









目录
文章声明:非广告,仅个人体验。
参考文献::(https://www.aspiringcode.com/content?id=17143993655710&uid=d73bdbcebb024e5e939e6caf5f693ed3)
个人智能聊天助手-即刻轻松拥有
本地搭建大语言模型,随时随地可以使用的智能聊天助手,本文包括论文原理讲解和代码复现
论文讲解
- 论文题目:GLM: General Language Model Pretraining with Autoregressive Blank Infilling(基于自回归词块填空的通用语言模型预训练)
该论文提出了一个名为ChatGLM的模型,可以提供像ChatGPT一样的对话功能,是很好的个人聊天助手,针对中文的优化很好。
ChatGLM是由清华大学自然语言处理实验室 (THUDM) 开发的大型语言模型,支持中英双语问答。它基于通用语言模型 (GLM) 架构构建,拥有62亿参数,在对话流畅度、部署门槛低等方面表现出色。
主要特点:
- 对话流畅: ChatGLM能够进行多轮对话,并生成内容丰富、语法正确的文本。
- 支持中英双语: ChatGLM支持中英文问答,可满足不同语言用户的需求。
- 强大性能:ChatGLM2-6B 升级版在性能、上下文长度、推理效率等方面均有显著提升。
应用场景:
- 虚拟助手: ChatGLM可作为虚拟助手,帮助用户完成日程管理、信息查询等任务。
- 创作辅助: ChatGLM可用于辅助创作,为用户提供灵感和素材。
- 教育问答: ChatGLM可用于构建教育问答系统,为学生提供个性化的学习辅导。
背景介绍
近年来,各种预训练架构不断涌现,例如用于理解语言的编码模型 (BERT)、用于生成文本的自体回归模型 (GPT) 以及可用于多种任务的编码器-解码器模型 (T5)。然而,这些预训练框架没有一种能同时在三大领域(自然语言理解 (NLU)、无条件生成和条件生成)的所有任务上取得最佳表现。
正是为了解决这一挑战,清华大学提出了基于自体回归词块填空的通用语言模型 (GLM)。GLM 通过加入二维位置编码以及允许任意顺序预测词块,改进了词块填空预训练方法,在 NLU 任务上相比 BERT 和 T5 取得了性能提升。同时,GLM 可以通过改变词块数量和长度来针对不同类型的任务进行预训练。
在涵盖 NLU、条件生成和无条件生成等广泛任务的测试中,GLM 在相同模型大小和数据量的情况下均优于 BERT、T5 和 GPT,并且使用比 BERT-Large 少 1.25 倍参数的预训练模型实现了最佳性能。这表明了 GLM 在适应不同下游任务方面的泛化能力。
论文方法
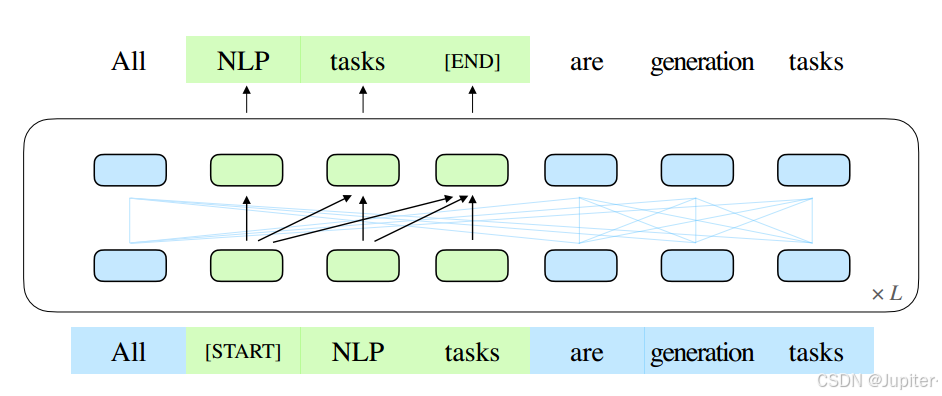
GLM的工作原理,GLM 是一种生成式语言模型,其目标是生成自然语言文本。在这个图中,绿色部分代表了文本中被隐藏的部分,也就是被屏蔽的文本片段。而 GLM 则会自动地逐步生成这些被屏蔽的文本内容。这个过程是自回归的,意味着模型会逐个单词或单词片段地生成文本,每一步的生成都依赖于之前已生成的内容。这种自回归的方式使得模型能够更好地理解语境和结构,并生成更合理、更连贯的文本。
预训练目标
自回归词块填空
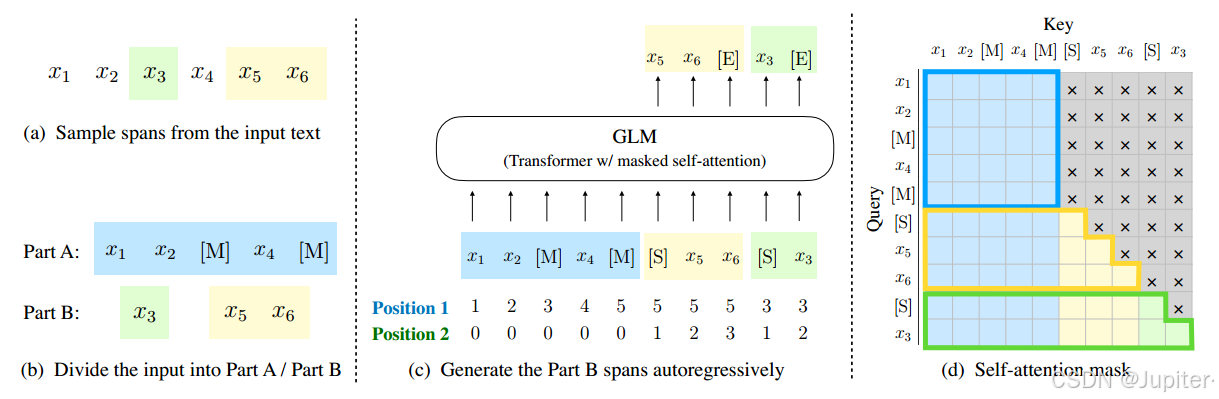
GLM(Generative Language Model)的预训练过程
-
(a) 原始文本为 [x1; x2; x3; x4; x5; x6],这里的 x1 到 x6 是文本中的单词或单词片段。在这个阶段,从原始文本中随机选择了两个片段,分别是 [x3] 和 [x5; x6]。
-
(b) 在图a的基础上,将所选的片段用 [M] 替换,同时在图b的部分将被选中的片段重新排列。
-
© 在预处理的基础上,GLM 开始自回归地生成图b中的 Part B。每个片段都会在前面加上 [S] 作为输入,后面加上 [E] 作为输出。同时,2D 位置编码表示了片段间和片段内的位置关系。
-
(d) 自注意力掩码显示了哪些区域被屏蔽掉。灰色区域表示被屏蔽的区域。Part A 中的标记可以自我关注(蓝色边框),但不能关注 Part B。而 Part B 中的标记可以关注 Part A 和自身在 B 中的前驱(黄色和绿色边框对应两个片段)。其中,[M] 代表 [MASK],[S] 代表 [START],[E] 代表 [END]。
这些步骤结合了预训练过程中的关键要素,包括文本选择、替换和重排、自回归生成以及自注意力机制的应用。这些步骤的设计有助于提高模型对语言结构的理解和生成能力,从而提高了模型在各种自然语言处理任务中的性能表现。
多任务预训练
在前文中,作者提到了 GLM 模型,该模型在处理自然语言理解(NLU)任务时,会屏蔽短文本片段进行预训练。但是,作者想要训练一个单一的模型,能够同时处理 NLU 和文本生成任务。因此,他们提出了一种多任务预训练的方法,在该方法中,除了之前的屏蔽填充(blank infilling)目标外,还引入了生成更长文本的目标。
具体地,他们提出了两个新的目标:
- 文档级别目标:从原始文本中随机抽样一个长度在原始长度的50%到100%之间的文本片段,目标是生成更长的文本。
- 句子级别目标:限制被屏蔽的文本片段必须是完整的句子。从原始文本中随机抽样多个句子,以覆盖原始标记的15%。这个目标适用于序列到序列(seq2seq)任务,其预测结果通常是完整的句子或段落。
模型架构
GLM 使用了 Transformer 模型,但对其架构进行了几处修改。
调整了层归一化(layer normalization)和残差连接(residual connection)的顺序,这是为了避免在大规模语言模型中出现数值错误。
使用了一个单一的线性层进行输出的标记预测。
将 ReLU 激活函数替换为 GeLU(Gaussian Error Linear Units)激活函数。
2D 位置编码
在自回归填充任务中,模型需要预测被屏蔽的文本片段。为了使模型能够理解文本中的位置信息,通常会使用位置编码。在传统的 Transformer 模型中,通常使用 1D 位置编码来表示标记的位置,但对于自回归填充任务,需要更复杂的位置编码方法来处理屏蔽文本片段的位置信息。
作者提出了 2D 位置编码的概念,其核心思想是为每个标记引入两个位置 id,以捕捉不同级别的位置信息:
- 第一个位置 id 表示标记在被损坏的文本中的位置。对于被屏蔽的文本片段,它对应于相应的 [MASK] 标记的位置。这个位置 id 帮助模型理解文本中被屏蔽的部分的整体位置。
- 第二个位置 id 表示标记在其所在文本片段中的相对位置。对于 Part A 中的标记,其第二个位置 id 为 0,因为它们是片段的起始标记。对于 Part B 中的标记,其位置 id 从 1 开始递增,直到片段的长度。这个位置 id 帮助模型理解文本片段内部的相对位置关系。
- 为了实现这种编码,作者使用了两个可学习的嵌入表,分别用于将两个位置 id 投影到两个不同的向量空间。然后,这两个向量与输入标记的嵌入相加,从而将位置信息融入到模型的输入表示中。
微调 GLM
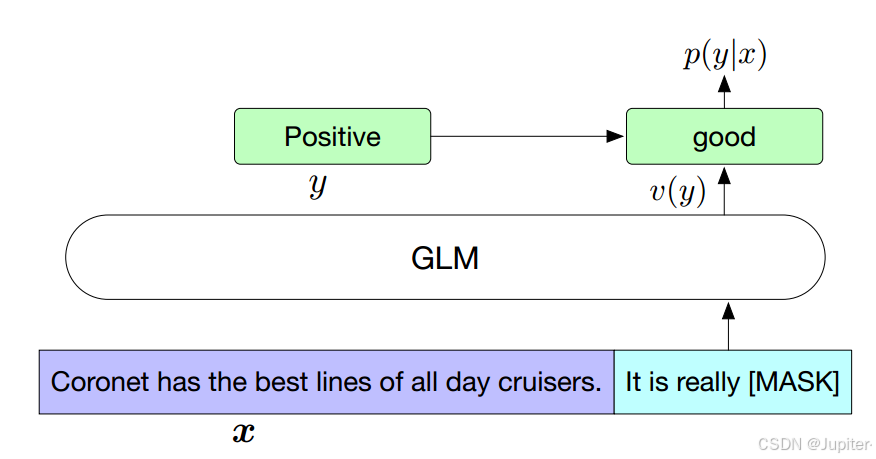
传统方法:
-
通常,对于下游的 NLU 任务,一个线性分类器将预训练模型生成的序列或标记表示作为输入,并预测正确的标签。
这种做法与生成式预训练任务不同,导致了预训练和微调之间的不一致性。
重构 NLU 分类任务: -
作者采用了一种新的思路,将 NLU 分类任务重新构建为空白填充的生成任务,这是 PET(Pattern Exploiting Training)方法的一种扩展。具体地,给定一个标记化的示例 (x; y),通过一个包含单个屏蔽标记的模式,将输入文本 x 转换为一个填充题 c(x)。这个模式用自然语言书写,以表示任务的语义。例如,情感分类任务可以被构建为 “{SENTENCE}. It’s really [MASK]”。候选标签 y 属于标签集 Y,也被映射为填充题的答案,称为 “verbalizer” v(y)。在情感分类中,“positive” 和 “negative” 被映射为 “good” 和 “bad”。在这个框架下,给定文本 x 的条件概率 p(y|x) 被定义为填充题答案 v(y) 给定填充题 c(x) 的概率的条件概率。
-
最后,作者使用交叉熵损失对 GLM 进行微调。对于文本生成任务,给定上下文构成了输入的 Part A,末尾附加了一个屏蔽标记。模型自回归地生成 Part B 的文本。
实验结果
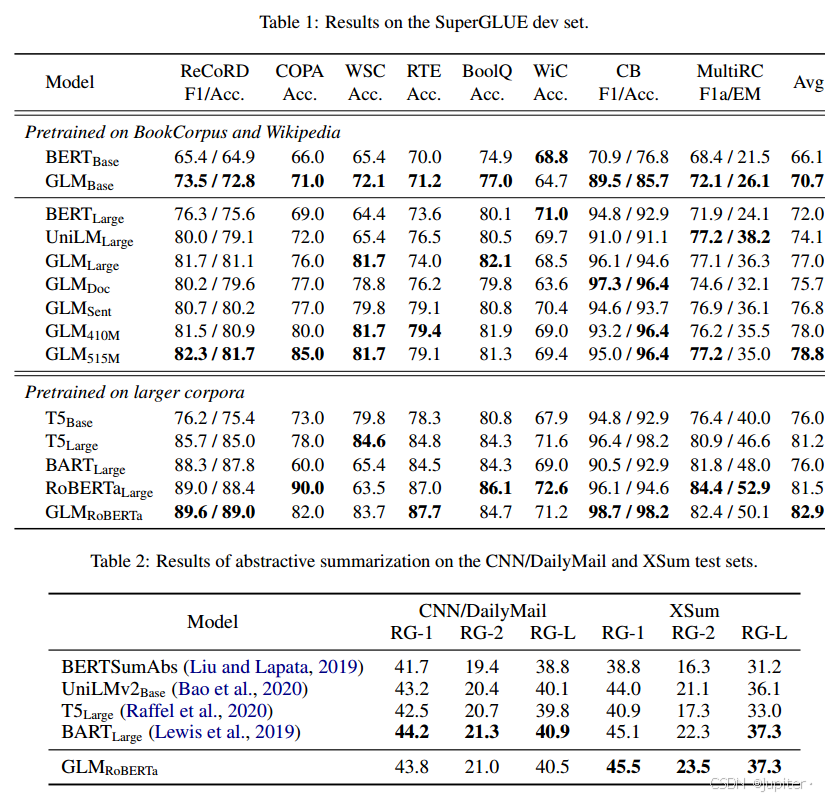
在 Table 1 中,展示了实验结果。在相同数量的训练数据下,GLM 在大多数任务上都比 BERT 表现更好,无论是基础还是大型的架构。唯一的例外是 WiC(词义消歧)任务。平均而言,GLMBase 比 BERTBase 的得分高出了 4.6%,而 GLMLarge 比 BERTLarge 高出了 5.0%。这清楚地展示了我们的方法在自然语言理解任务中的优势。在 RoBERTaLarge 的设置下,GLMRoBERTa 仍然能够在基准线上取得改进,但幅度较小。具体来说,GLMRoBERTa 比 T5Large 表现更好,但却只有后者的一半大小。我们还发现,BART 在具有挑战性的 SuperGLUE 基准上表现不佳。我们推测这可能是由于编码器-解码器架构和去噪序列到序列目标的低参数效率所导致的。
Table 2展示了在更大语料库上训练的模型的结果。GLMRoBERTa能够在两个生成任务上达到与其他预训练模型相匹配的性能水平。GLMSent的表现可能比GLMRoBERTa还要好,而GLMDoc的表现略逊于GLMRoBERTa。这表明,针对文档级别的目标,即教导模型扩展给定的上下文,对于条件生成并不太有帮助,而条件生成的目标是从上下文中提取有用信息。将GLMDoc的参数增加到410M可在两个任务上获得最佳性能。在更大的语料库上训练的模型的结果显示在表2中。GLMRoBERTa可以达到与seq2seq BART模型相匹配的性能,并且胜过T5和UniLMv2。
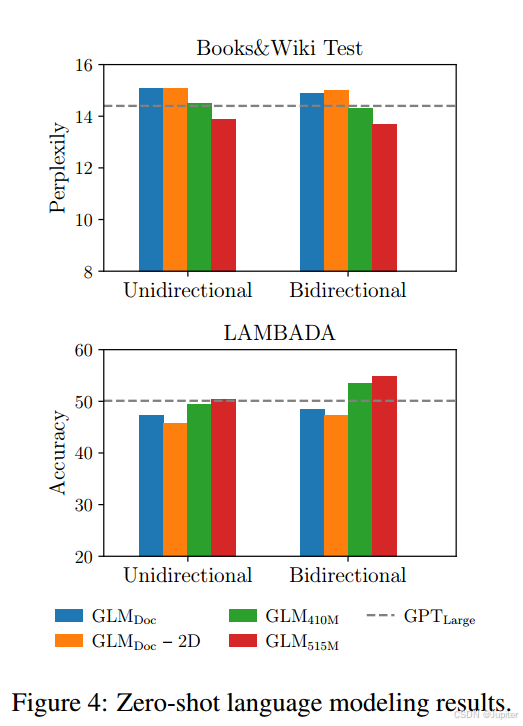
- 图 4 展示了实验结果。所有模型都在零样本设置下进行评估。由于 GLM 学习了双向注意力,评估了在上下文使用双向注意力编码的情况下的 GLM 的性能。在预训练期间没有生成目标的情况下,GLMLarge 无法完成语言建模任务。具有相同数量参数的情况下,GLMDoc 的表现比 GPTLarge 差。这是因为 GLMDoc 也优化了空白填充的目标。将模型的参数增加到 410M(GPTLarge 的1.25倍)会使性能接近 GPTLarge。GLM515M(GPTLarge 的1.5倍)可以进一步胜过 GPTLarge。在相同数量参数的情况下,使用双向注意力编码上下文可以提高语言建模的性能。在这种情况下,GLM410M 的表现优于 GPTLarge。这是 GLM 相对于单向 GPT 的优势所在。我们还研究了 2D 位置编码对长文本生成的贡献。我们发现,去除 2D 位置编码会导致语言建模的准确性降低和困惑度增加。
代码复现
环境配置
基本的环境配置要点如下
最好使用显卡的电脑,如果没有显卡,chatglm响应较慢。(本人使用1660 Ti (6G)显卡,大家可以参考此配置)
电脑能够访问github,并安装git工具,方便下载代码。(如果不能访问,附件中有我整理的代码包,即开即用。)
安装好编程语言工具python,可以直接安装,也可以使用Conda环境
1、在Windows下需要配置有Python环境,建议使用Conda环境。
# 创建一个chatglm环境,方便后续安装包
conda create –n chatglm python=3.8.5
# 激活chatglm环境,注意安装包一定要激活环境安装
activate chatglm
2、拉取官方的代码,如果不能拉取代码,可我整理好的附件使用。
git clone https://github.com/THUDM/GLM.git
拉取代码后的目录结构如下所示,如果不能正常拉取代码,可以使用本文附件的代码。
3、安装代码运行所需要的包(已成功下载官方代码或者下载了我整理好的代码包),此过程需要等待一段时间。
pip install -r requirements.txt
模型下载
需要访问网站https://huggingface.co,下载ChatGLM的权值,网址如下:
https://huggingface.co/THUDM/chatglm-6b/tree/main
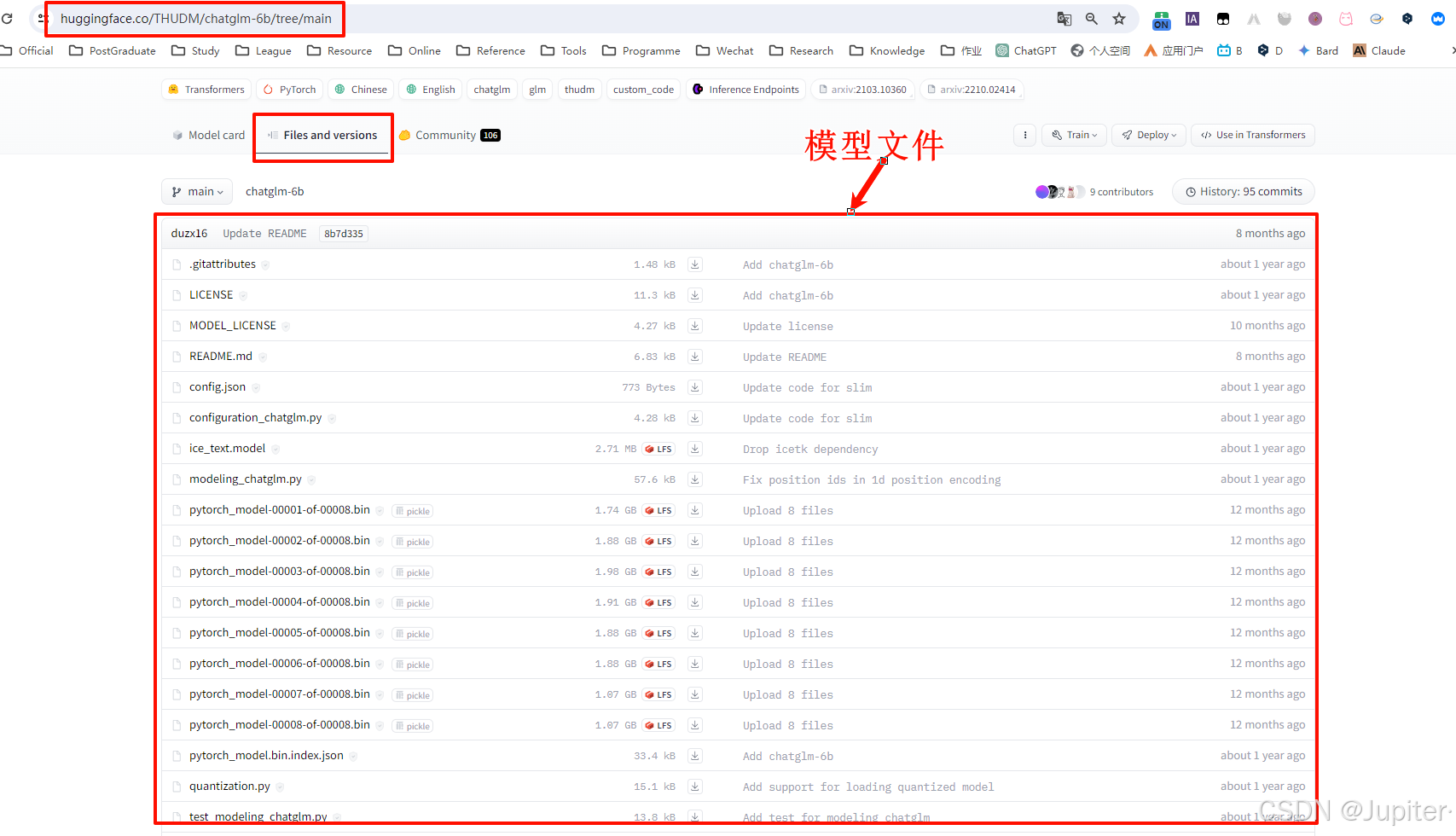
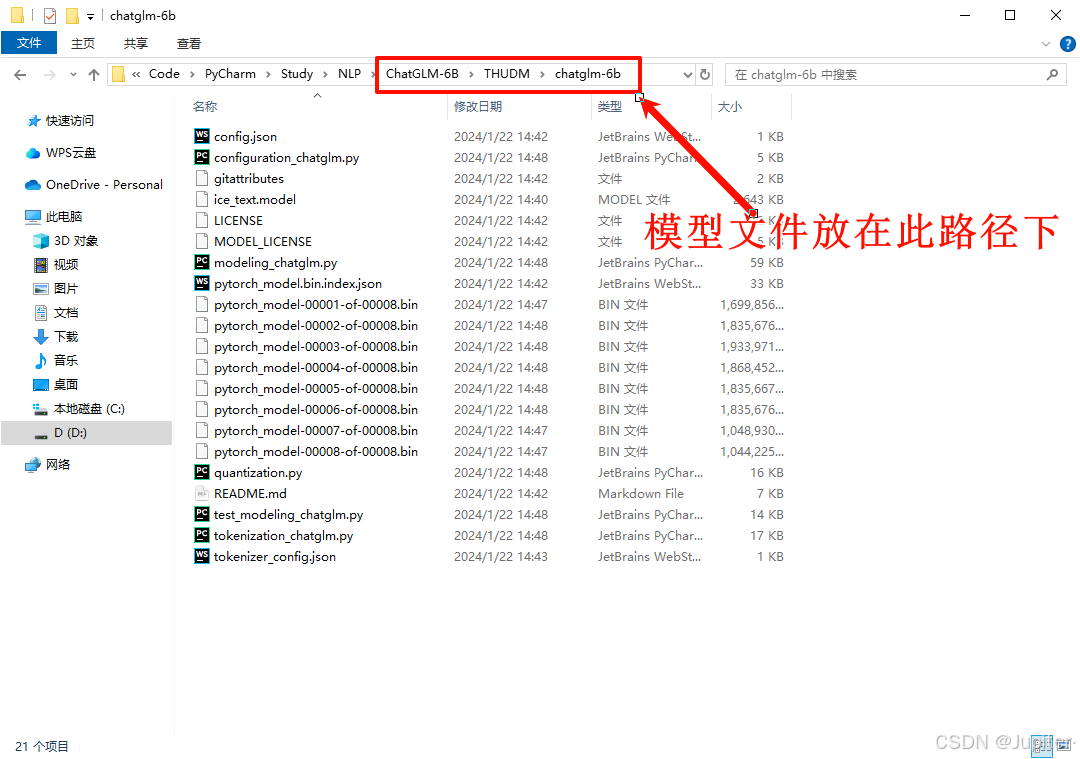
下载好的模型文件需要放在代码包的THUDM\chatglm-6b路径下,这个路径也可以自行选择。
D:\Code\PyCharm\Study\NLP\ChatGLM-6B\THUDM\chatglm-6b
启动ChatGLM
做好以上准备工作后,可以准备启动ChatGLM模型,在代码文件中共有4个可以启动模型的文件,亲测后建议使用web_demo2.py文件
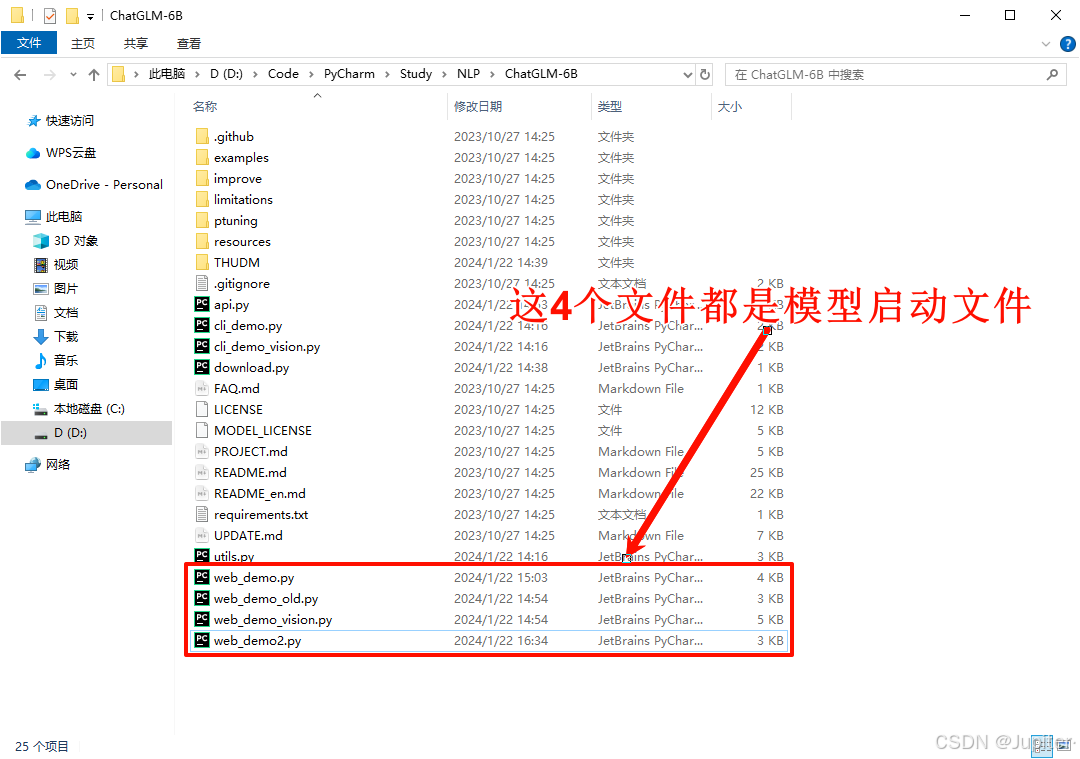
不能直接运行web_demo2.py,否者会报错。报错原因是此文件应该在控制台中启动
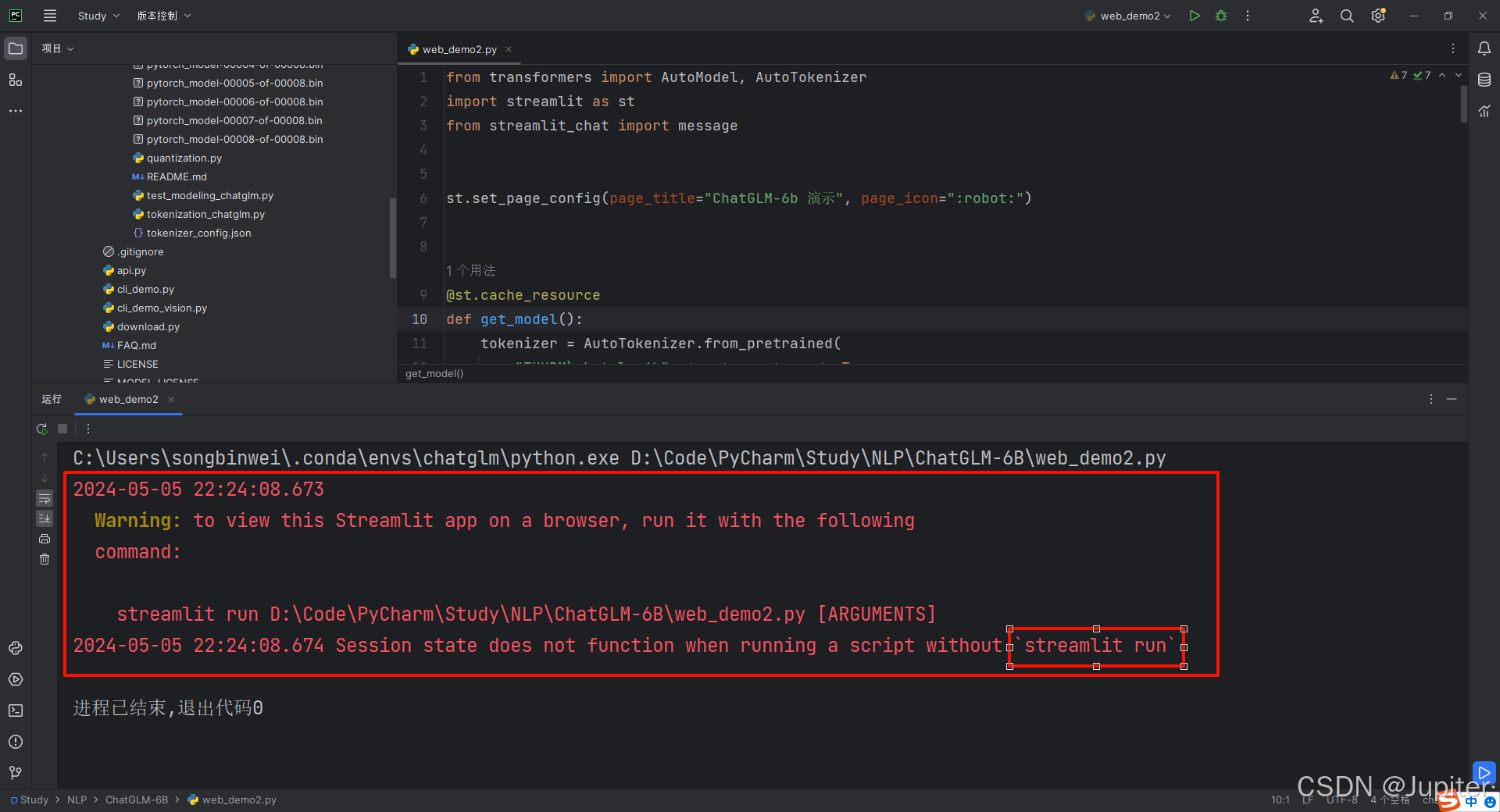
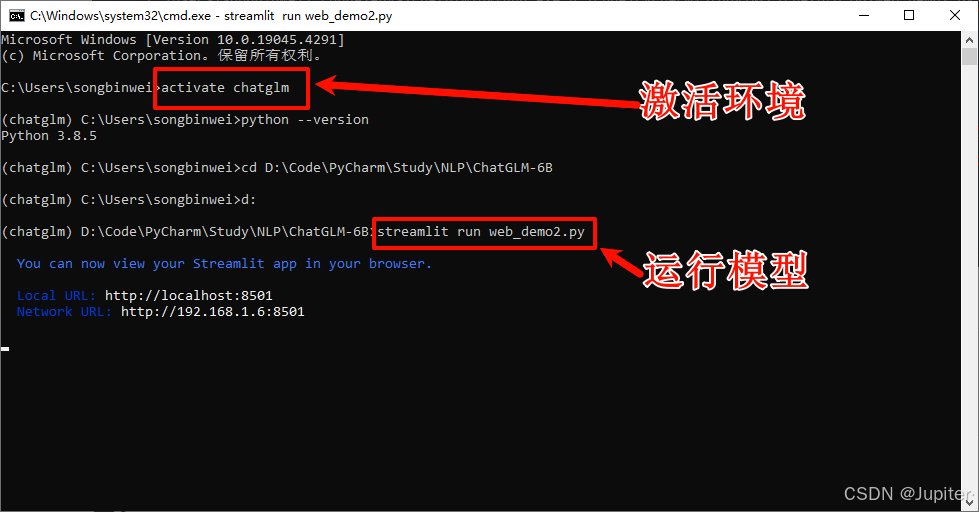
需要激活环境,并再控制台启动。
# 激活chatglm环境,注意安装包一定要激活环境安装
activate chatglm
# 运行模型
streamlit run web_demo2.py
成功启动模型后,会自动打开浏览器的页面,如下图所示。
对话效果
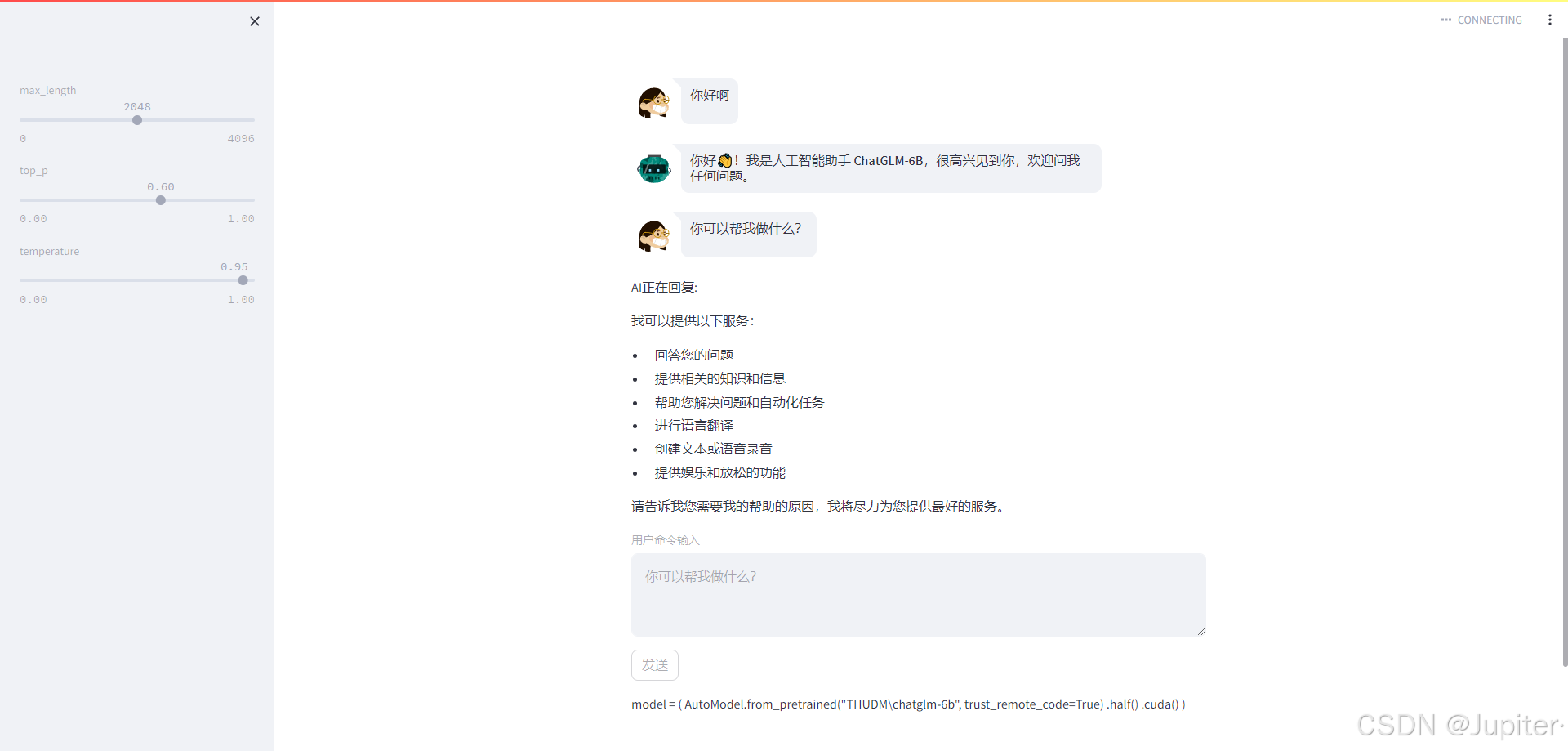
如下图所示,已经成功启动ChatGLM,并可以与其进行对话。
总结
ChatGLM是一个很符合中国人的一个大语言模型,并且针对中文的问答效果优化很好。大家可以不妨动手试试,部署在个人电脑上体验一下,轻松拥有一个智能对话助手。
参考文献:需要本文的详细复现过程的项目源码、数据和预训练好的模型可从该地址处获取完整版:(https://www.aspiringcode.com/content?id=17143993655710&uid=d73bdbcebb024e5e939e6caf5f693ed3)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









