多地用于图文检索、图像分类、内容审核等任务。本项目正是将其应用于构建图文搜索引擎,将“推荐算法”视为一次语义相似度排序问题,即:
“找到与用户输入的文本向量最接近的图像向量”。
这种方法不但简洁高效,而且易于扩展,只需替换数据即可快速适配不同场景(如文献图检索、电商图搜商品、图文社交内容搜索等)。
2 项目架构
因本项目内容关注数据分析领域,本文使用 jupyter notebook 作为开发IDE,架构采取如下格式:
数据预处理 —— 哈希存储算法(可选) —— CLIP模型构建 —— 推荐算法实现
数据预处理:负责构建训练数据集,本项目使用 图片-文字 作为示例,构建起对应键值对,方便后续模型调用。
哈希存储算法(可选):在数据预处理部分默认存储为顺序表(不了解的同学可以去补充下‘数据结构与算法’相关知识),在少量数据集的索引并不明显,但在大量数据集上的效果比较慢,因此使用哈希存储加速索引,建议大量数据集的读者使用。
CLIP模型构建:Clip模型通过文本transformer转换器和图像transformer转换器,将其映射到一个矩阵上进行跨模态分析(也就是可以将文本/图像映射到一个高维空间内),为后续的跨膜太搜索引擎提供支持。
推荐算法实现:使用最简单的余弦相似度计算(因为经过CLIP已经在同一高维空间内),并且补充最低相似度过滤操作(防止搜索相关度很低的结果),并给出搜索相关值。
3 代码实现
3.1 数据预处理
import os
import fitz # PyMuPDF
from PIL import Image
from tqdm import tqdm
import json
def extract_text_image_pairs(pdf_folder, output_image_folder, output_json="text_image_mapping.json"):
os.makedirs(output_image_folder, exist_ok=True)
result = []
idx = 0
for file_name in tqdm(os.listdir(pdf_folder)):
if not file_name.endswith(".pdf"):
continue
pdf_path = os.path.join(pdf_folder, file_name)
doc = fitz.open(pdf_path)
for page_number in range(len(doc)):
page = doc.load_page(page_number)
text = page.get_text().strip()
if not text:
continue # 跳过没有文本的页面
# 将整个页面截图保存为图像
pix = page.get_pixmap(dpi=200)
image_path = os.path.join(output_image_folder, f"{os.path.splitext(file_name)[0]}_page_{page_number + 1}.png")
pix.save(image_path)
result.append({
"text": text,
"image_path": image_path
})
idx += 1
if page_number == 3: # 为节省时间,只取前 n 张进行训练
break
# 保存 JSON 映射
with open(output_json, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"共提取 {idx} 个文本-图像对,已保存至 {output_json}")
return result
extract_text_image_pairs(
pdf_folder="ori_data/The_combination_of_images_and_text",
output_image_folder="mid_data/extracted_images",
output_json="mid_data/text_image_mapping.json"
)
共提取 70 个文本-图像对,已保存至 mid_data/text_image_mapping.json
[{'text': '2 0 2 2\nL I V I N G P R O D U C T S',
'image_path': 'mid_data/extracted_images/Living_Products_2022_page_1.png'},
{'text': 'Living Products\n2022\ncassina.com',
'image_path': 'mid_data/extracted_images/Living_Products_2022_page_2.png'},
3.2 哈希存储(可选)
import json
import pickle
def build_hashed_mapping(json_path, output_pickle_path="hashed_mapping.pkl", key="image_path"):
"""
从 JSON 列表创建哈希表,并保存为 pickle
:param json_path: 原始 JSON 路径(列表格式)
:param output_pickle_path: 输出的 pickle 路径
:param key: 使用哪个字段作为哈希表键(如 image_path 或 text)
"""
with open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
# 构建哈希字典:key => entire entry
hashed_data = {entry[key]: entry for entry in data}
# 保存为 pickle
with open(output_pickle_path, "wb") as f:
pickle.dump(hashed_data, f)
print(f"✅ 已保存哈希结构数据,共计 {len(hashed_data)} 项,路径:{output_pickle_path}")
return hashed_data
build_hashed_mapping(
json_path="mid_data/text_image_mapping.json",
output_pickle_path="mid_data/image_path_hash.pkl",
key="image_path"
)
✅ 已保存哈希结构数据,共计 70 项,路径:mid_data/image_path_hash.pkl{'mid_data/extracted_images/Living_Products_2022_page_1.png': {'text': '2 0 2 2\nL I V I N G P R O D U C T S',
'image_path': 'mid_data/extracted_images/Living_Products_2022_page_1.png'},
'mid_data/extracted_images/Living_Products_2022_page_2.png': {'text': 'Living Products\n2022\ncassina.com',
import json
import pickle
import time
import random
# 加载原始 JSON 列表
with open("mid_data/text_image_mapping.json", "r", encoding="utf-8") as f:
json_data = json.load(f)
# 加载哈希表(以 image_path 为 key)
with open("mid_data/image_path_hash.pkl", "rb") as f:
hash_data = pickle.load(f)
# 获取所有 image_path 用于采样
all_image_paths = [entry["image_path"] for entry in json_data]
sample_paths = random.sample(all_image_paths, min(100, len(all_image_paths))) # 最多采样100个
# -----------------------
# 1️⃣ 列表查找测试
# -----------------------
json_start = time.time()
for path in sample_paths:
_ = next((entry for entry in json_data if entry["image_path"] == path), None)
json_end = time.time()
json_total_time = json_end - json_start
json_avg_time = json_total_time / len(sample_paths)
# -----------------------
# 2️⃣ 哈希查找测试
# -----------------------
hash_start = time.time()
for path in sample_paths:
_ = hash_data.get(path, None)
hash_end = time.time()
hash_total_time = hash_end - hash_start
hash_avg_time = hash_total_time / len(sample_paths)
# -----------------------
# ✅ 结果展示
# -----------------------
print(f"查找轮数:{len(sample_paths)}")
print(f"🔍 JSON 列表查找总耗时:{json_total_time:.6f} 秒,平均每次:{json_avg_time:.8f} 秒")
print(f"⚡ 哈希表查找总耗时:{hash_total_time:.6f} 秒,平均每次:{hash_avg_time:.8f} 秒")
print(f"🚀 哈希查找加速比:约 {json_avg_time / hash_avg_time:.1f} 倍")
查找轮数:70 🔍 JSON 列表查找总耗时:0.000800 秒,平均每次:0.00001143 秒 ⚡ 哈希表查找总耗时:0.000187 秒,平均每次:0.00000267 秒 🚀 哈希查找加速比:约 4.3 倍
3.3 CLIP模型构建
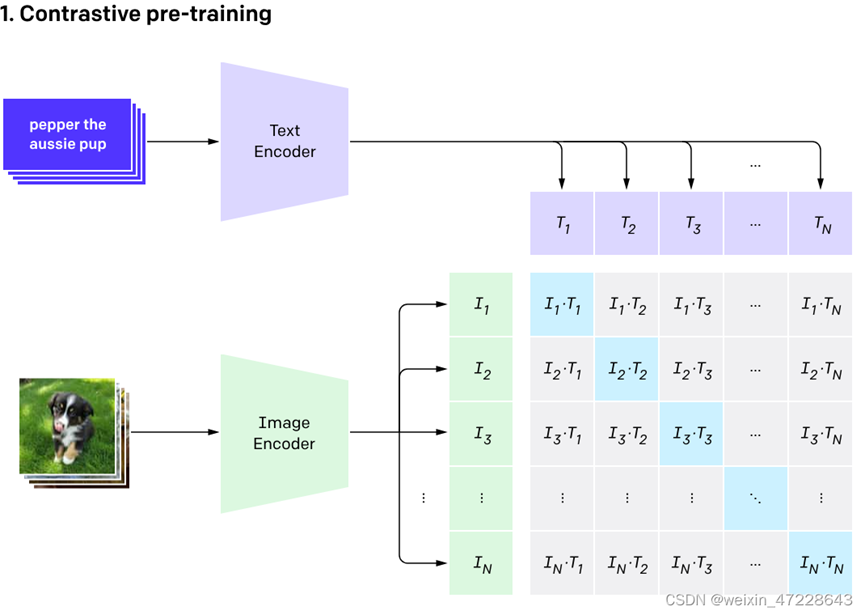
在进行CLIP模型构建的时候,需要先进行文本向量化与图片向量化,输入到分别对transformer中进行同一高维向量中,输入CLIP模型(因为有包了,我就直接调用了,我就是调包侠,同时感谢源码分享者),如下代码所示:
import os
import json
import torch
import clip
from PIL import Image
from tqdm import tqdm
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
model, preprocess = clip.load("ViT-B/32", device=device)
# 加载图文对
with open("mid_data/text_image_mapping.json", "r", encoding="utf-8") as f:
data_pairs = json.load(f)
# 结果保存
text_features_list = []
image_features_list = []
pair_ids = []
for i, item in enumerate(tqdm(data_pairs)):
try:
text = clip.tokenize(item["text"]).to(device)
image = preprocess(Image.open(item["image_path"]).convert("RGB")).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 归一化向量
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
image_features_list.append(image_features.cpu())
text_features_list.append(text_features.cpu())
pair_ids.append(i)
except Exception as e:
print(f"跳过第 {i} 个 pair")
# 拼接保存
image_tensor = torch.cat(image_features_list, dim=0)
text_tensor = torch.cat(text_features_list, dim=0)
torch.save({
"image_features": image_tensor,
"text_features": text_tensor,
"pair_ids": pair_ids
}, "mid_data/clip_features.pt")
print("图文向量已提取并保存至 mid_data/clip_features.pt")
100%|██████████| 70/70 [00:04<00:00, 15.82it/s]图文向量已提取并保存至 mid_data/clip_features.pt
3.4 本地搜索引擎
为了让测试方便,先输入前三个图片对应的文本,方便后续测试,此步不涉及训练,只是单纯的输出,因此是可选操作。
import random
import json
from PIL import Image
import clip
import torch
# 路径配置
mapping_json = "mid_data/text_image_mapping.json"
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载CLIP模型
model, preprocess = clip.load("ViT-B/32", device=device)
# 加载图文对映射
with open(mapping_json, "r", encoding="utf-8") as f:
data = json.load(f)
# 随机选择3个图像
samples = random.sample(data, k=3)
# 显示图像并输出文本
for idx, item in enumerate(samples, 1):
image_path = item["image_path"]
text = item["text"]
print(f"🔹 图片 {idx}: {image_path}")
print(f"📝 对应文本: {text}\n")
try:
img = Image.open(image_path).convert("RGB")
img.show(title=f"Image {idx}")
except Exception as e:
print(f"❌ 无法打开图片: {e}")
🔹 图片 1: mid_data/extracted_images/Ghost-wall-mikal-harrsen_page_1.png 📝 对应文本: L I V I N G C O L L E C T I O N G h o s t W a l l 2 0 2 3 Design Mikal Harrsen 🔹 图片 2: mid_data/extracted_images/Cassina-LB-DETAILS_page_3.png 📝 对应文本: D E TA I L S C O L L E C T I O N 🔹 图片 3: mid_data/extracted_images/08 - OUTDOOR COLLECTION 2024_page_2.png 📝 对应文本: 3
并给出基于高维空间余弦相似度的推荐算法,通过输入个文本,向量化后找到最近的图片向量,即给出搜索结果以及相似程度,并且设置阈值来筛选无关结果。
import os
import json
import torch
import clip
from PIL import Image
from torchvision import transforms
from tqdm import tqdm
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 参数
image_folder = "mid_data/extracted_images"
mapping_json = "mid_data/text_image_mapping.json"
device = "cuda" if torch.cuda.is_available() else "cpu"
# 1. 加载模型
model, preprocess = clip.load("ViT-B/32", device=device)
# 2. 加载图像数据和路径
with open(mapping_json, "r", encoding="utf-8") as f:
pairs = json.load(f)
image_paths = [item["image_path"] for item in pairs]
images = []
for p in tqdm(image_paths, desc="预处理图像"):
try:
img = Image.open(p).convert("RGB")
img = preprocess(img)
images.append(img)
except:
print(f"跳过损坏图像: {p}")
# 3. 批量嵌入图像向量
image_input = torch.stack(images).to(device)
with torch.no_grad():
image_features = model.encode_image(image_input)
image_features /= image_features.norm(dim=-1, keepdim=True) # 归一化
# 4. 搜索函数
def search_images_by_text(query, top_k=1, threshold=0.1):
model.eval()
with torch.no_grad():
text_tokens = clip.tokenize([query]).to(device)
text_features = model.encode_text(text_tokens)
text_features /= text_features.norm(dim=-1, keepdim=True)
# 计算余弦相似度
sims = (image_features @ text_features.T).squeeze().cpu().numpy()
top_indices = np.argsort(sims)[::-1][:top_k]
best_score = sims[top_indices[0]]
if best_score < threshold:
print("❌ 无浏览结果(得分低于阈值)")
else:
print(f"✅ Top-{top_k} 匹配图像(相似度:{best_score:.4f}):")
for i in top_indices:
print(f" - 相似度: {sims[i]:.4f} -> 图像路径: {image_paths[i]}")
# 显示图像(可选)
Image.open(image_paths[i]).show()
# 5. 示例查询
query_text = "L I V I N G C O L L E C T I O N G h o s t W a l l 2 0 2 3 Design Mikal Harrsen"
search_images_by_text(query_text)
预处理图像: 100%|██████████| 70/70 [00:06<00:00, 10.64it/s]✅ Top-1 匹配图像(相似度:0.2786): - 相似度: 0.2786 -> 图像路径: mid_data/extracted_images/Cassina-PRO_2022_page_4.png


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









