






针对列表页+详情页这种模式,对链接抽取进行逻辑限定。可以获取到 start_urls 页面的所有超链接,然后通过限定条件进行逻辑限定。
案例:爬取豆瓣新书的书名,价格,评分
核心的爬虫代码
import re
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'example'
# allowed_domains = ['example.com']
start_urls = ['https://book.douban.com/']
rules = (
Rule(LinkExtractor(allow=(r"https://book.douban.com/subject/\d+/\?icn=index-latestbook-subject")), callback='parse_item', follow=False),
)
def parse_item(self, response):
self.logger.info(f"爬取的url:{response.url}")
# 在这里定义解析页面的逻辑
# 可以从 response 中提取数据
html=response.text
# 获取书名,价格,评分,
title=response.xpath("//h1/span/text()").get()
price=re.findall("<span class=\"pl\">定价:</span>(.*?)<br/>",html)
if price:
price=price[0] if "元" in price[0] else price[0]+"元"
else:
price="未知"
rating_num=response.xpath("//div[@class='rating_self']/text()").get()
rating_num=re.findall("<strong class=\"ll rating_num \" property=\"v:average\"> (.*?) </strong>",html)[0]
print(title,price,rating_num)
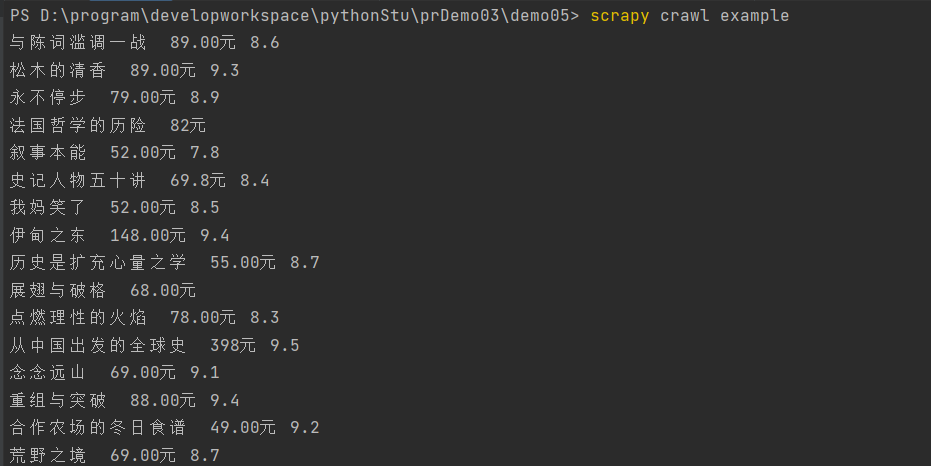
结果:















 5559
5559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









