






1、简介
1.1 前言
本文为实战项目,提供完整代码,帮助读者去作为实现计算机视觉任务的参考,并提出笔者在完成项目时踩过的一些坑,从数据集开始(图像增强任务不太好,要好还得找同概率分布的新数据集),到环境准备(torch-gpu如何安),再到训练过程(比如梯度爆炸,生成任务资源需求过大,预训练模型真好用等等)。本文具体针对水下图像的增强,相较于地面环境,水下图像具有更大的复杂度,可以参考笔者之前发过的一个blog——水下图像分析实战——色偏、弱光、模糊-CSDN博客
本文使用两种方法实现,其中CycleGAN,其实就是GAN的一个变种,但本文会拿它当反例——因为生成对抗神经网路本质仍然是生成问题(而不是增强任务),并且对中小实验者很不友好,大家接触人工智能领域的大概都了解,训练模型需要的计算资源不是一般人能抗的住的,我拿4张48G显存的显卡跑了整整14小时,效果也就堪堪接近增强前水平(而且还面临画质损失这一问题,之后会具体说明)。
但相反的是,如果使用预训练模型参数,则只需要轻微的微调,就可以得到很好的效果;但这并不是说明生成任务就没用,根据CycleGAN案例得出,将其用于融合图像的任务,效果大概很好,因为是从0到1。举个通俗的例子,在CycleGAN是个画师,左右摆着两张图像,画师通过临摹两张图去在面前的白纸上作画;而增强任务要干的则是,左右摆着两张画,把(正确的)好画的特征,给改到(错误的)差画上去,本质上是修改/增强。
鉴于笔者踩过的坑实在太多,后文会尽可能详细的叙述,这里先提出核心观点——CycleGAN是融合,用预训练模型去增强
1.2 现阶段综述
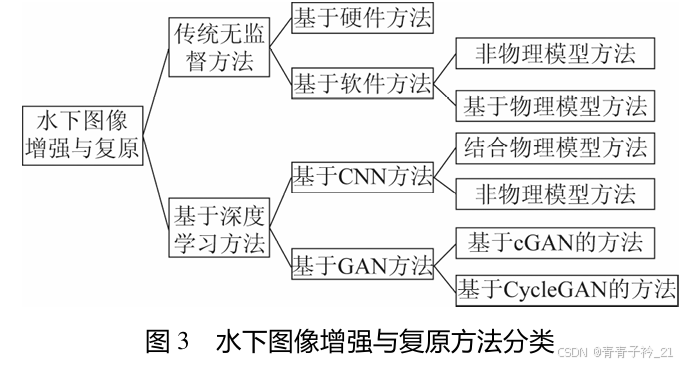
引用文章编号: 1003-0530(2020) 09-1377-13
相信看这篇blog的读者,应该没有人对传统无监督方法感兴趣,因此这里就不叙述了,本文重点关照基于深度学习方法的水下图像增强与复原任务,下面笔者简要介绍CNN与GAN,并提供别的大神的讲解链接,如果不了解的读者可以看一看。
基于CNN的方法:卷积神经网络是一种最常用的深度学习结构, 一般由多个卷积层组成,在监督信息的作用下能够有效提取从底层细节到高层语义的不同特征表达, 进而利用这些具有判别力的特征实现不同的任务。 根据是否结合水下物理模型,可以进一步将基于 CNN 的方法划分为结合物理模型的方法和非物理模型的方法。卷积神经网络(CNN)原理详解_cnn原理-CSDN博客
基于GAN的方法:生成对抗网络(Generative Adversarial Networks, GAN) 旨在通过生成模型和判别模型的互相博弈对抗学习产生较好输出的一种网络结构,常用于图像 生成、风格迁移等任务。生成模型目的在于通过网 络学习生成尽可能接近于真实图像的图像,使得判 别模型无法区分图像真假,而判别模型则用于区分是合成图像还是真实图像,如果不能欺骗判别模型,则继续对生成模型进行学习。适合小白学习的GAN(生成对抗网络)算法超详细解读_gan网络-CSDN博客
2、图像准备
2.1 开源数据集
计算机视觉领域,如果是从0到1的训练,那么数据量需求是一等一的大,即便是微调训练,数据量也是多多益善(韩信点兵,多多益善),总之数据量肯定是越多越好,质量越高越好。
机器学习任务中,训练集和预测集,可以并不是同一个数据集,原则上来讲,可以用A数据集训练,B数据集预测,但需要注意,训练数据集与预测数据集必须是同概率分布,否则效果极差!简单来讲,你拿飞机图片训练,结果让模型去增强水下任务,这肯定是不行的,对吧。
这里提供一个示例,并不一定要严格参考,如果你能搞到私密数据集那更好了,总之量和质都要好,训练效果才会好。水下图像数据集-CSDN博客
2.2 图像增强任务
如果找不到外部数据集,或者即便找到了也不够怎么办,通过数据增强,数据增强就是通过一些技术手段,如裁剪,旋转,翻转去让图片变化,人肉眼可能感觉没什么差异,但实际上,计算机因为识别的是RGB三维矩阵,计算机并不会跟着旋转什么的,如上操作,相当于直接更改三维矩阵,这就是数据增强的意义(但是如果能找到优质数据集的话,优先通过搜寻外部数据集为主,数据增强只是辅助手段)
import os
import random
from PIL import Image
from torchvision import transforms
# 输入文件夹和输出文件夹
input_folder = "../ori_picture" # 替换为你的输入文件夹路径
output_folder = "aug_picture" # 替换为你的输出文件夹路径
os.makedirs(output_folder, exist_ok=True)
# 定义增强变换
transform = transforms.Compose([
transforms.RandomResizedCrop(size=(256, 256), scale=(0.8, 1.0)), # 随机裁剪并调整到256x256
transforms.RandomRotation(degrees=(-30, 30)), # 随机旋转 -30 到 30 度
transforms.RandomHorizontalFlip(p=0.5), # 50% 概率水平翻转
transforms.RandomVerticalFlip(p=0.5), # 50% 概率垂直翻转
])
# 遍历输入文件夹的所有图片
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff')):
# 加载图片
image_path = os.path.join(input_folder, filename)
image = Image.open(image_path).convert("RGB")
# 进行数据增强
augmented_image = transform(image)
# 保存增强后的图片
output_path = os.path.join(output_folder, f"aug_2_{filename}")
augmented_image.save(output_path)
print(f"数据增强完成,所有图片已保存到 {output_folder}")
3、环境准备
这里简单说下torch-gpu的安装,网上有很多教程,这里给出一个示例链接,并不详细阐述——【超详细教程】2024最新Pytorch安装教程(同时讲解安装CPU和GPU版本)-CSDN博客
(对萌新小白的话:简单来说,torch是一个第三方库,用于科学计算用的,因为torch效率高于数组与矩阵,并且因为GPU像大货车,CPU像跑车,明显大货车拉的快,因此一般都使用torch-gpu版本。而且不要在base环境里安,因为到这个阶段,已经比较容易出现多个库互不兼容,版本冲突的情况,因此要新建环境,最坏情况就是删掉这个新环境重新配置)
值得注意的是,安装torch的时候,不要用清华源,不要用清华源,用上交源,否则无法安装gpu版本!!!清华源不知道为什么,都是cpu版本,上交源则无此问题。
-i https://mirror.sjtu.edu.cn/pypi/web/simple/ # 上交源
4、CycleGAN
4.1 代码实现
总共有四个文件,分别是主管数据预处理的dataset.py,主管模型架构的CycleGAN.py,主管训练的train.py(也是main文件),主管预测的eval.py
4.1.1 dataset.py
import os
import numpy as np
import torch
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from PIL import Image
import pandas as pd
# 数据预处理
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 归一化到 [-1, 1]
])
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, csv_path, image_folder, transform=None):
self.data = pd.read_csv(csv_path)
self.image_folder = image_folder
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
row = self.data.iloc[index]
file_name = row['File Name']
is_pure_good_dataset = row['Pure_good_data']
image_path = os.path.join(self.image_folder, file_name)
image = Image.open(image_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image, is_pure_good_dataset
# 数据加载
csv_path = './total_output/statistical_test_result.csv'
image_folder = './total_dataset'
dataset = CustomDataset(csv_path, image_folder, transform=transform)
data_loader = DataLoader(dataset, batch_size=16, shuffle=True)
4.1.2 CycleGAN.py
import torch.nn as nn
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=1, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
# ResNet blocks
*(nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
) for _ in range(6)),
nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=3),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
4.1.3 train.py
import itertools
import os
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from CycleGAN import Generator, Discriminator
from dataset import data_loader # 确保你的 dataset 脚本和此文件在同一目录下
# 自动检测设备并限制使用前四张显卡
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3" # 设置可见的 GPU 卡号
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
G_X2Y = Generator().to(device) # 从错误图片到正确图片
G_Y2X = Generator().to(device) # 从正确图片到错误图片
D_X = Discriminator().to(device) # 判别器 X(错误图片)
D_Y = Discriminator().to(device) # 判别器 Y(正确图片)
# 包装为多 GPU 模型
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
G_X2Y = nn.DataParallel(G_X2Y)
G_Y2X = nn.DataParallel(G_Y2X)
D_X = nn.DataParallel(D_X)
D_Y = nn.DataParallel(D_Y)
# 损失函数
criterion_gan = nn.MSELoss()
criterion_cycle = nn.L1Loss()
# 优化器
optimizer_G = torch.optim.Adam(itertools.chain(G_X2Y.parameters(), G_Y2X.parameters()), lr=0.0002, betas=(0.5, 0.999))
optimizer_D_X = torch.optim.Adam(D_X.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D_Y = torch.optim.Adam(D_Y.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 模型保存路径
MODEL_SAVE_DIR = "models_cycle_gan"
os.makedirs(MODEL_SAVE_DIR, exist_ok=True)
# 保存检查点
def save_checkpoint(epoch):
checkpoint_path = os.path.join(MODEL_SAVE_DIR, f"cycle_gan_epoch_{epoch}.pth")
torch.save({
'epoch': epoch,
'model_G_state_dict': G_X2Y.module.state_dict() if torch.cuda.device_count() > 1 else G_X2Y.state_dict(),
'model_G_Y2X_state_dict': G_Y2X.module.state_dict() if torch.cuda.device_count() > 1 else G_Y2X.state_dict(),
'model_D_X_state_dict': D_X.module.state_dict() if torch.cuda.device_count() > 1 else D_X.state_dict(),
'model_D_Y_state_dict': D_Y.module.state_dict() if torch.cuda.device_count() > 1 else D_Y.state_dict(),
'optimizer_G_state_dict': optimizer_G.state_dict(),
'optimizer_D_X_state_dict': optimizer_D_X.state_dict(),
'optimizer_D_Y_state_dict': optimizer_D_Y.state_dict(),
}, checkpoint_path)
print(f"Model saved at {checkpoint_path}")
LOSS_CSV_PATH = os.path.join(MODEL_SAVE_DIR, "loss_log.csv")
# 初始化损失记录文件
if not os.path.exists(LOSS_CSV_PATH):
with open(LOSS_CSV_PATH, "w") as f:
f.write("Epoch,Batch,Loss_G,Loss_D_X,Loss_D_Y\n")
# 训练主函数
if __name__ == "__main__":
total_epochs = 1600
try:
# 开始训练
for epoch in range(total_epochs):
for i, (images, _) in enumerate(data_loader):
images = images.to(device)
# Train Generator G_X2Y (坏数据 -> 好数据)
fake_Y = G_X2Y(images)
# 获取 D_Y(fake_Y) 的输出形状
real_label_Y = torch.ones_like(D_Y(fake_Y)).to(device)
fake_label_Y = torch.zeros_like(D_Y(fake_Y)).to(device)
# 计算生成器损失(让 D_Y 无法区分生成的图片与真实图片)
loss_G = criterion_gan(D_Y(fake_Y), real_label_Y)
# 计算循环一致性损失(从坏数据生成好数据后,尽可能接近原图)
loss_cycle = criterion_cycle(G_X2Y(fake_Y), images)
# 总生成器损失
loss_G_total = loss_G + 10.0 * loss_cycle
optimizer_G.zero_grad()
loss_G_total.backward()
optimizer_G.step()
# Train Discriminator D_Y
optimizer_D_Y.zero_grad()
# 判别器 D_Y 的损失(真实好数据 + 生成的好数据)
loss_D_Y = criterion_gan(D_Y(images), real_label_Y) + \
criterion_gan(D_Y(fake_Y.detach()), fake_label_Y)
loss_D_Y.backward()
optimizer_D_Y.step()
# 日志
if i % 10 == 0: # 每 10 个 batch 输出一次日志
print(
f"Epoch [{epoch}/{total_epochs}] Batch [{i}/{len(data_loader)}] "
f"Loss_G: {loss_G.item():.4f}, Loss_Cycle: {loss_cycle.item():.4f}, Loss_D_Y: {loss_D_Y.item():.4f}"
)
# 将损失记录到 CSV 文件
with open(LOSS_CSV_PATH, "a") as f:
f.write(f"{epoch+1},{i+1},{loss_G.item():.4f},{loss_cycle.item():.4f},{loss_D_Y.item():.4f}\n")
# 每 200 个 epoch 保存模型
if (epoch + 1) % 200 == 0:
save_checkpoint(epoch + 1)
except KeyboardInterrupt:
print("Training interrupted. Saving current state...")
save_checkpoint(epoch)
4.1.4 eval.py
import os
import torch
import pandas as pd
from CycleGAN import Generator
from PIL import Image
from torchvision import transforms
from tqdm import tqdm
# 设置设备并启用多 GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3" # 使用前 4 张显卡
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型加载路径
MODEL_PATH = "models_cycle_gan/cycle_gan_epoch_1000.pth" # 修改为实际保存的模型路径
OUTPUT_FOLDER = "enhanced_images" # 增强后的图片保存路径
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
# 定义模型
G_X2Y = Generator().to(device) # 从错误图片到正确图片
if torch.cuda.device_count() > 1:
G_X2Y = torch.nn.DataParallel(G_X2Y)
# 加载模型权重
checkpoint = torch.load(MODEL_PATH)
if torch.cuda.device_count() > 1:
G_X2Y.module.load_state_dict(checkpoint["model_G_state_dict"])
else:
G_X2Y.load_state_dict(checkpoint["model_G_state_dict"])
print("Model loaded successfully.")
# 定义图像预处理
transform = transforms.Compose([
transforms.Resize((256, 256)), # 调整图像大小
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化到 [-1, 1]
])
# 定义反归一化(可选)
def denormalize(tensor):
tensor = (tensor + 1) / 2 # 恢复到 [0, 1]
return tensor.clamp(0, 1)
# CSV 文件增强逻辑
def enhance_images_from_csv(csv_path, image_folder):
"""
处理 CSV 文件,增强对应的图片。
Args:
csv_path (str): CSV 文件路径,必须包含 'File Name' 和 'Is_Color_Cast' 列。
image_folder (str): 原始图片文件夹路径。
Returns:
None
"""
# 加载 CSV 文件
data = pd.read_csv(csv_path)
if "File Name" not in data.columns or "Is_Color_Cast" not in data.columns:
raise ValueError("CSV 文件必须包含 'File Name' 和 'Is_Color_Cast' 列。")
# 遍历 CSV 文件中的图片
for _, row in tqdm(data.iterrows(), total=len(data), desc="Enhancing images"):
file_name = row["File Name"]
is_color_cast = row["Is_Color_Cast"]
input_path = os.path.join(image_folder, file_name)
output_path = os.path.join(OUTPUT_FOLDER, file_name)
# 如果图片不存在,跳过
if not os.path.exists(input_path):
print(f"Warning: File {input_path} not found. Skipping...")
continue
# 如果是正确图片 (Is_Color_Cast=0),跳过增强
if is_color_cast == 0:
print(f"Skipping correct image: {file_name}")
# continue
# 加载图像
image = Image.open(input_path).convert("RGB")
image_tensor = transform(image).unsqueeze(0).to(device)
# 使用生成器进行增强
with torch.no_grad():
enhanced_image_tensor = G_X2Y(image_tensor).squeeze(0).cpu()
enhanced_image_tensor = denormalize(enhanced_image_tensor) # 反归一化到 [0, 1]
# 保存增强后的图像
enhanced_image = transforms.ToPILImage()(enhanced_image_tensor)
enhanced_image.save(output_path)
print(f"Enhanced image saved: {output_path}")
if __name__ == "__main__":
# 设置 CSV 和图片文件夹路径
CSV_PATH = '../first_question/output/statistical_test_result.csv'# 修改为你的 CSV 文件路径
IMAGE_FOLDER = "../ori_picture" # 修改为你的图片文件夹路径
# 运行增强
enhance_images_from_csv(CSV_PATH, IMAGE_FOLDER)
print("Enhancement completed.")
4.2 原理简析
与传统GAN相比,CycleGAN增加双向映射与循环一致损失。
-
双向映射(两个生成器和两个判别器):
- 一个生成器将源域(Domain A)的图像转换为目标域(Domain B)的图像,另一个生成器将目标域的图像转换回源域的图像。
- 两个判别器分别判断源域和目标域的图像是否逼真。
-
循环一致性损失(Cycle Consistency Loss):
- 这是CycleGAN最关键的创新之一。通过要求图像经过两个生成器的转换后,能“回到原点”,也就是源域的图像经过目标域生成器转换,再经过源域生成器转换,最终能够恢复到原始的源域图像。这种循环一致性要求网络不仅生成真实的图像,还要保证生成的图像在经过转换后可以准确恢复原图。
但是回到我们的目的,我们是进行图像增强任务,而不是融合任务,我们希望坏图片学习好图片,但不希望好图片学习坏图片。
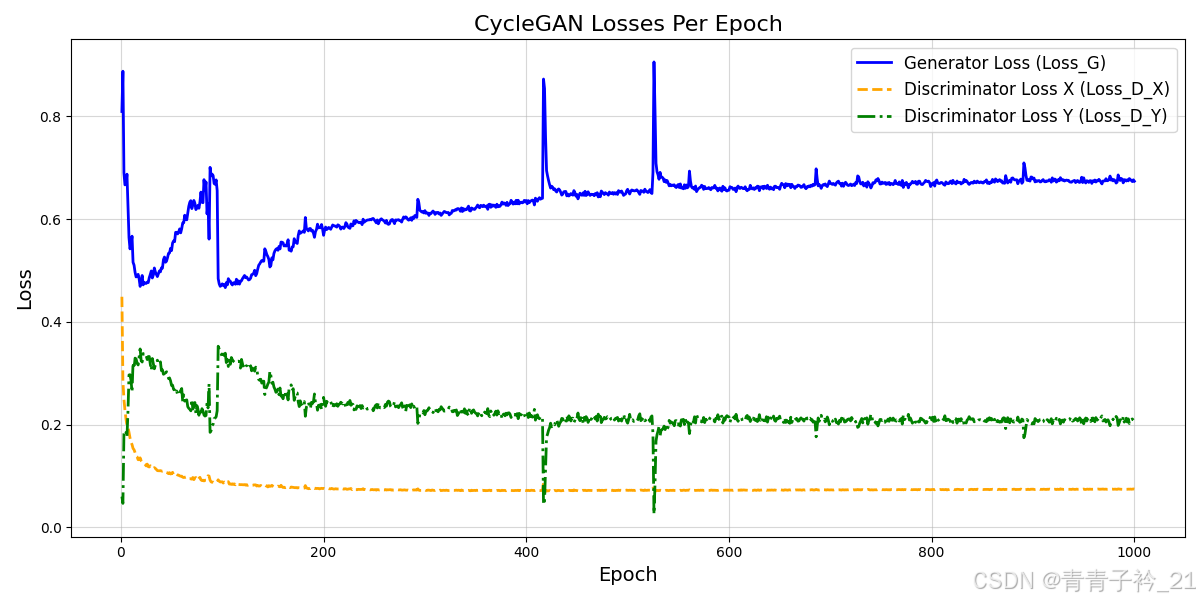
与传统的深度学习但loss不同,CycleGAN提供了三个损失函数,生成器损失,判别器X与判别器Y损失,可以看出,会有些时段,容易出现梯度骤变(这种骤变并不一定是好的,很有可能是生成器生成了某个特征契合判别器,但这种并不是我们想要的)。
4.3 画质损失
因为CycleGAN有个好处,是不论各种图片分辨率如何,都能将其统一训练与预测,但这并不是基于模型架构方面,而是在dataset.py里,对全部图片进行预压缩,在实际任务中,即上述loss收敛的时候,能明显看出“坏图片”学习了“好图片”的特征,但画质反而更模糊了(但这种模糊不是统计意义上的模糊,仅仅是肉眼模糊),因为画质反而大不如前。
既然如此,有读者可能想象,那就把画质设置高么(dataset.py里有参数专门控制分辨率的),但这样训练的成本又是很高的,这就不得不再提4张48G共192G的显存跑了14H。
4.4 生成斑点
相较于别的深度学习方法,CycleGAN容易出现斑点问题,不仅仅是我的实验这样,下面是一篇论文里的对比实验,来源于论文——深度学习驱动的水下图像增强与复原研究进展_丛润民。

可以看出,Water CycleGAN容易出现光斑(我那个光斑图像就不献丑了,因为画质比较低),此原理不明(本人能力不够,万望谅解)。
5、UNet
这里强调的是,并不是UNet本身多好(但其实在水下任务也不错),而是预训练模型好,不用从零开始训练。预训练模型很适合小型科研工作者,而且效果碾压我上面那个训练出的结果(就是,不要头铁,别从0开始炼丹,拥有太上老君丹炉的仙君除外)
5.1 代码实现
5.1.1 安装预训练参数
可以人为安装,也可以在代码里设置自动安装,这里采取自动安装,示例如下:
import torch
import torchvision.models as models
# 加载预训练的ResNet50
model = models.resnet50(pretrained=True)
# 查看模型结构
print(model)pretrained=True会自动下载并加载ResNet50的预训练权重(权重会从PyTorch官方的模型库中下载)。
5.1.2 模型训练
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
from torchvision.models import vgg16
# 数据集定义
class ImageDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.image_files = os.listdir(root_dir)
self.transform = transform
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.image_files[idx])
img = Image.open(img_path).convert("RGB")
if self.transform:
img = self.transform(img)
return img, img_path
# ---------------------------
# 2. 模型架构
# ---------------------------
class ResNetBlock(nn.Module):
def __init__(self, in_channels):
super(ResNetBlock, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1),
nn.InstanceNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1),
nn.InstanceNorm2d(in_channels),
)
def forward(self, x):
return x + self.block(x) # Residual connection
class Generator(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(Generator, self).__init__()
self.initial = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=7, padding=3),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True),
)
self.res_blocks = nn.Sequential(*[ResNetBlock(64) for _ in range(6)])
self.final = nn.Sequential(
nn.Conv2d(64, out_channels, kernel_size=7, padding=3),
nn.Tanh(),
)
def forward(self, x):
return x + self.final(self.res_blocks(self.initial(x))) # Residual enhancement
class PatchGAN(nn.Module):
def __init__(self, in_channels=3):
super(PatchGAN, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, kernel_size=4, padding=1),
)
def forward(self, x):
return self.model(x)
# ---------------------------
# 3. 损失函数
# ---------------------------
class PerceptualLoss(nn.Module):
def __init__(self):
super(PerceptualLoss, self).__init__()
vgg = vgg16(pretrained=True).features
self.feature_extractor = nn.Sequential(*list(vgg[:16])).eval()
for param in self.feature_extractor.parameters():
param.requires_grad = False
def forward(self, x, y):
features_x = self.feature_extractor(x)
features_y = self.feature_extractor(y)
return nn.functional.l1_loss(features_x, features_y)
# 训练函数
def train(dataloader, epochs, device, lr=1e-4, lambda_rec=100, lambda_percep=10):
generator = Generator().to(device)
discriminator = PatchGAN().to(device)
# 损失函数
adversarial_loss = nn.BCEWithLogitsLoss()
reconstruction_loss = nn.L1Loss()
perceptual_loss = PerceptualLoss().to(device)
# 优化器
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
for epoch in range(epochs):
for i, (images, paths) in enumerate(dataloader):
images = images.to(device)
# 更新判别器
optimizer_D.zero_grad()
fake_images = generator(images).detach()
real_validity = discriminator(images)
fake_validity = discriminator(fake_images)
d_loss = (adversarial_loss(real_validity, torch.ones_like(real_validity)) +
adversarial_loss(fake_validity, torch.zeros_like(fake_validity))) / 2
d_loss.backward()
optimizer_D.step()
# 更新生成器
optimizer_G.zero_grad()
fake_images = generator(images)
fake_validity = discriminator(fake_images)
g_loss = (adversarial_loss(fake_validity, torch.ones_like(fake_validity)) +
lambda_rec * reconstruction_loss(fake_images, images) +
lambda_percep * perceptual_loss(fake_images, images))
g_loss.backward()
optimizer_G.step()
# 日志打印
if i % 10 == 0:
print(f"[Epoch {epoch}/{epochs}] [Batch {i}/{len(dataloader)}] "
f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]")
if epoch % 20 == 0:
# 保存模型和生成结果
torch.save(generator.state_dict(), f"./get_weights/generator_epoch_{epoch}.pth")
torch.save(discriminator.state_dict(), f"./get_weights/discriminator_epoch_{epoch}.pth")
if __name__ == "__main__":
# 数据路径
root_dir = "./total_dataset"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
])
dataset = ImageDataset(root_dir, transform=transform)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4)
# 启动训练
train(dataloader, epochs=200, device=device)
5.1.3 模型预测
import os
import torch
from torchvision import transforms
from PIL import Image
from torchvision.transforms import functional as F
from train import Generator # 导入 Generator 模型定义
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载训练好的生成器模型
model = Generator(in_channels=3, out_channels=3) # 确保输入/输出通道与训练一致
model.load_state_dict(torch.load("./get_weights/generator_epoch_120.pth")) # 替换为你的模型路径
model.eval() # 切换到推理模式
model.to(device)
# 定义预处理操作
preprocess = transforms.Compose([
transforms.Resize((256, 256)), # 调整大小,与训练时一致
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 确保归一化与训练时一致
])
# 定义输入和输出文件夹
input_folder = "ori_picture" # 输入图片文件夹路径
output_folder = "enhanced_pictures" # 输出图片文件夹路径
os.makedirs(output_folder, exist_ok=True) # 确保输出文件夹存在
# 处理文件夹中的所有图片
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff')): # 支持的图片格式
image_path = os.path.join(input_folder, filename)
# 加载图片并进行预处理
image = Image.open(image_path).convert("RGB") # 确保图像为 RGB 格式
input_tensor = preprocess(image).unsqueeze(0).to(device) # 添加 batch 维度
# 模型推理
with torch.no_grad():
enhanced_tensor = model(input_tensor)
# 后处理并保存增强后的图像
enhanced_tensor = enhanced_tensor.squeeze(0).cpu() # 去掉 batch 维度
enhanced_image = F.to_pil_image((enhanced_tensor * 0.5 + 0.5).clamp(0, 1)) # 反归一化到 [0, 1]
# 保存增强后的图片
output_path = os.path.join(output_folder, filename)
enhanced_image.save(output_path)
print(f"增强后的图片已保存为 {output_path}")
print("所有图片增强完成!")
5.2 UNet架构概述
UNet是一种常用于图像分割的神经网络,其结构特点是对称的编码器和解码器。编码器部分逐渐下采样图像以提取特征,解码器部分则逐步恢复图像的空间分辨率。UNet的独特之处在于其跨层连接(skip connections),即在编码器和解码器之间有跳跃连接,使得低层的细节信息能够直接传递到高层,帮助网络更好地恢复图像细节。
5.3 在水下图像增强中的应用
在水下环境中,图像经常遭遇色偏(由于水中的光散射)、弱光(因为水下环境的光照较暗)、模糊(由于水流、运动等因素)等问题,安利一下本人的另一个blog(doge)——水下图像分析实战——色偏、弱光、模糊-CSDN博客。
UNet可以在以下几个方面帮助增强水下图像:
-
色偏校正:通过学习不同光照条件下的色彩特征,UNet可以从图像中提取出颜色信息,进行色偏修正,使图像恢复正常色彩。
-
弱光增强:UNet能够在低光环境下学习图像的光照分布,并进行增强,增加图像的亮度和对比度,恢复更多细节。
-
去模糊:通过深度学习模型,UNet能够去除水下图像中的运动模糊或光学模糊,使得图像更加清晰。
一个优质的图像增强,应该如下所示,上图有些模糊(即高斯模糊),下图成功去掉模糊,与弱光。(但这并不是常态哈哈,这是挑了一个效果最好的)


6、一些炼丹小贴士
6.1 定期保存模型权重
不要等训练结尾再保存,说不定中间结果比之后强,每隔一段时间就保存一下,还能避免模型崩溃导致无结果
6.2 在测试代码的时候就加上loss记录
不要等最后再搞loss,那时候你已经搞不了了,再训练有需要大量时间与资源,在测试的时候就输出loss的csv文件(我是喜欢用csv文件保存的)
6.3 学习率不是越小越好
原则来说,学习率低最多是训练比较慢,但不知道为什么,学习率过低,反而loss一直很高,有可能一直处于欠拟合的状态
6.4 每批次图片越多越好
batch_size 越大,模型抑制过拟合能力越强,当然,得显存带的动
6.5 不要尝试用错误图片的正确特征去训练
我最开始想,有些图片,并不是完全坏的,比如仅仅色偏,但不弱光,不模糊,就在想能不能用这个图片去训练模糊与弱光的图片,答案:不行。结果就是画质的确环节色偏这一问题了,但学习到弱光与模糊了。
6.6 初始化放缩
一般来说,图像任务大多会有放缩/归一化的操作,确保归一化没问题,如果归一化错误,后续会出结果,但那个结果很难看(我那个最开始一堆黑红图片,完全看不出和原图片的关系),即能出解不代表正确。
看到这里了,如果觉得有用的话,还请麻烦点个赞,谢谢支持☺️

















 6551
6551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









