






文章目录
什么是Spark
Spark
Spark是什么
如果你关注过大数据领域的任何事情,甚至做任何互联网有关的工作,你会发现Spark这个词四处都是:机器学习需要Spark,数据流传输需要Spark,ETL也需要Spark。
有没有想过,Spark到底是什么?居然能够得到这种程度的关注?
用最简单的语言去描述Spark的话,听起来或许有点百度百科:
Spark是一个通用的分布式数据处理引擎。
上面这句话听起来或许很抽象,我们一个词一个词的来解释
通用:通用指的是Spark可以做很多事情。刚刚我们提到过的,包括机器学习,数据流传输,交互分析,ETL,批处理,图计算等等等等都是Spark可以做到的。甚至可以说,你需要用数据实现的任何事情,你都可以用Spark试试看。
分布式:指的是Spark处理数据的能力是建立在许多机器上的,是可以和分布式的存储系统对接的,是可以做横向扩展的(简单点说就是电脑越多,能力越大)
引擎:所谓引擎,说的就是Spark自己不会存储数据,它就像实体的机械引擎一样,会将燃料(对Spark来说是数据)转化成使用者需要的那种形式——例如驱动汽车,再例如得到一个需要的目标结论。但无论如何,巧妇难为无米之炊,没数据是万万不行的。

Spark的历史
Spark是个和Hadoop血缘很深的东西,从最开始的设计,Spark就是为了代替MapReduce这个笨重的算法的。我们之前说过,MapReuce是一个很重型的计算工具。究其原因,一个是因为MapReduce有大量的磁盘IO(读写电脑磁盘)工作要做,这磁盘IO可以说是相当花时间,再加上一旦把中间结果存储在HDFS文件里面(而不是本地磁盘),上一个节点得花时间去发文件,下一个计算节点也得花时间去做网络请求取数据,难道网络通讯不要时间吗?
另一者是因为MapReduce这算法很底层,只提供map和reduce两个操作给你,我们现在经常需要的什么where啊,join啊,全得依靠data shuffle的过程洗出来(data shuffle,广义来说就是在map和reduce之间做的一切事情,例如排序,分片,筛选)。这就好比让你用汇编语言去写个Moba类的游戏:能写是能写,但是非常费劲。归根到底是抽象层次太低了,使用者只有get hands very dirty
再写两个小插曲,在Spark出现之前,Hadoop生态内也出现过抽象程度更高的项目,比如Apache Pig。Pig这个项目提供了一般人最经常使用的SQL接口,然后自己在内部将SQL转化为MapReduce过程;也出现过Apache Tez这种执行引擎,提供DAG(有向无环图,简单来说就是一个执行流程图)的方式去执行MapReduce,同时也去除了一些不必要的操作(比如不再是必须一个map对应一个reduce),以此来加速整个数据处理的过程
在2009年,加州大学伯克利分校的AMP实验室,诞生了一个叫做Spark的项目。这个项目在2013年成为了Apache的孵化项目,并以极快的速度成为了一个备受欢迎和关注的顶级项目
Spark项目的初衷是为了代替MapReduce,提供一种既可以极大批量的处理分布式的数据,又有足够的容错能力,且上手容易,速度快,可以让人实现实时交互分析的解决方案。
(实时交互分析的意思是,在使用正确的方法的前提下,可以马上得到自己需要的分析结果——这一点MapReduce可做不到)
Spark和Hadoop
有些人说Spark的出现代表着Hadoop的死亡,这个观点我是不认同的。Hadoop是一个分布式的系统生态,不是靠着Spark这个引擎可以替代的。
但不得不承认,Spark的出现对于Hadoop来说,确实极大程度上弥补了一些短板,对Hadoop造成了一些影响。而Hadoop的生态,包括资源调度和文件存储的部分,对于Spark这个纯引擎来说,也是很有帮助的。
具体来说,Spark帮助Hadoop实现了用户友好。一个将Spark和Hadoop结合起来使用的人,和一个只使用Hadoop生态内工具的人,感受将会是截然不同的。
第一,使用Spark的时候,不再需要考虑怎么样把各种日常的操作硬塞到map和reduce这两个操作中间去。因为Spark提供了抽象程度更高的接口。
第二,使用Spark的时候,不用再为一个查询而等到油尽灯枯。建立在RDD和内存存储中间数据上的Spark,对实时性的支持很高。
在这里简单讲一下RDD。RDD是一个抽象的概念,一个逻辑上的数据结构,中文全称是弹性分布式数据集,最直接的理解就是一个大的dataframe——这个dataframe可能是所有机器上原始数据的总和,也可能是中间计算到某一步得到的一个中间结果形成的dataframe。
Spark Streaming
为什么要单独把Spark Streaming拿出来将呢?这属于个人执念。促使我去理解Spark这个概念的,就是Spark Streaming这个建立在Spark引擎上的应用。在我过去的想法里,Spark是一种数据处理工具,怎么还能做数据流的传输管理呢?直到我详细的去了解了Spark,才知道数据处理工具指的是MLLib或者Shark这些同样建立在Spark引擎上的应用。
单独说一下Spark Streaming。用Apache的官方说法是,Spark Streaming就是从某处接受实时数据,然后将实时数据进行分片分批,再做一些需要的处理(比如数据清洗或者数据聚合),最后再分批将数据向一个目标输送过去。
这个过程中分批分片这一点值得注意,这意味着Spark传出去的数据流是一批一批的,可以根据下游接受方的需要对传输速度和每批数据的大小进行调整。
对订单数据统计分析及其作用探究
当前在企业发展过程中,随着市场经济形势的日益复杂,使企业面临竞争压力不断增大,在这一过程中,为了更好地应对市场经济形势,企业加强了对订单数据的管理,采用原理,对订单数据展开了分析。在订单数据分析过程中,有利于对企业的发展情况做好把握,更好地分析市场经济形势,使企业在进行采购过程中,更具针对性,以保证企业在发展过程中,能够更好地获取经济效益。
订单数据统计概述
订单数据统计主要针对于订单的数据信息,利用统计学方法,实现对数据信息的有效整理,为企业发展提供依据。
对订单分析主要针对于企业在进行采购过程中,对采购货物进行分析,对量做好相应地把握。企业订单主要分为两种情况,一种情况是根据业务的需要,采购对应数量的货品;另一种则是对企业自身的销售情况进行汇总,对销售量进行分析,使采购的货品与自身的销售情况保持一致性,以保证企业能够处于一个正常的运营状态。订单分析对于企业日常经营活动有着重要影响,其关系到了企业的获利,对于企业日后成长发展具有重要意义。
接下来以商品订单明细表(datas.xlsx)为例
导入必要的Spark相关类
import org.apache.poi.ss.usermodel.{CellType, WorkbookFactory}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
1、 导入的Java转Scala集合的库
import java.io.FileInputStream
import scala.collection.JavaConverters.asScalaIteratorConverter
2、 创建SparkConf并设置应用名称
第一行的代码是:创建 SparkConf 对象,设置应用名称和运行模式
第二行的代码是:创建 SparkSession 对象
val conf = new SparkConf().setAppName("ProductSellTop3").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val filePath = "datas/datas.xlsx" // 要处理的文件的路径
3、使用POI库读取XLSX文件
第一行的代码是:创建 XSSFWorkbook 对象用于打开 XLSX 文件
第二行的代码是:获取工作表,假设数据在第一个工作表
val workbook = WorkbookFactory.create(new FileInputStream(filePath))
val sheet = workbook.getSheetAt(0)
4、读取数据并将其存储为 Seq[List[String]] 数据结构
val data: Seq[List[String]] = sheet.iterator().asScala.toSeq
.map(row => row.iterator().asScala.zipWithIndex.map {
case (cell, index) =>
if (index == 1 && cell.getCellType == CellType.NUMERIC) {
// 假设第二列的数字值表示日期
val dateValue = cell.getNumericCellValue.toLong
val formattedDate = org.apache.poi.ss.usermodel.DateUtil.getJavaDate(dateValue)
new java.text.SimpleDateFormat("yyyy/MM/dd HH:mm:ss").format(formattedDate)
} else cell.toString
}.toList)
5、创建 Spark RDD 以便进一步处理
val ListRdd = spark.sparkContext.parallelize(data)
6、提取特定列数据,例如商品 ID 和总价格
val ProductRdd: RDD[(String, Float)] = ListRdd.map(
data => (data(4), data(6).toFloat) // 使用索引 4(商品 ID)和 6(总价格)提取数据
)
7、对商品 ID 进行归并并计算总销售额
val reduceRDD: RDD[(String, Float)] = ProductRdd.reduceByKey(_ + _)
8、对总销售额进行降序排序
val sortASCRDD: RDD[(String, Float)] = reduceRDD.sortBy(_._2, ascending = false)
9、获取前十个商品和其销售额
val resultArray1: Array[(String, Float)] = sortASCRDD.take(10)
10、打印结果
print(resultArray1.mkString("\n"))
// 停止 SparkSession
spark.stop()
}
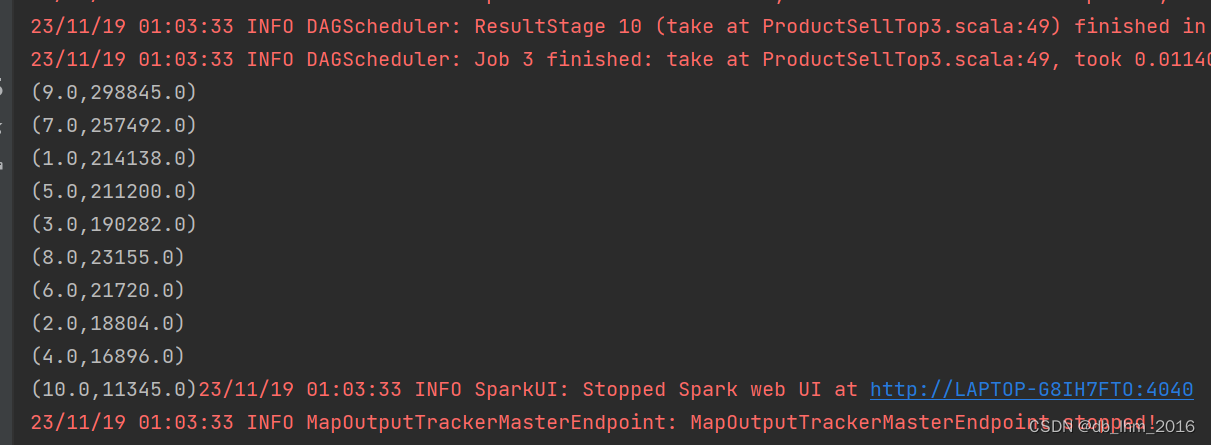
最后打印出来的结果如图
从图中可以看出前十个商品的ID以及这个ID的销售额















 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









