







目录
概述
Dataframe数据的清洗和预处理是数据分析中至关重要的一环,其目标是为了提高数据质量,确保后续分析的准确性和有效性。在实际应用中,原始数据往往存在缺失、重复、异常或格式不一致等问题,这些问题如果不经过处理,可能会严重影响分析结果的可靠性。
在进行数据清洗和预处理时,我们需要遵循一定的步骤和原则。首先,我们需要对数据进行整体的了解和探索,包括数据的来源、结构、分布以及存在的问题等。然后,我们可以根据问题的具体情况选择合适的方法进行清洗和处理。例如,对于缺失值,我们可以选择填充、删除或插值等方法;对于重复值,我们可以选择删除或合并等方法。同时,我们还需要注意保留数据的原始信息和特征,避免在清洗过程中引入新的误差或偏差。
除了上述的基本方法外,我们还可以利用一些高级技巧来优化数据清洗和预处理的效果。例如,我们可以使用正则表达式来处理复杂的文本数据;我们可以利用机器学习算法来自动识别和填充缺失值;我们还可以结合可视化工具来直观地展示数据的分布情况和清洗效果等。
总之,Dataframe数据的清洗和预处理是数据分析过程中不可或缺的一步。通过综合运用各种方法和技巧,我们可以提高数据质量,确保分析的准确性和有效性,为后续的数据挖掘和模型训练奠定坚实的基础。
Dataframe 数据的清洗和预处理
1. 排序
(1) sort_values()
按(多)列/行 值排序
参数:
- by = [‘排序字段1’ , '排序字段2‘,…]
传入的为一个包含需要排序的字段的列表,也可不传列表,按照位置参数传入单个列或列表 - axis= 0/1 默认为0 ,即按列值去排序,传入1为按行值排序
- ascending = [True,False,…] True为升序,False为降序
可不传列表,传入True或者False 即所有字段按同一方式排序,传入列表时与by的列表一一对应 - inplace= True/False 是否在原Dataframe上修改,False需要用额外变量接收
- na_position: 可以是 ‘first’ 或 ‘last’,用于确定缺失值(NaN)在排序后的位置。
代码展示:
# 原顺序
print(data)
print('-'*31)
# 在原Dataframe按year升序排序lifeExp降序排序
data.sort_values(['year','lifeExp'],axis=0,ascending=[True,False],inplace= True)
print(data)
运行结果:

- 注意
- sort_values() 默认会保留索引与数据的对应关系,即排序后的 DataFrame 或 Series 会保持原始索引。如果你希望根据排序结果重新设定索引,可以使用 reset_index() 方法。
- 对于大型数据集,sort_values() 可能会比 sort_index() 慢,因为它需要对数据进行实际的排序操作,而不是简单地根据索引进行排序。
- 如果需要同时根据多列的值进行排序,可以将列名作为列表传递给 by 参数。排序的优先级按照列表中的顺序进行。
(2). sort_index()
参数:
- ascending: 默认是 True,表示升序排序。如果设置为 False,则进行降序排序。
- inplace: 默认是 False,表示返回一个新的对象。如果设置为 True,则直接修改原始对象。
- kind: 对于 Series,此参数决定如何排序索引。对于 DataFrame,此参数无效。
- level: 对于具有多级索引的对象,此参数用于指定按哪一级索引进行排序。
- sort_remaining: 仅对多级索引有效。如果为 True,则除了指定的级别外,还对其他级别进行排序。
- na_position: 可以是 ‘first’ 或 ‘last’,用于确定缺失值(NaN)在排序后的位置。
代码实现:
# 按照索引倒序排序
data.sort_index(ascending = False )
print(data)
运行结果:
(3). nlargest() 和 nsmallest()
nlargest() 和 nsmallest() 是 pandas 库中用于选择数据框(DataFrame)或序列(Series)中最大或最小 n 个值的便捷方法。这两个函数都基于排序操作,并返回按指定顺序排列的索引或值。
- nlargest()
nlargest(n, columns, keep=‘first’) 函数返回 DataFrame 中 n 个最大的值。- n:需要返回的最大值的数量。
- columns:用于选择最大值的列名或列名列表。
- keep:可选参数,用于处理重复值。
默认为 ‘first’,表示只保留第一次出现的索引;‘last’ 表示保留最后一次出现的索引;‘all’ 表示保留所有出现的索引。
- nsmallest()
nsmallest(n, columns, keep=‘first’) 函数返回 DataFrame 中 n 个最小的值。
参数与 nlargest() 相同。
代码实现:
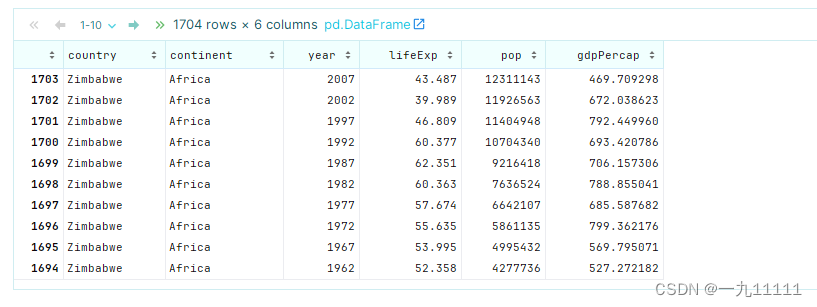
# 获取lifeExp前10大的数据(这里不会更改原Dataframe需要用变量接收)
a = data.nlargest(10,columns='lifeExp')
print(a)
运行结果:
2. 去重
(1). unique()
DataFrame.unique() 方法用于获取 DataFrame 中每一列的唯一值数组。该方法返回一个包含 DataFrame 中每列唯一值的 NumPy 数组。请注意,unique() 方法是应用于 Series 的,而不是直接应用于 DataFrame。但是,你可以对 DataFrame 的每一列单独调用 unique(),或者对整个 DataFrame 调用 apply(unique) 来获取每列的唯一值。
代码实现:
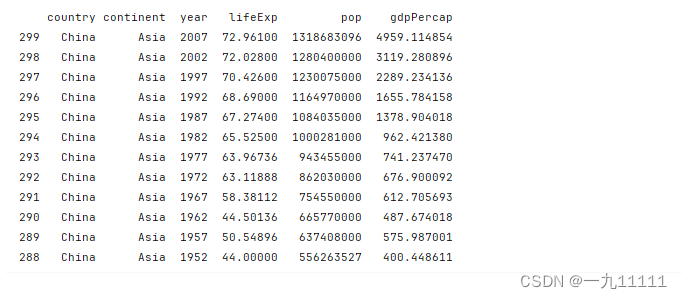
# 获取year的唯一值
a = data.year.unique()
print(a)
执行结果:

(2). drop_duplicates()
返回一个删除重复项后的 DataFrame。
- subset:列标签或列标签序列,可选。仅考虑某些列来标识重复项。默认使用所有列。
- keep:{‘first’, ‘last’, False},默认 ‘first’。
- first:保留第一次出现的重复项。
- last:保留最后一次出现的重复项。
- False:删除所有重复项。
- inplace:布尔值,默认为 False。如果为 True,则直接在原 DataFrame 上进行修改并返回 None。
- ignore_index:布尔值,默认为 False。如果为 True,则重置结果的索引。
代码实现:
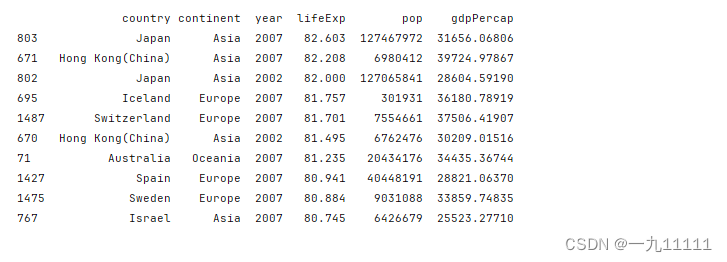
# 按照popb逆序排序
data.sort_values('pop', ascending= False,inplace=True)
# 获取每年pop最大地区,改变原Dataframe
data.drop_duplicates(subset='year',keep='first',inplace=True)
print(data)
运行结果:
(3). nunique()
在Pandas库中,nunique() 是一个常用于 DataFrame 和 Series 的方法,用于计算每个列(或整个 Series)中唯一元素的数量。对于 DataFrame,它会返回一个 Series,其中索引是列名,值是相应列中的唯一元素数量。
代码实现:
# 计算每列唯一值的数量
data.nunique()
运行结果:

3. 缺失值处理
在pandas的DataFrame中,缺失值通常表示为NaN(Not a Number),这可能是因为数据缺失、导入错误或其他原因造成的。处理这些缺失值是数据分析和预处理的重要步骤。
(1) 缺失值的判断
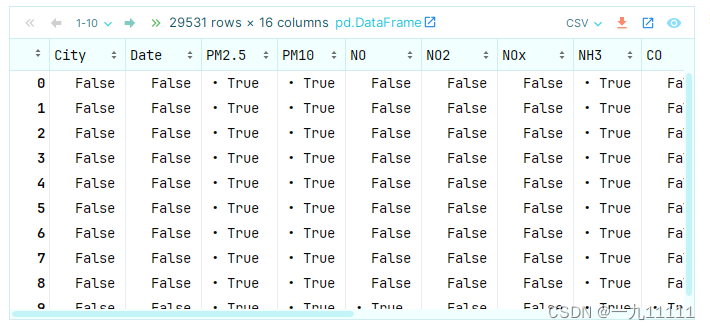
- isnull() 和isna() 判断是否为缺失值
对每一个元素进行判断是否为缺失值,是缺失值则填充为True,否则为False,最终返回一个全是布尔的值的Dataframe,isbull和isna除了表达式不同,并无区别
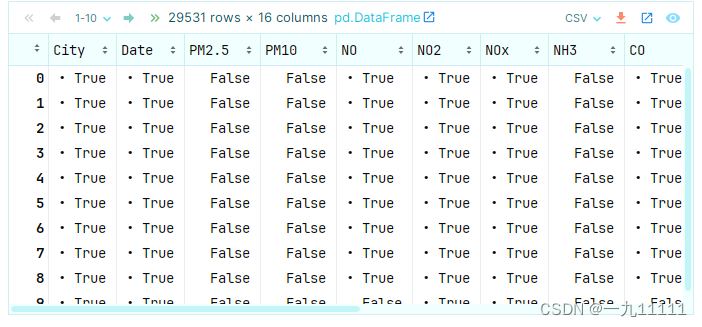
city_data.isnull()
运行结果:
- notnull()和notna() 判断是否不是缺失值
对每一个元素进行判断是否不为为缺失值,不是缺失值则填充为True,否则为False,最终返回一个全是布尔的值的Dataframe,notbull和notna除了表达式不同,并无区别
city_data.notna()
运行结果:
(2) 缺失值的加载
在read_数据类型()到输入方法中有详细介绍(详情请见Pandas入门篇(二)-------Dataframe篇1(Dataframe基础知识以及单个Dataframe的处理)(机器学习前置技术栈))
主要是keep_default_na和na_values 这两个参数的设置。
(3) 缺失值可视化(图表api的介绍请看后续更新的matplotlib和seaborn,此处不做详细介绍)
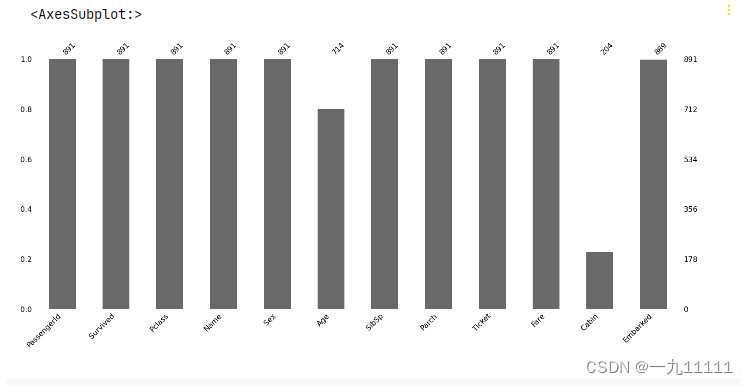
# 可视化 查看缺失值
import matplotlib as plt
import missingno as msno #查看缺失值需要导的包
msno.bar(train) # 柱状图
运行结果:
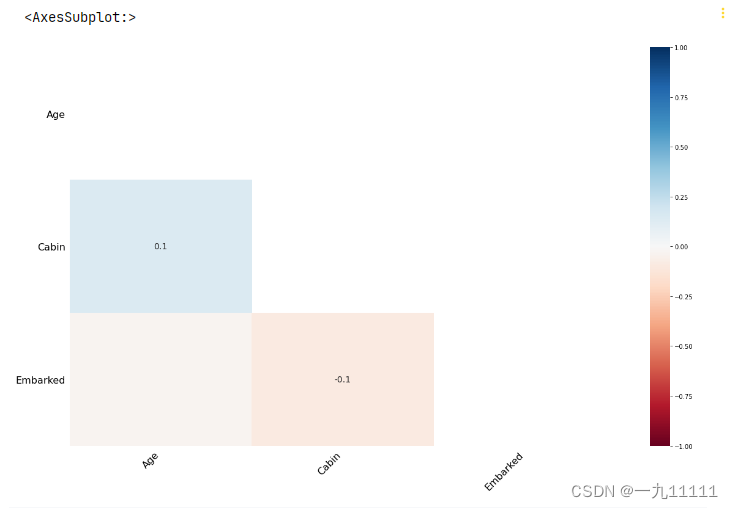
# 查看缺失值的相关性(堆积图)
msno.heatmap(train)
运行结果:
(4) 缺失值的处理
在处理Dataframe中的缺失值时,有多种策略和方法可以选择,具体取决于数据的性质以及分析目标。以下是一些常见的处理缺失值的方法:
4.1 删除含有缺失值的行或列
如果缺失值较多且对分析结果影响不大,可以选择删除含有缺失值的行或列。
dropna()
dropna() 是 pandas 库中的一个非常有用的方法,用于删除包含缺失值的行或列。
dropna() 方法有几个关键参数,允许你更精细地控制哪些行或列应该被删除。
以下是一些常用的参数:
- axis: 指定沿哪个轴删除包含缺失值的元素。axis=0 或 ‘index’ 表示删除行,axis=1 或 ‘columns’ 表示删除列。
- how: 指定如何确定哪些行或列包含缺失值。‘any’ 表示只要行或列中有任何缺失值就删除,‘all’ 表示只有行或列中所有值都是缺失值才删除。
- thresh: 保留至少具有 thresh 个非 NA/null 值的行。
- subset: 考虑指定的列的子集,以确定哪些行或列应该被删除。
- inplace: 如果为 True,则直接在原始 DataFrame 上进行修改,并返回 None。否则,返回一个新的 DataFrame。
4.1.1 删除包含至少一个缺失值的行
import pandas as pd
# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [5, None, None, 8],
'C': [9, 10, 11, 12]
})
# 删除包含至少一个缺失值的行
df_dropped_rows = df.dropna()
print(df_dropped_rows)
运行结果:

4.1.2 删除所有值都是缺失值的列
# 删除所有值都是缺失值的列
df_dropped_cols = df.dropna(axis=1, how='all')
print(df_dropped_cols)
运行结果:

4.1.3 删除在指定列中有缺失值的行
# 删除在指定列(例如 'A' 和 'B')中有缺失值的行
df_dropped_subset = df.dropna(subset=['A', 'B'])
print(df_dropped_subset)
运行结果:

4.1.4 删除在指定列中有缺失值的行
# 删除在指定列'A' 和 'B'中有缺失值的行
df_dropped_subset = df.dropna(subset=['A', 'B'])
print(df_dropped_subset)
运行结果:

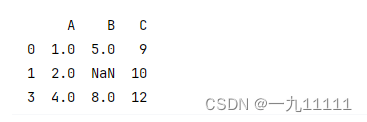
4.1.5 删除至少有N个非缺失值的行、列
# 删除行,要求至少有两个非缺失值
df_thresh = df.dropna(thresh=2)
print(df_thresh)
运行结果:
4.2 填充缺失值
填充缺失值是更常见的处理方式,可以根据数据的特点选择适当的填充策略。
fillna( )
fillna() 是 pandas 中用于填充 DataFrame 或 Series 中缺失值(NaN)的函数。以下是 fillna() 函数的主要参数介绍:
-
value: 这是用于填充缺失值的值。
它可以是单个值,也可以是字典,其中键是列名,值是用于填充该列的缺失值的值。如果传递单个值,那么该值将用于填充所有列的缺失值。如果传递字典,那么每个列将根据其对应的值进行填充。 -
method: 用于确定填充缺失值的方法。它可以是以下值之一:
- ‘ffill’: 使用前一个有效值进行填充(向前填充)。
- ‘bfill’: 使用后一个有效值进行填充(向后填充)。
-
axis: 指定要填充缺失值的轴。
对于 DataFrame,默认为 0,表示按行填充;如果设置为 1,则按列填充。对于 Series,此参数不起作用。 -
inplace: 布尔值,默认为 False。
如果为 True,则直接在原始对象上进行修改,并返回 None;否则返回一个新的对象。 -
limit: 这是一个可选参数,用于限制连续填充的最大次数。
例如,如果设置为 1,则每个缺失值最多只会被前一个或后一个非缺失值填充一次。 -
downcast: 用于指定填充后数据的类型。
在某些情况下,填充操作可能会导致数据类型的提升(例如,整数列变为浮点数列)。通过设置 downcast 参数,可以控制填充后数据的类型,以节省内存。
4.2.1使用固定值填充
# 使用某个固定值(比如0或均值)填充缺失值
df_filled = df.fillna(0) # 使用0填充
print(df_filled)
print()
df_filled_mean = df.fillna(df.mean()) # 使用列均值填充
print(df_filled_mean)
运行结果:

4.2.2使用前一个或后一个非缺失值填充
# 使用前一个非缺失值填充
df_filled_ffill = df.fillna(method='ffill')
print(df_filled_ffill)
print()
# 使用后一个非缺失值填充
df_filled_bfill = df.fillna(method='bfill')
print(df_filled_bfill)
运行结果:
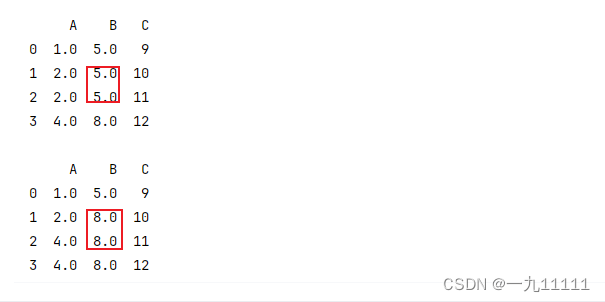
4.2.3使用插值方法填充
对于时间序列数据或连续型变量,可以使用插值方法(如线性插值)来填充缺失值。
# 使用线性插值填充缺失值
df_interpolated = df.interpolate()
print(df_interpolated)
运行结果:
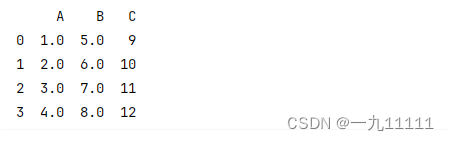
4.2.4使用模型预测填充(后续博客中会详细介绍)
对于复杂的数据集,可以使用机器学习模型来预测并填充缺失值。
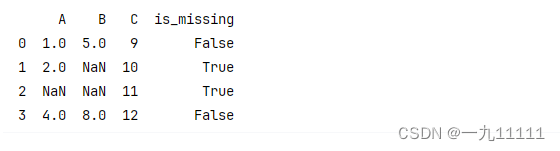
4.3 标记缺失值
有时候,我们不直接填充缺失值,而是将其标记为一个特殊的值或创建一个新的标志列来指示缺失。
# 创建一个新的标志列来指示缺失值
# 创建一个新的标志列来指示缺失值
df['is_missing'] = df.isnull().any(axis=1)
print(df)
运行结果:
注意事项
- 在处理缺失值时,务必了解缺失值的产生原因以及它们对分析结果的影响。有些情况下,缺失值可能包含重要的信息,简单地删除或填充可能会导致信息丢失或引入偏差。
- 对于不同的特征和列,可能需要采用不同的缺失值处理策略。例如,对于分类变量,可以使用众数填充;对于连续变量,可以使用均值、中位数或插值等方法填充。
- 在填充缺失值后,建议对数据进行一些探索性分析,以检查填充是否合理,并评估其对分析结果的影响。
4. 分组聚合
groupby()允许你根据一个或多个键对DataFrame进行分组,并对每个组执行某种形式的计算或操作。groupby()返回的是一个GroupBy对象,它代表了对数据进行分组后的视图。你可以对这个对象调用各种聚合函数(如sum(), mean(), count(), max(), min()等)或其他操作来获取所需的结果。
格式1:多列使用同一聚合函数
Dataframe.groupby([分组列1,分组列2,…] , as_index= bool )[[要进行聚合的列1,要进行聚合的列2,…]].聚合函数
as_index : 是否将分组字段作为索引列,默认为True
格式2:多列使用不同聚合函数
Dataframe.groupby([分组列1,分组列2,…] , as_index= bool ).agg({要进行的聚合的列1:聚合函数名1,要进行的聚合的列1:聚合函数名2,…})
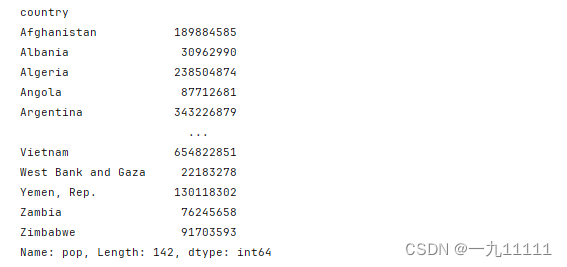
- 根据单个键对DataFrame进行分组
# 统计不同国家的pop的和,单个分组可不加[]
a = data.groupby('country')['pop'].sum()
print(a)
运行结果:
- 根据多个键对DataFrame进行分组
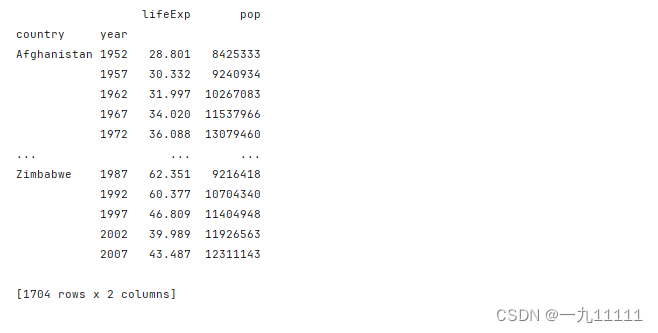
# 统计不同 country 的每一年 的lifeExp和pop的最大值
b = data.groupby(['country','year'])[['lifeExp','pop']].max()
print(b)
运行结果
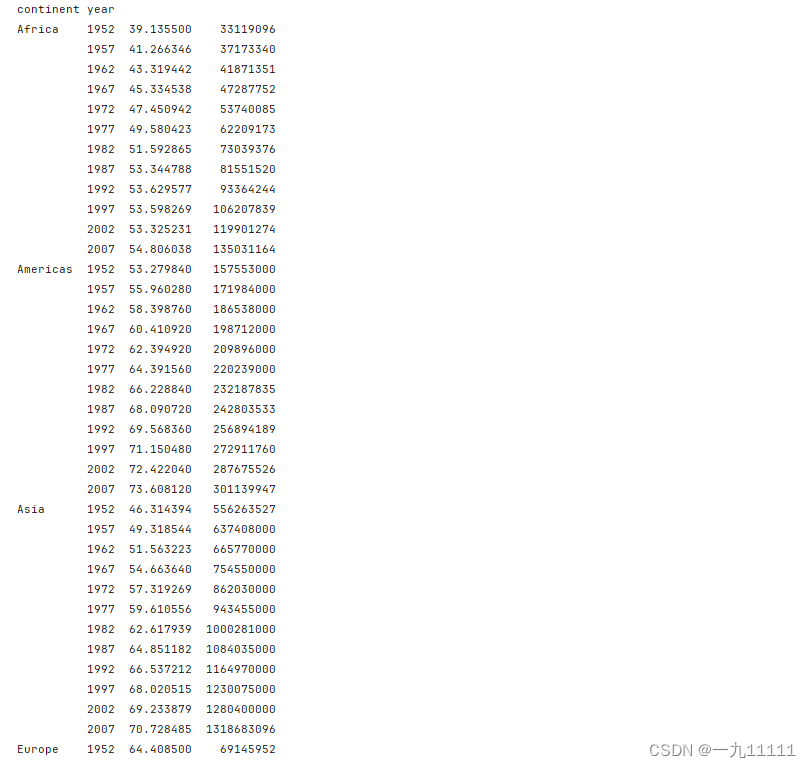
- 根据多个分组列对不同聚合列进行不同聚合操作
# 统计每个continent每一年lifeExp的平均值pop的最大值
c = data.groupby(['continent','year']).agg({'lifeExp':'mean','pop':'max'})
print(c)
注意事项:
- groupby()函数返回的对象本身并不包含聚合数据,它只是定义了一个分组视图。你需要对这个对象调用聚合函数或其他操作来获取结果。
- groupby()函数非常灵活,它允许你根据任何列的组合进行分组,并可以很容易地与其他Pandas函数和方法结合使用。
- 对于大型数据集,groupby()操作可能会消耗较多的内存和计算资源,因此在使用时需要注意性能问题。
下篇内容
多个Dataframe的数据组合,pandas的apply函数,pandas的向量化函数以及lambda函数















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









