







一 List列表
为什么需要列表?
我们知道当我们存放一个学生的姓名时,我们可以定义一个字符串变量,我们如果要存放5个呢可以定义5个字符串变量,可是当我们要存放100个,1000个学生姓名时是不是这样做就显得太麻烦了,因此我们引入列表这一个概念。列表可以一次存储多个数据。
1.1 列表的定义

列表内的每一个数据,称之为元素
▣以[]作为标识
▣列表内的每一个元素用,逗号隔开
列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套(列表里面的元素为列表)
列表定义演示
"""
演示Python列表
"""
# 定义一个列表
name_list = ['QTR','POI','LKJ','Python']
print(name_list)
print(type(name_list))
# 定义一个嵌套列表
my_list =[[1,2,3],[4,5,6]]
print(my_list)
print(type(my_list))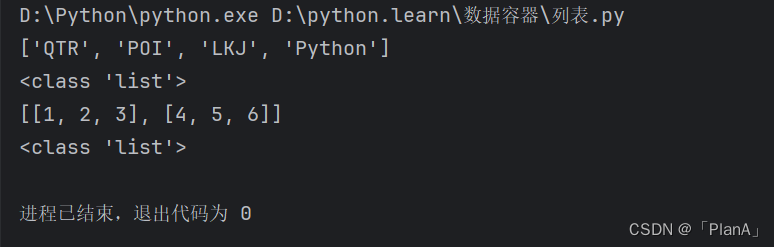
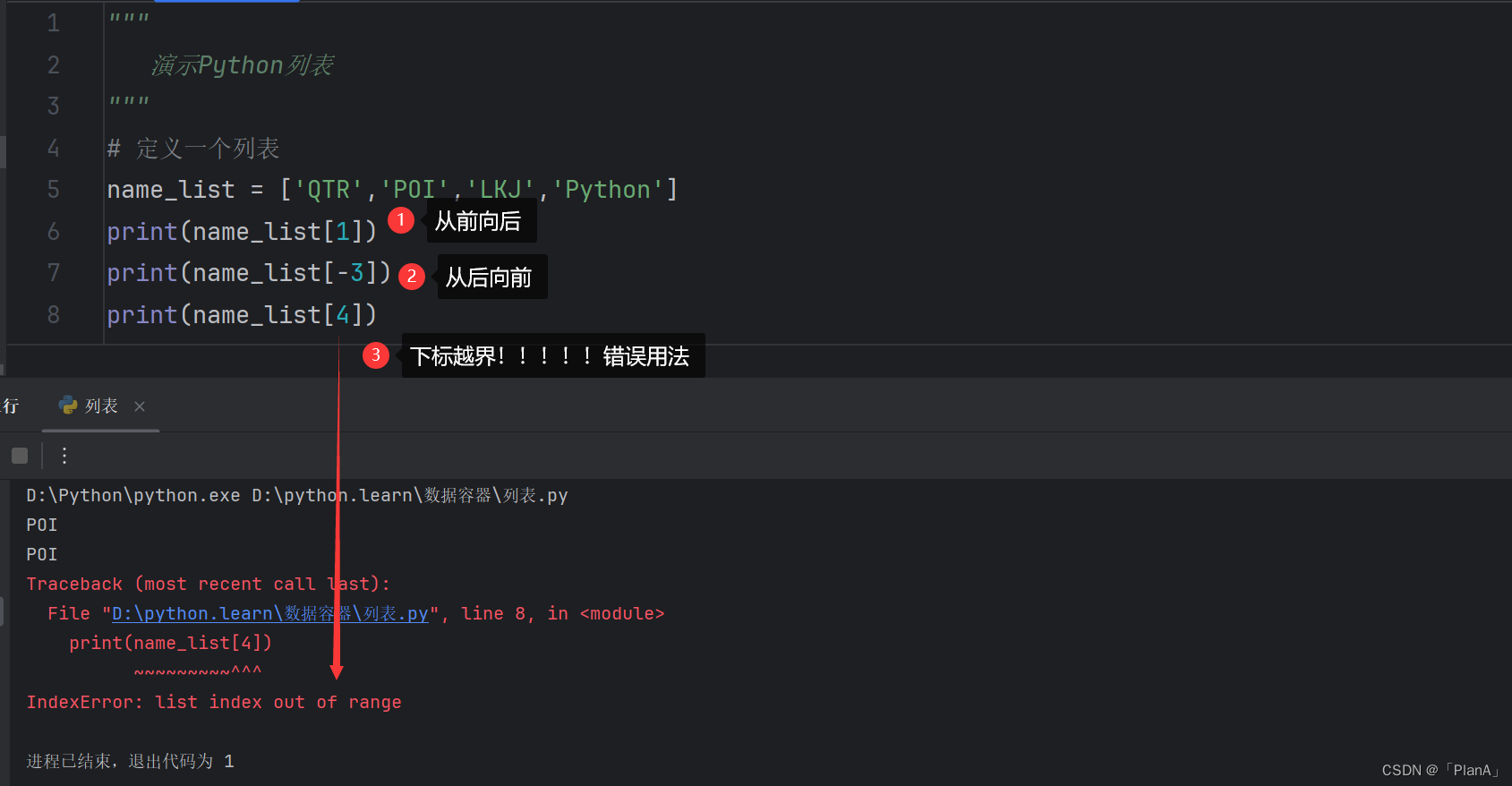
1.2 列表的下标(索引)
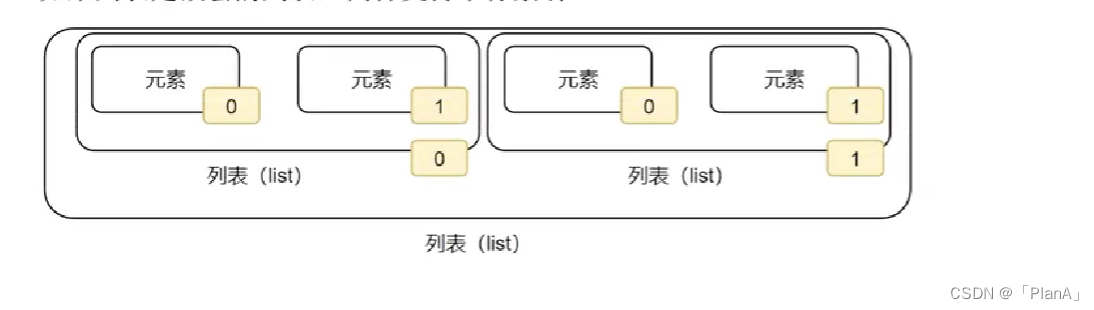
通过前面的演示我们可以发现:我们输出列表的内容时,输出的都是列表里面的全部元素,我们有没有办法获得特定的元素呢?我们可以利用元素的下标索引来找到指定的元素。

对于任何一个列表(从左向右看)来说它的下标索引是从0开始递增的。如图,列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增。我们只需要按照对应的下标索引来找到相应的元素。

同理,我们也可以从列表的右边来查找,此时列表的最右边的元素的下表为-1,向左依次递减。
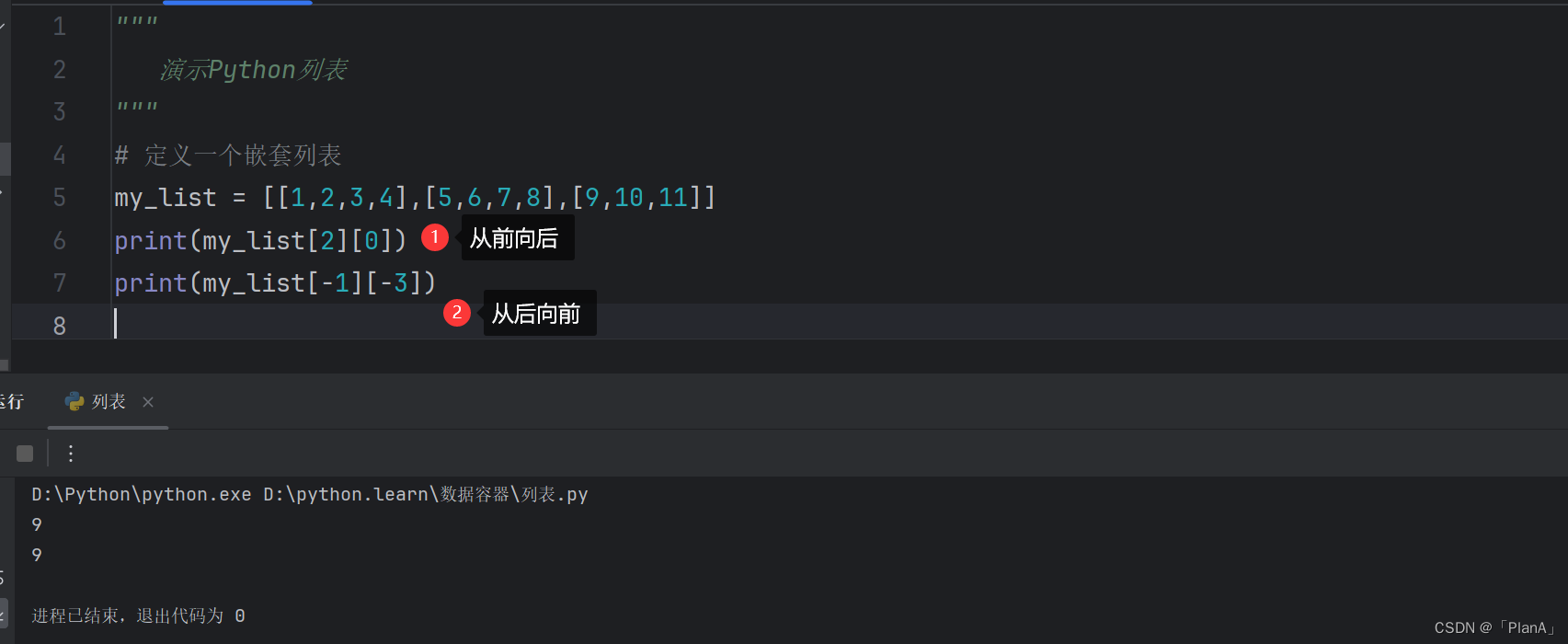
嵌套列表的下标索引
如果是嵌套列表,我们取出元素是按照如下格式即可:
列表[1]列表[0]
单个列表的下标索引的使用
 嵌套列表的下标索引的使用
嵌套列表的下标索引的使用
1.3 列表的常用操作
【列表的查询功能】
查找某元素的下标
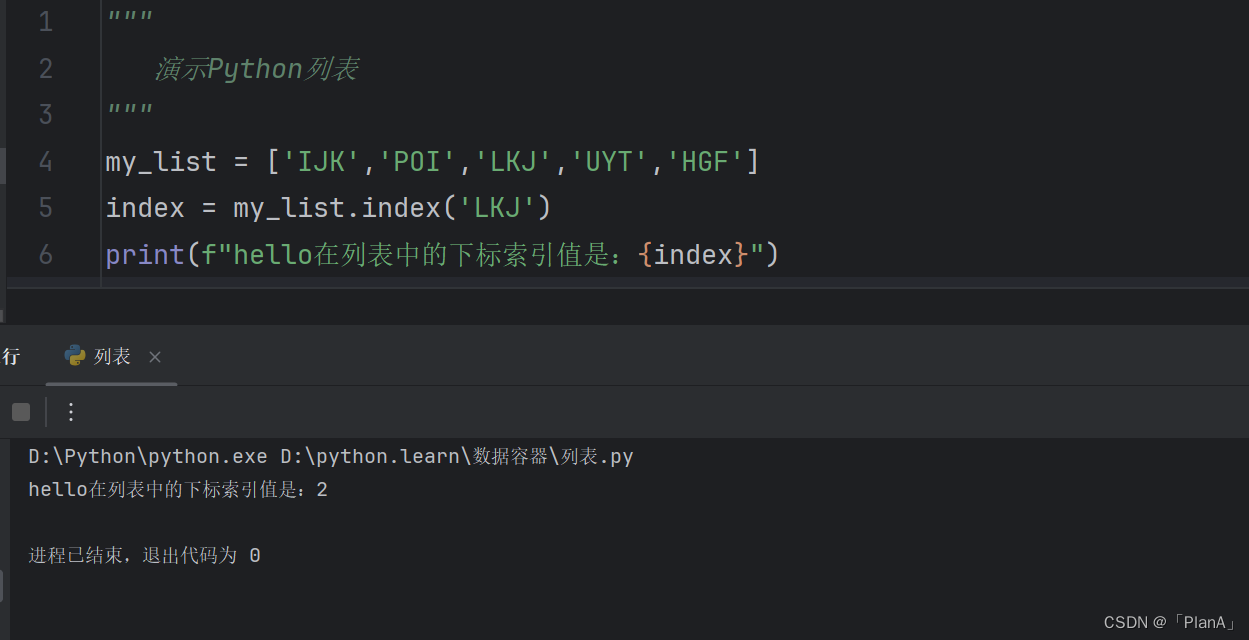
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)
方法演示:
【列表的修改功能】
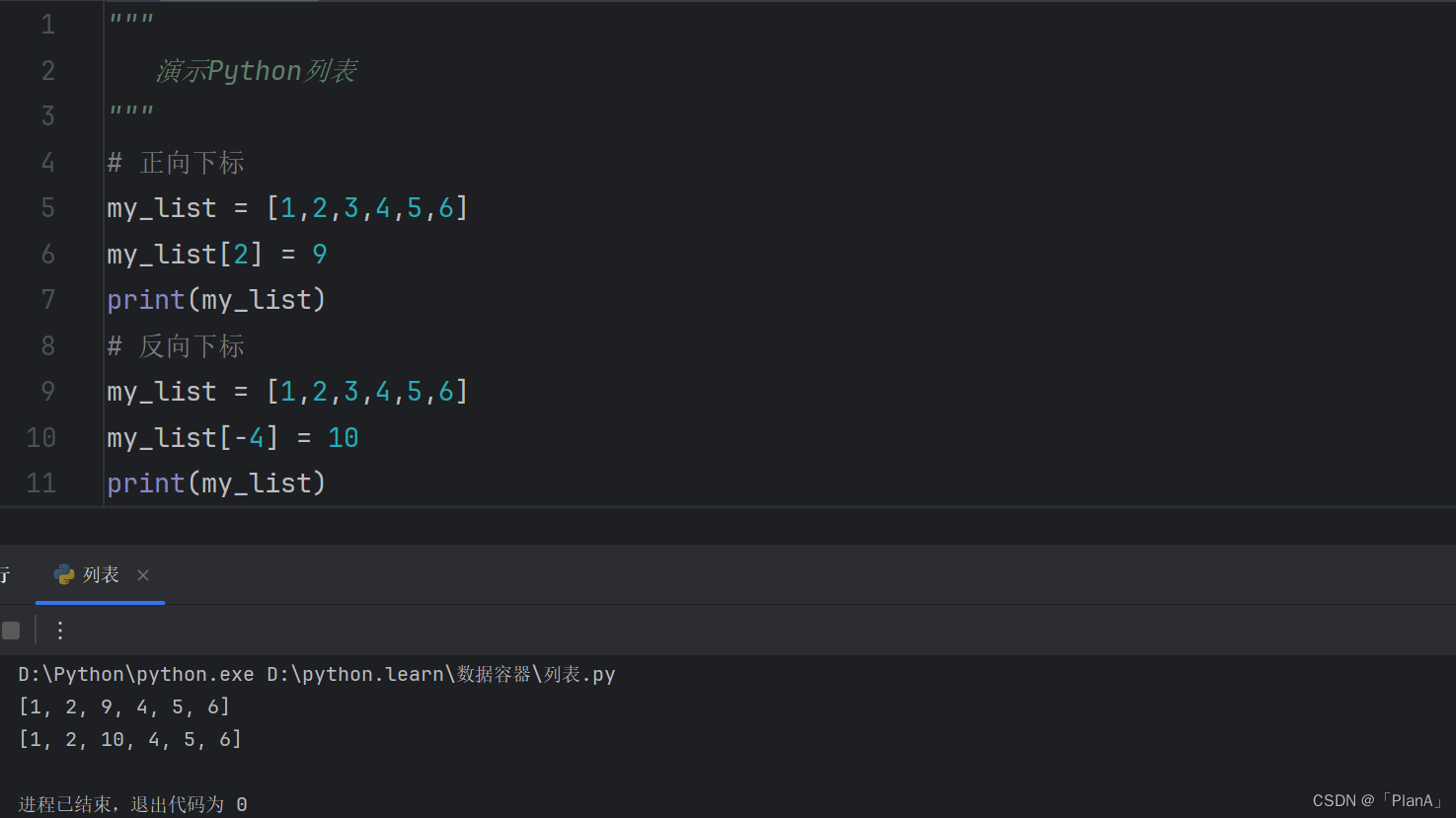
修改特定位置(索引)的元素值:
语法:列表[下标] = 值
填入列表的下标时,我们可以使用正向的下标值,也可以使用方向的下标值,实现对元素修改的功能。
方法演示:
【列表的插入功能】
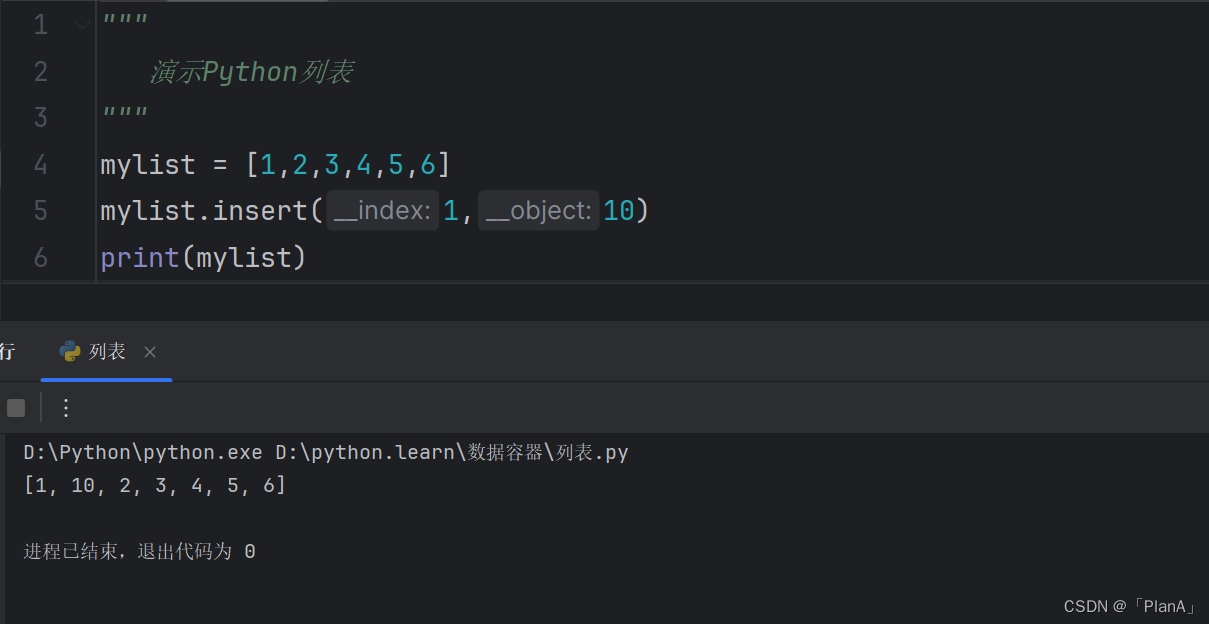
插入元素
语法:列表.insert(下标,元素)
功能:在指定的下标位置,插入指定的元素。
方法演示:
【列表追加元素功能】
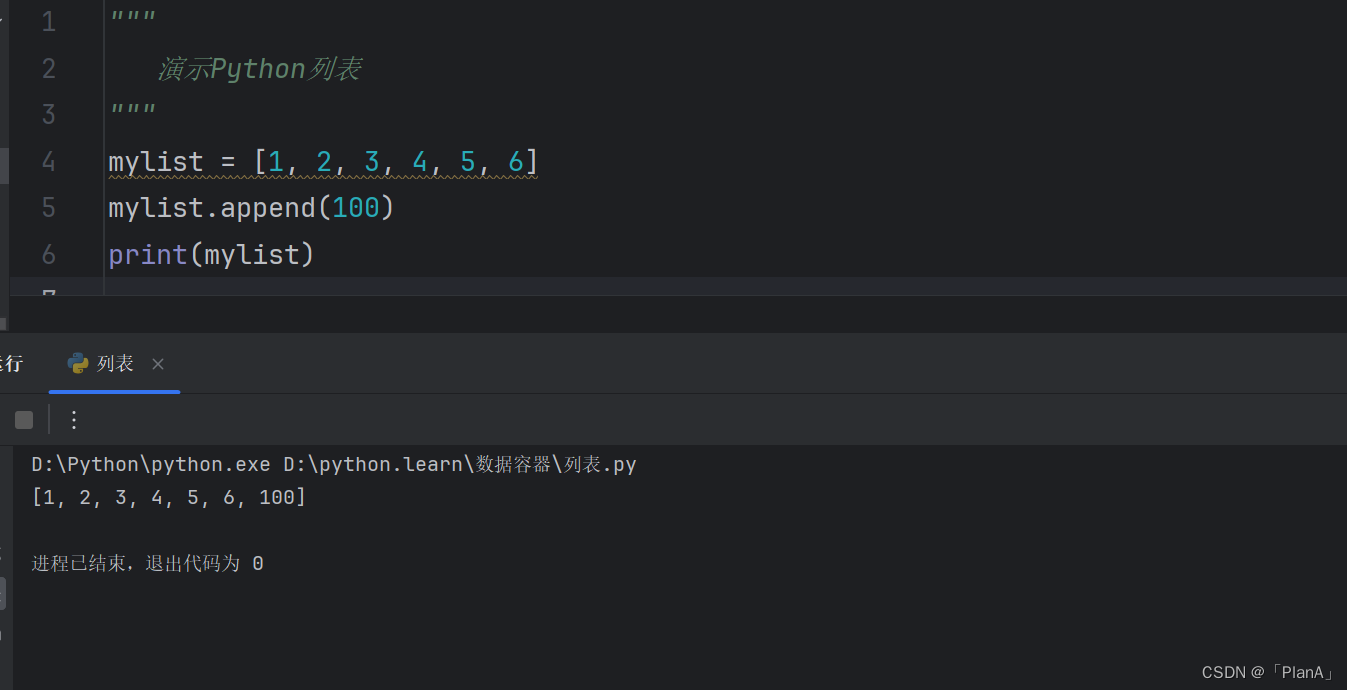
追加单个元素
语法:列表.append(元素)
功能:将指定元素追加到列表的尾部
方法演示:
追加多个元素
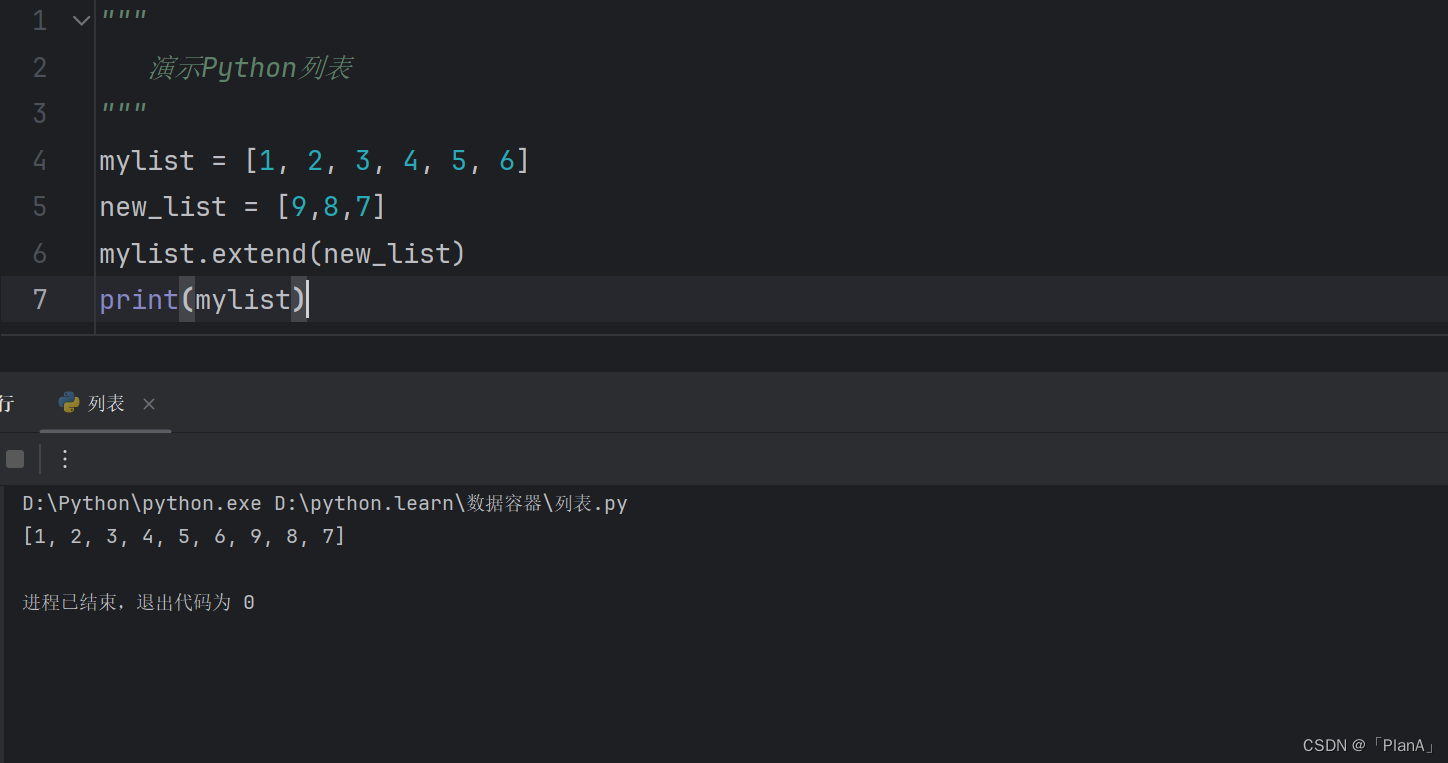
语法:列表.extend(其他数据容器)
功能:将其他数据容器里面的内容取出,依次追加到列表的尾部
方法演示:
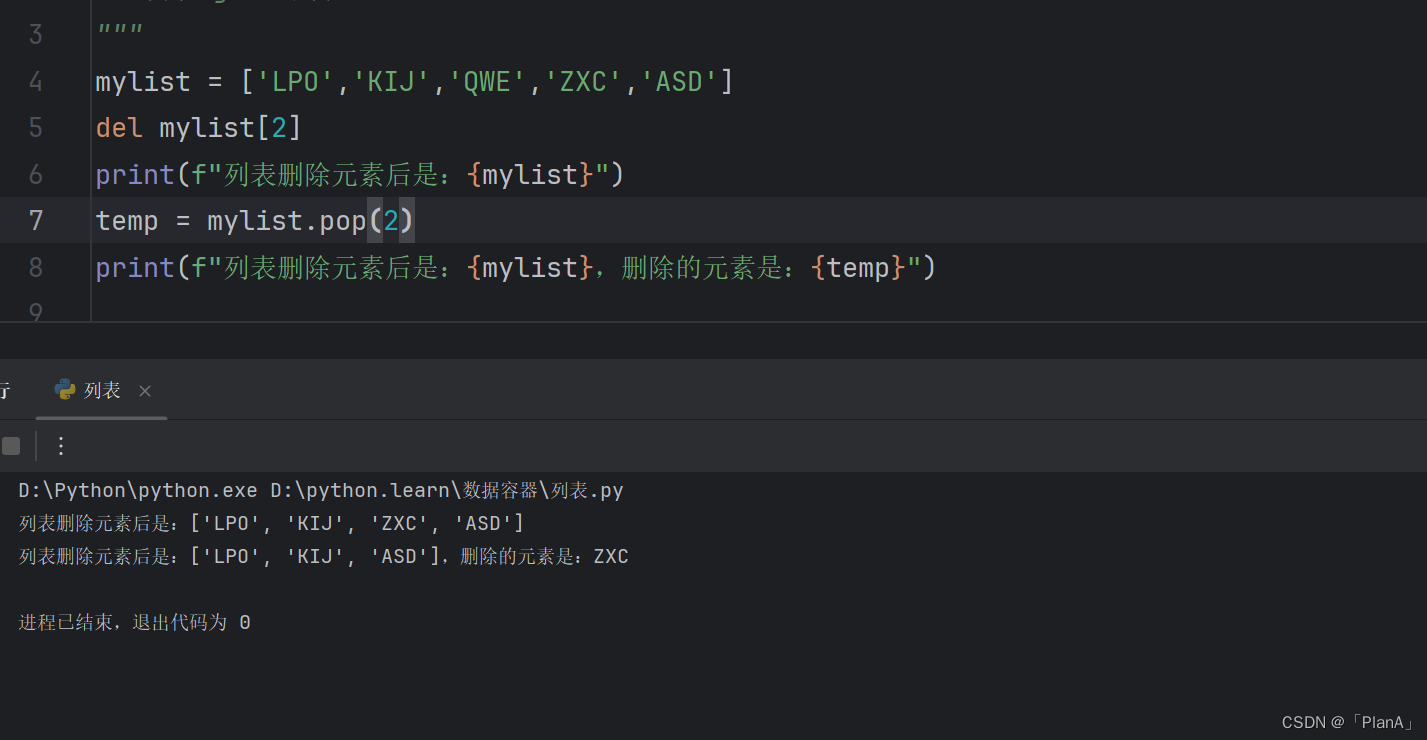
【删除列表元素】
语法1:del 列表[下标]
语法2:列表.pop(下标)
方法演示:
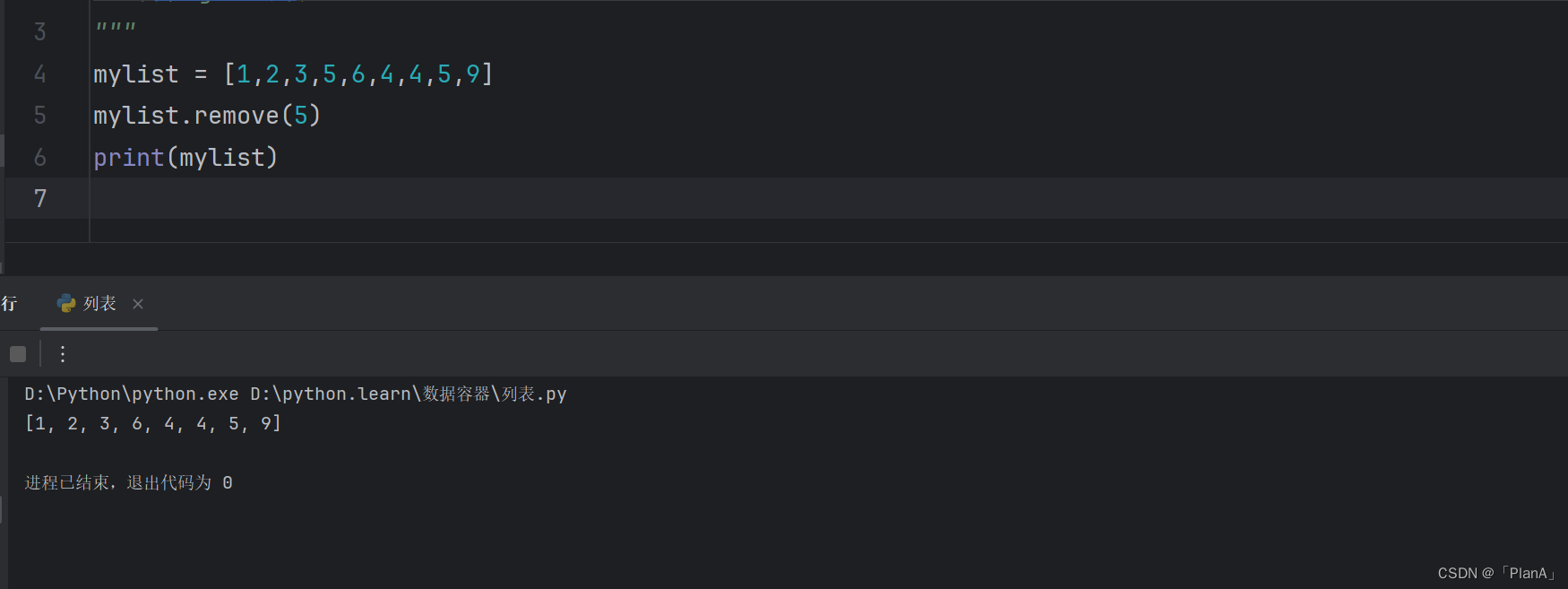
【删除匹配项元素】
语法:列表.remove(元素)
功能:删除某元素在列表中的第一个匹配项
方法演示:
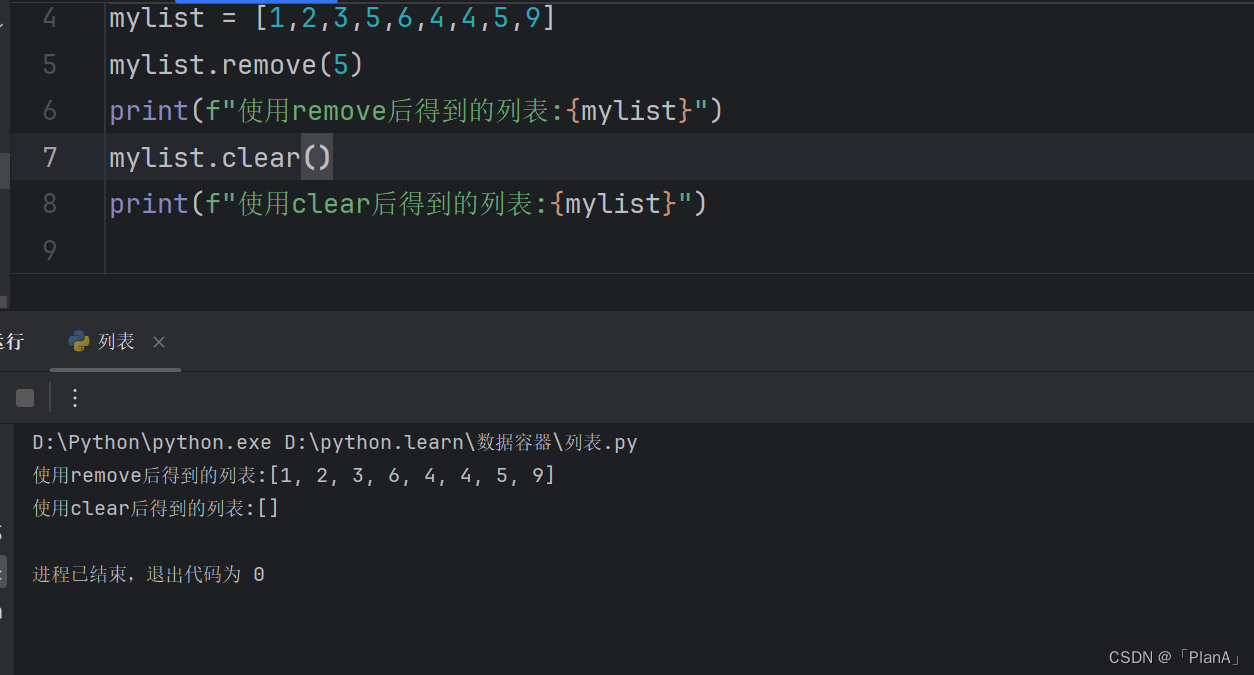
【清空整个列表】
语法:列表.clear()
功能:清空整个列表。
功能演示:
【元素在列表内的数量】
语法:列表.count(元素)
功能:统计指定元素在列表中的数量。
方法演示:
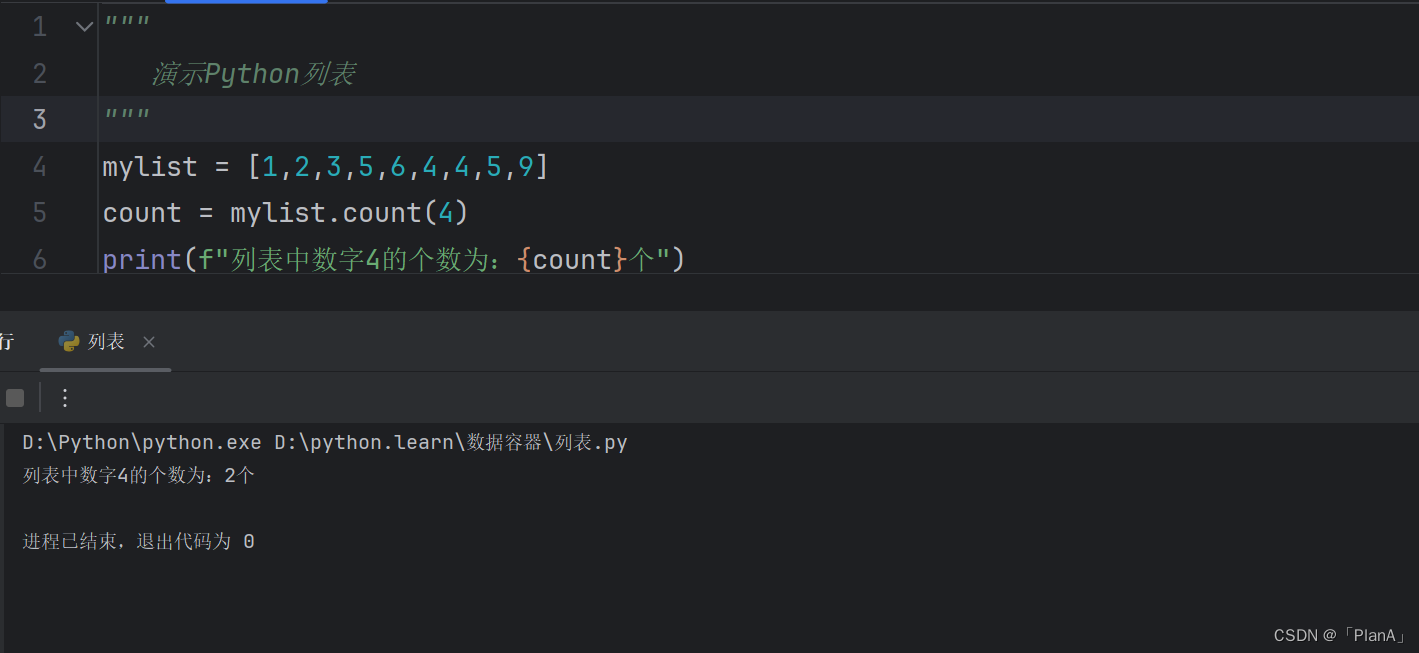
【统计列表的总元素个数】
语法:len(列表)
功能:统计列表中元素的个数
方法演示:
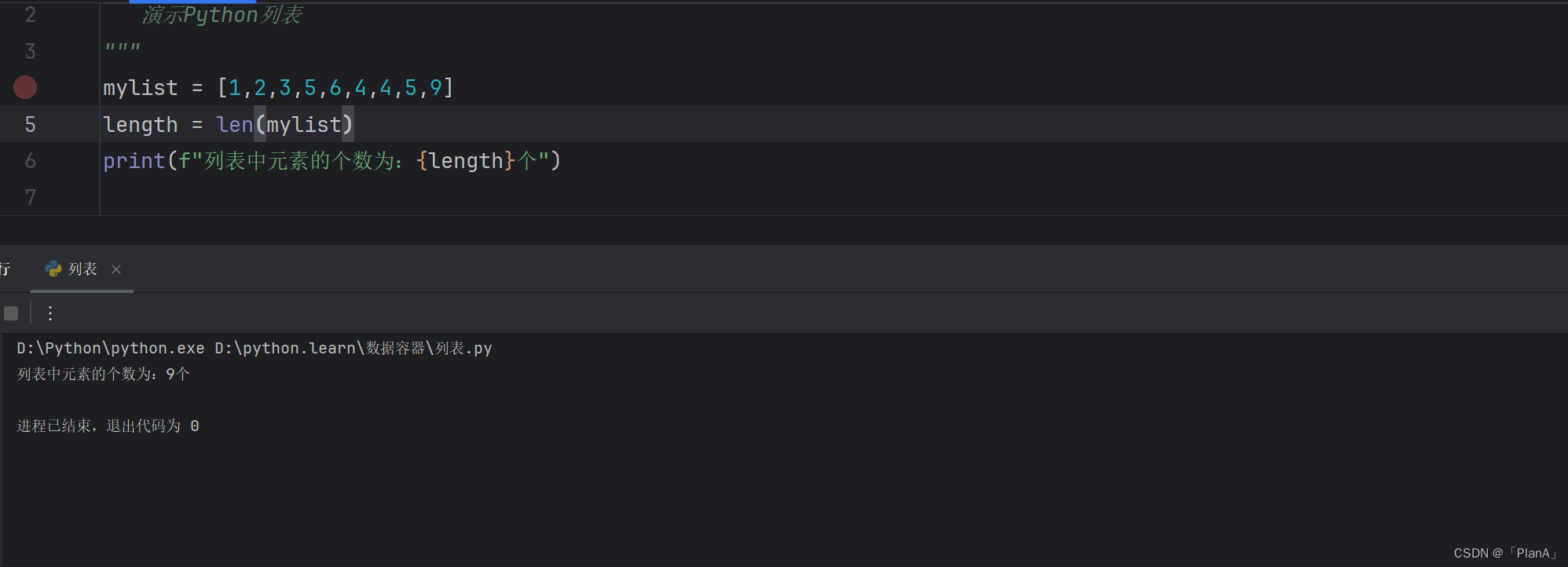
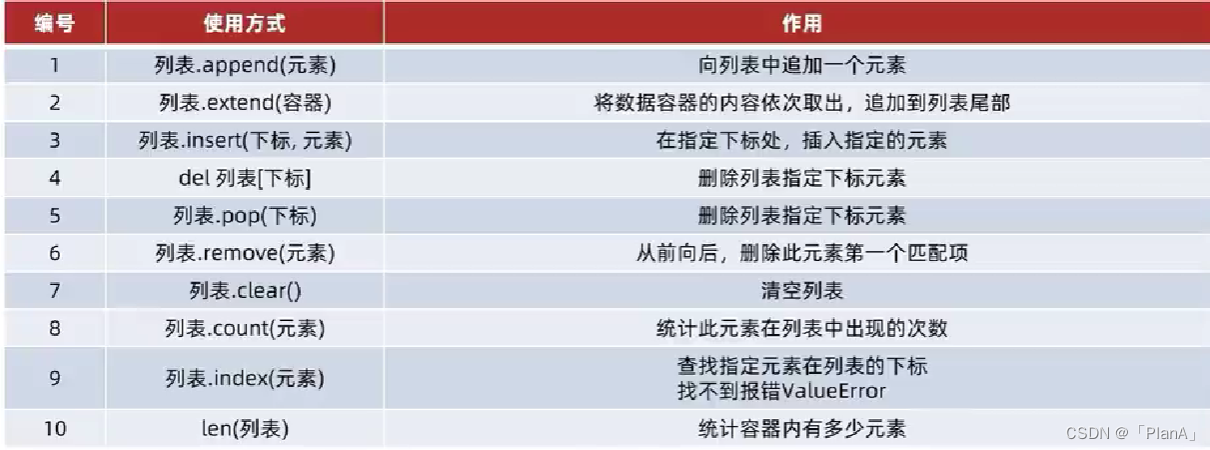
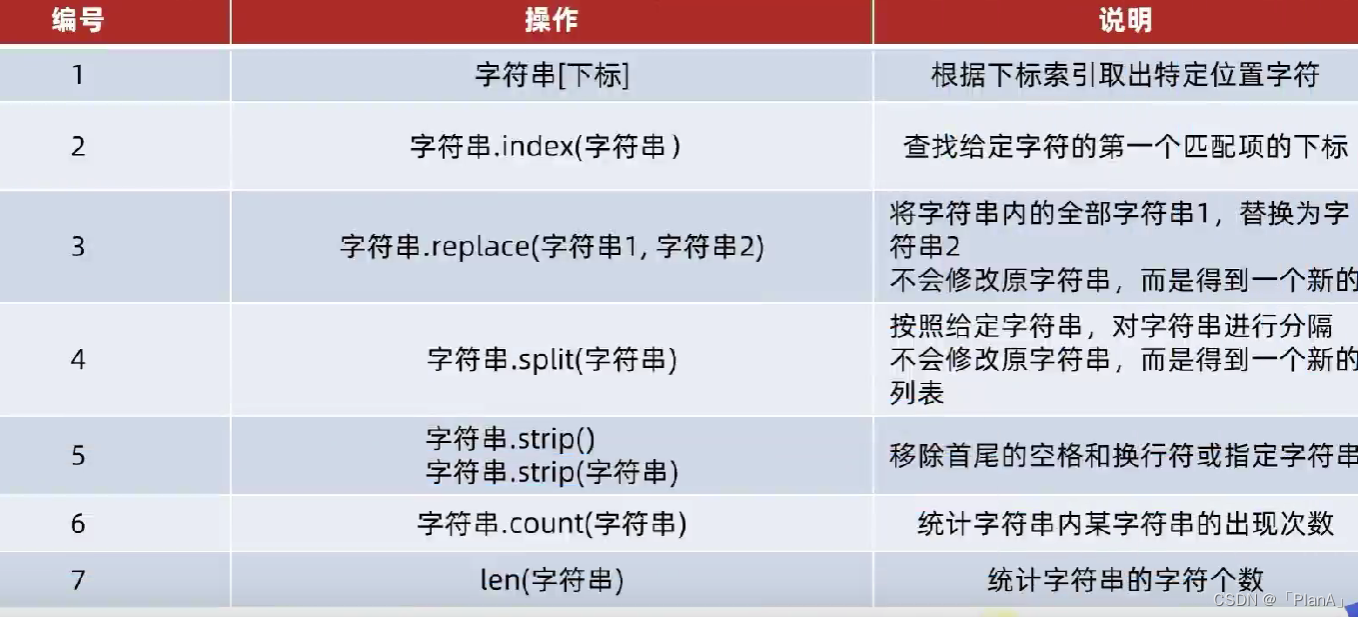
列表常用的操作方法如下:
1.4 遍历List列表
既然数据容器可以存储多个元素,那么,就会有需求从容器内依次取出元素进行操作。将容器内的元素依次取出进行处理的行为,称之为:遍历、迭代。
我么可以使用前面学过的while与for循环语句实现对列表的遍历。
代码示例
def list_while_func():
"""
使用while循环遍历列表
:return:None
"""
my_list = ['KLJ','LKI','ASF','HYT']
index = 0
while index < len(my_list):
temp = my_list[index]
print(f"列表元素:{temp}")
index += 1
def list_for_func():
"""
使用for循环遍历列表
:return: None
"""
mylist = [1,2,3,4,5,6]
for index in mylist:
print(f"列表的元素:{index}")
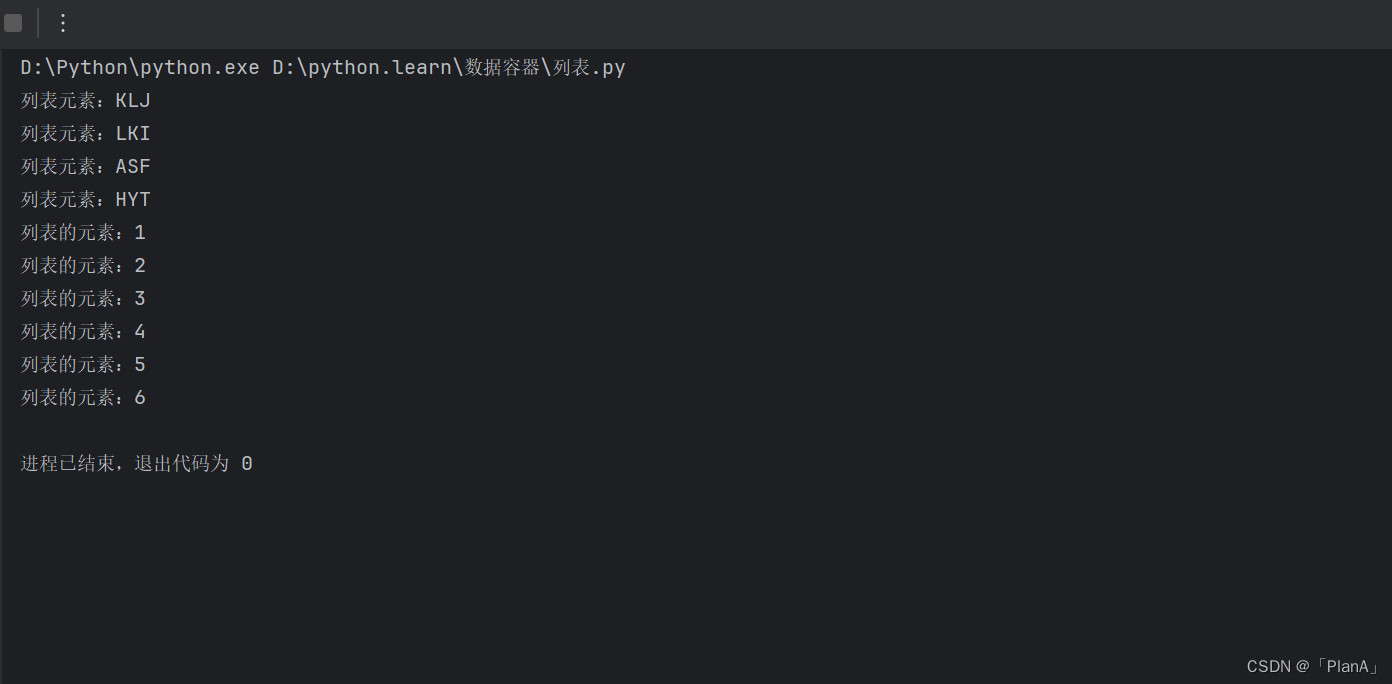
list_while_func()
list_for_func()运行效果

二 元组
为什么需要元组?
前面我们已经学习了列表,知道了列表是可以修改的,那么我们想要有效的传递信息并且不能被修改,列表就不适合了。
元组同列表一样,都是可以封装多个,不同类型的元素在内。但最大的不同点在于:
元组一旦定义完成,就不可以修改。
2.1 元组的定义

代码示例
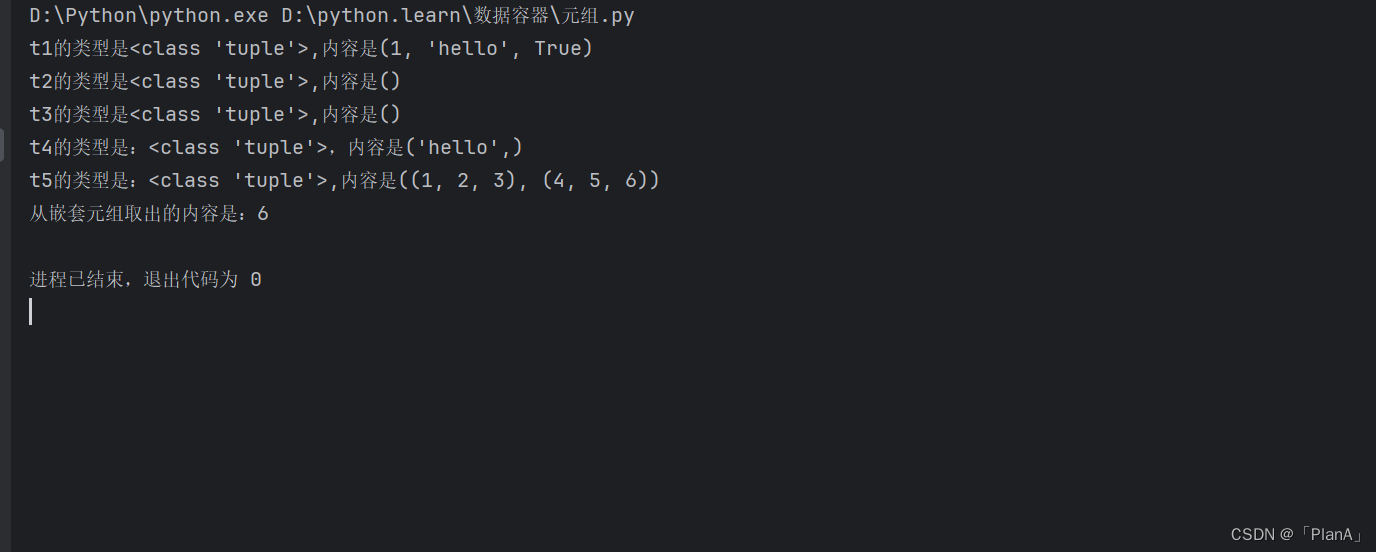
# 定义元组
t1 = (1,"hello",True)
t2 = ()
t3 = tuple()
print(f"t1的类型是{type(t1)},内容是{t1}")
print(f"t2的类型是{type(t2)},内容是{t2}")
print(f"t3的类型是{type(t3)},内容是{t3}")
# 定义单个元素的元组
t4 = ("hello",)
print(f"t4的类型是:{type(t4)},内容是{t4}")
# 元组的嵌套
t5 = ((1,2,3),(4,5,6))
print(f"t5的类型是:{type(t5)},内容是{t5}")
# 下标索引去取出内容
num = t5[1][2]
print(f"从嵌套元组取出的内容是:{num}")运行效果
2.2 元组的操作

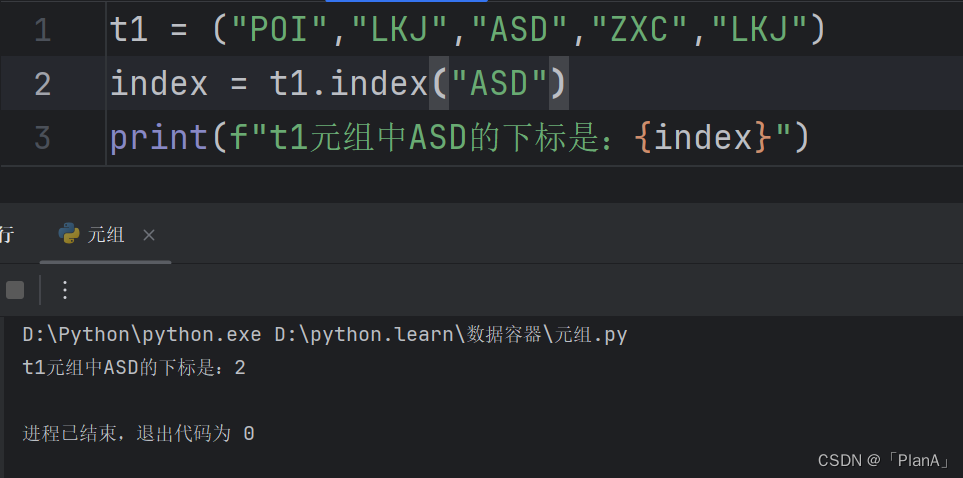
【元组查找功能】
查找某元素的下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:元组.index(元素)
方法演示:
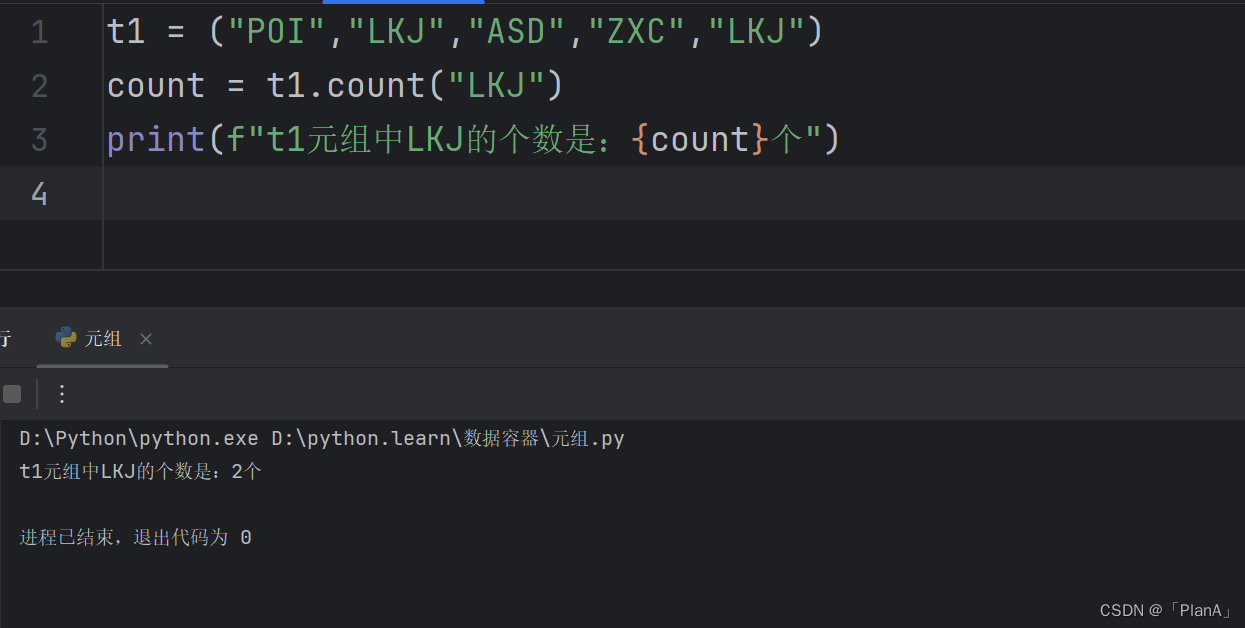
【元素在元组内的数量】
语法:元组.count(元素)
功能:统计指定元素在列表中的数量。
方法演示:
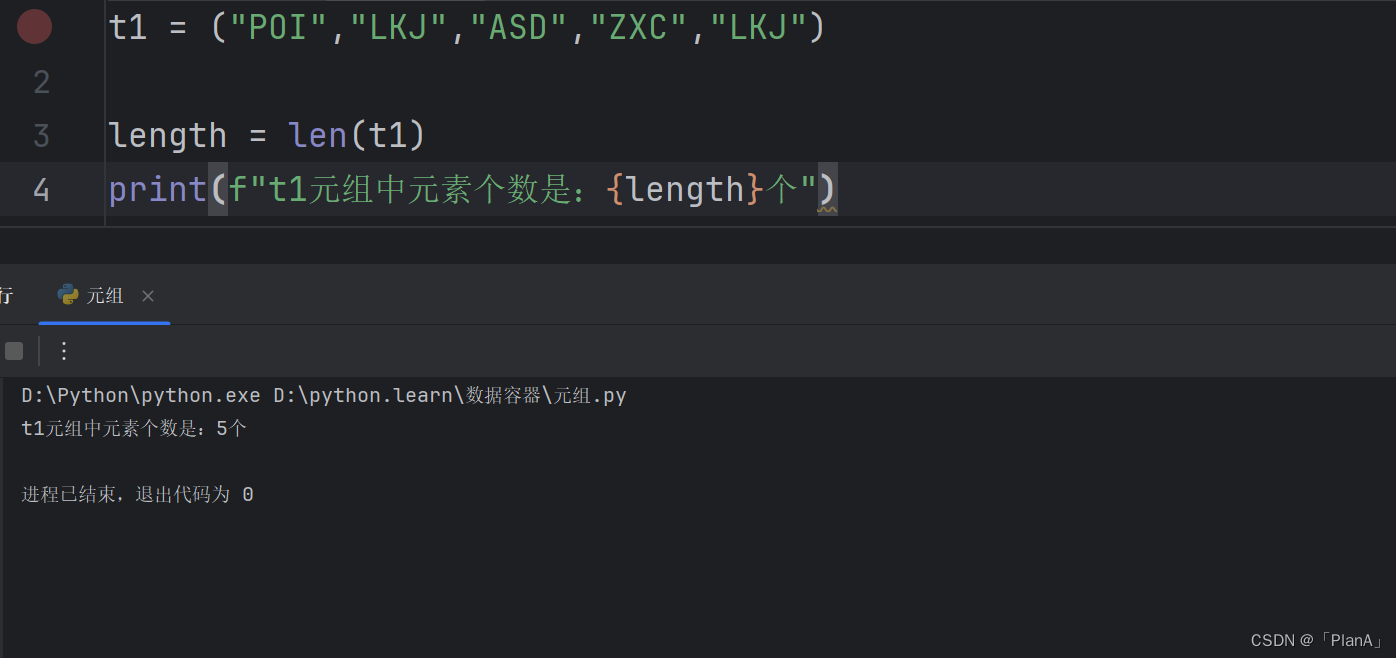
【统计元组中的总元素个数】
语法:len(列表)
功能:统计列表中元素的个数
方法演示:
注意:
元组的内容是不可以进行修改的,如果元组里面在嵌套一个列表,那么可以修改。元组的元素不可以修改,也就是元组里面的列表类型不可以修改,但列表里面的元素可以进行修改。
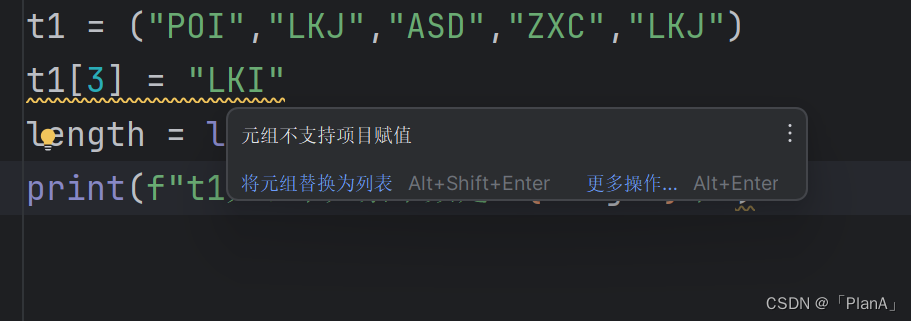
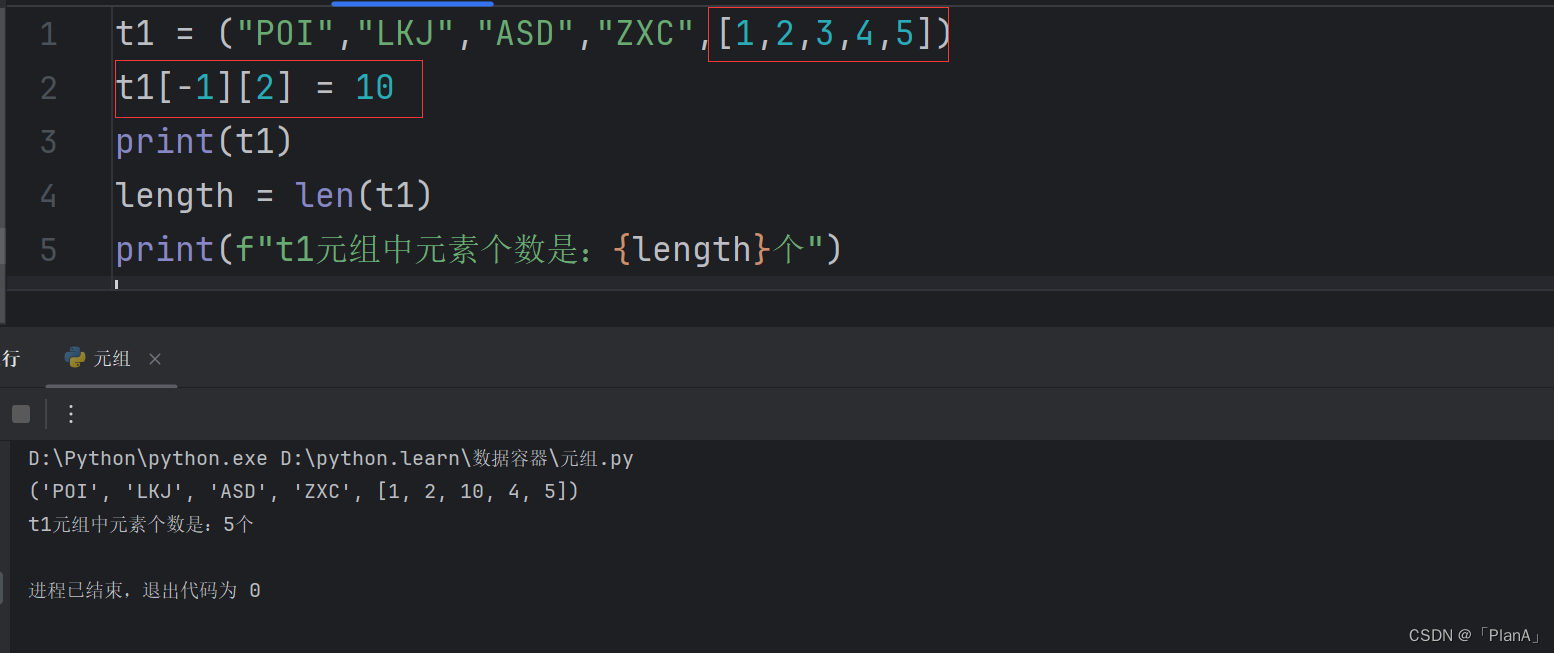
【元组的操作实践练习】
t1 = ('周杰伦',11,['football','music'])
index = t1.index(11)
print(f"年龄所在的下标为:{index}")
name = t1[0]
print(f"学生的姓名为:{name}")
del t1[-1][0]
print(t1)
t1[-1].append('coding')
print(t1)
三 字符串
3.1 字符串
字符串是字符的容器,一个字符串可以存放任意数量的字符。
比如字符串:“itheima”
和其他容器一样。字符串也可以通过下标进行访问:
从前向后:下标从0开始
从后向前:下标从-1开始
同元组一样,字符串是一个:无法修改的数据容器。
所以,修改字符串,移除指定元素,追加字符等都是无法完成的,即使实现了也是生成了一个新的字符串。

3.2 字符串的操作
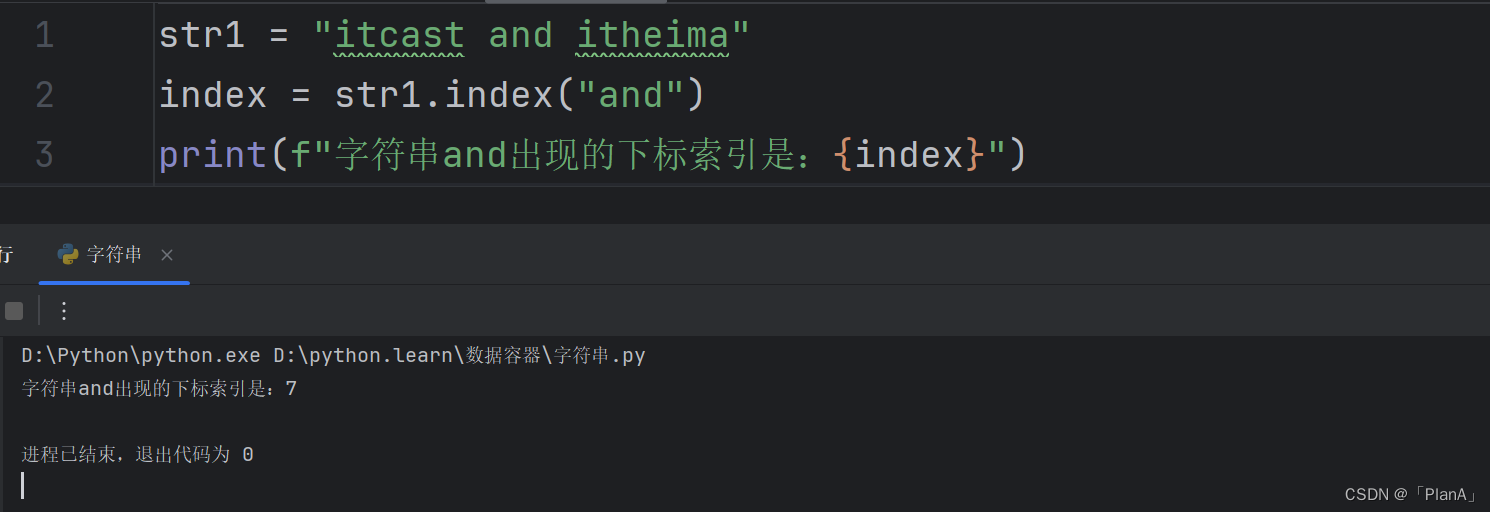
【查找特定字符串的下标】
语法:字符串.index(字符串)
功能:得到子字符串在字符串中首字母出现的下标索引
方法演示:
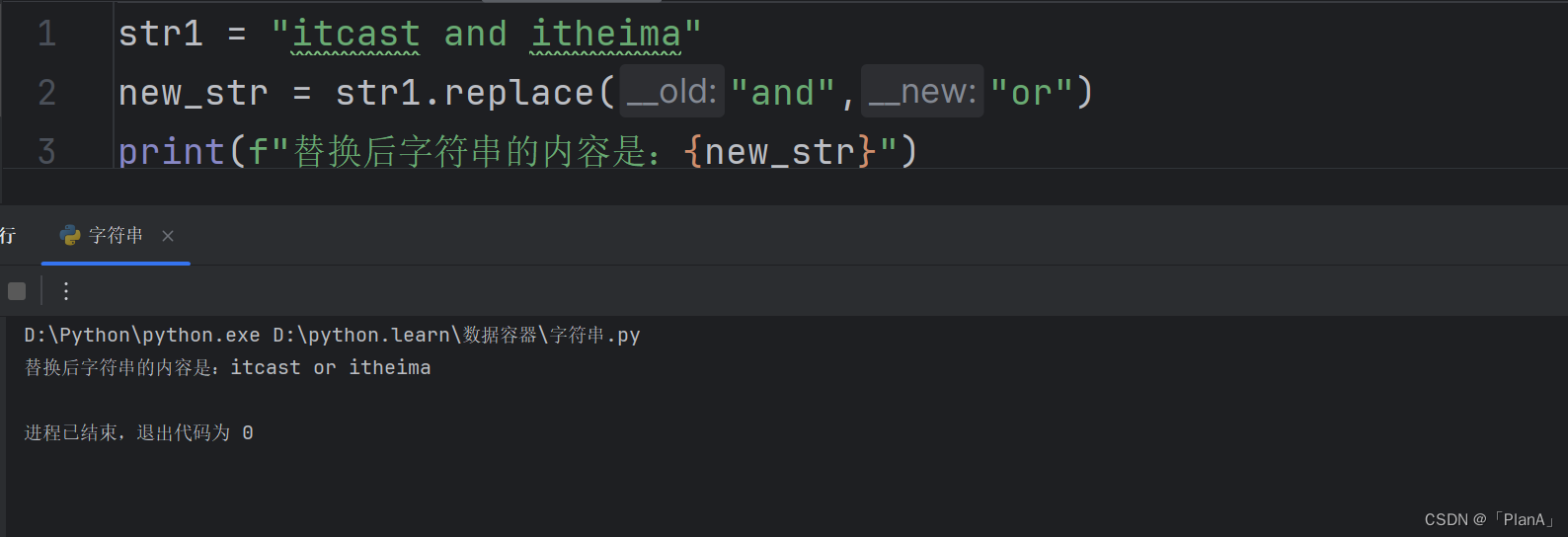
【字符串的替换】
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新的字符串
方法演示:
【字符串的分割】
语法:字符串.split(分隔符字符串)
功能:按照指定的分割符字符串,将字符串划分为多个字符串,并存入列表对象中。
注意:字符串本身不变,而是得到了一个列表对象。
方法演示:

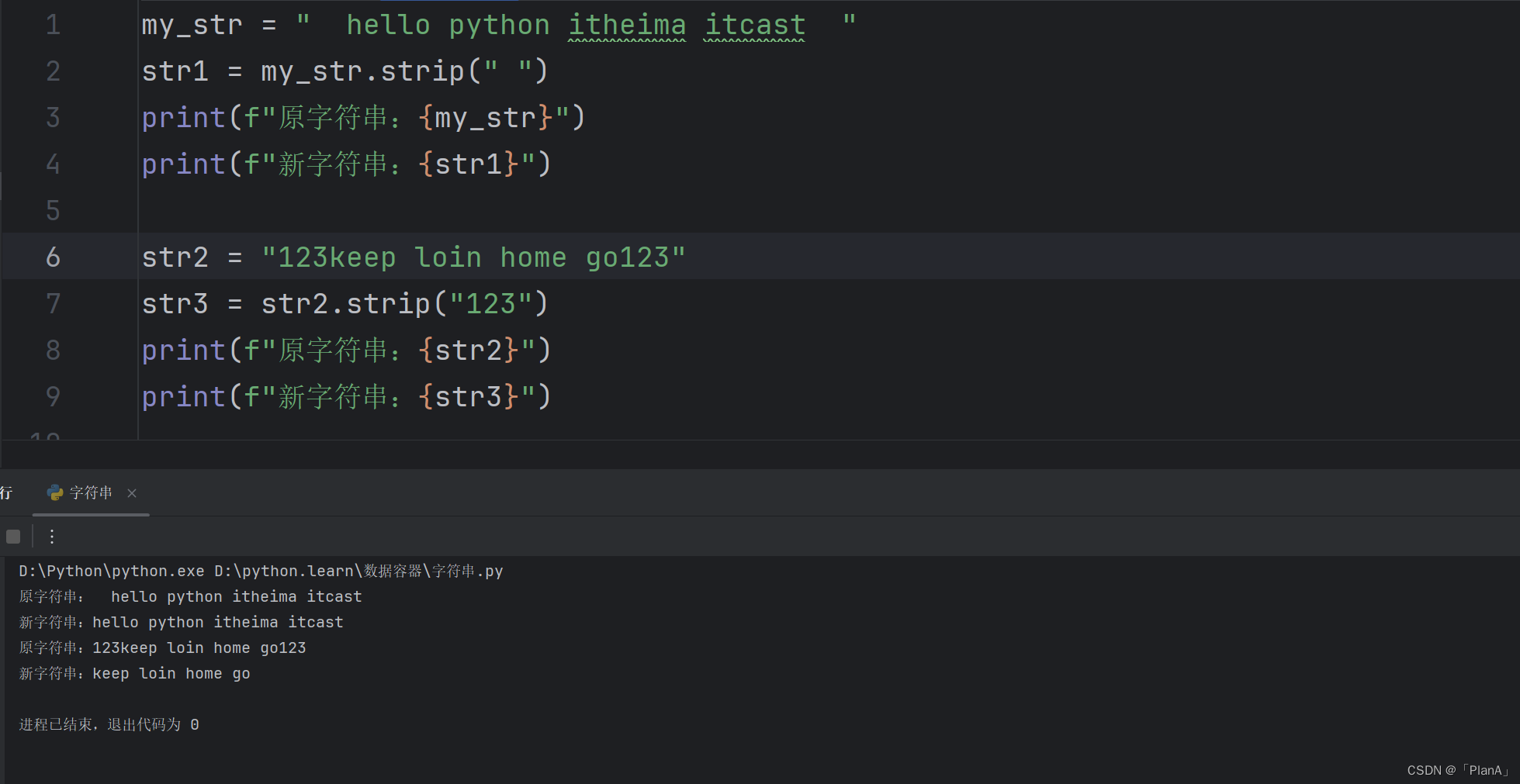
【字符串的规整操作】
语法1:字符串.strip()
功能:取出字符串前后空格
语法2:字符串.strip(字符串)
功能:去除前后指定字符串
方法演示:
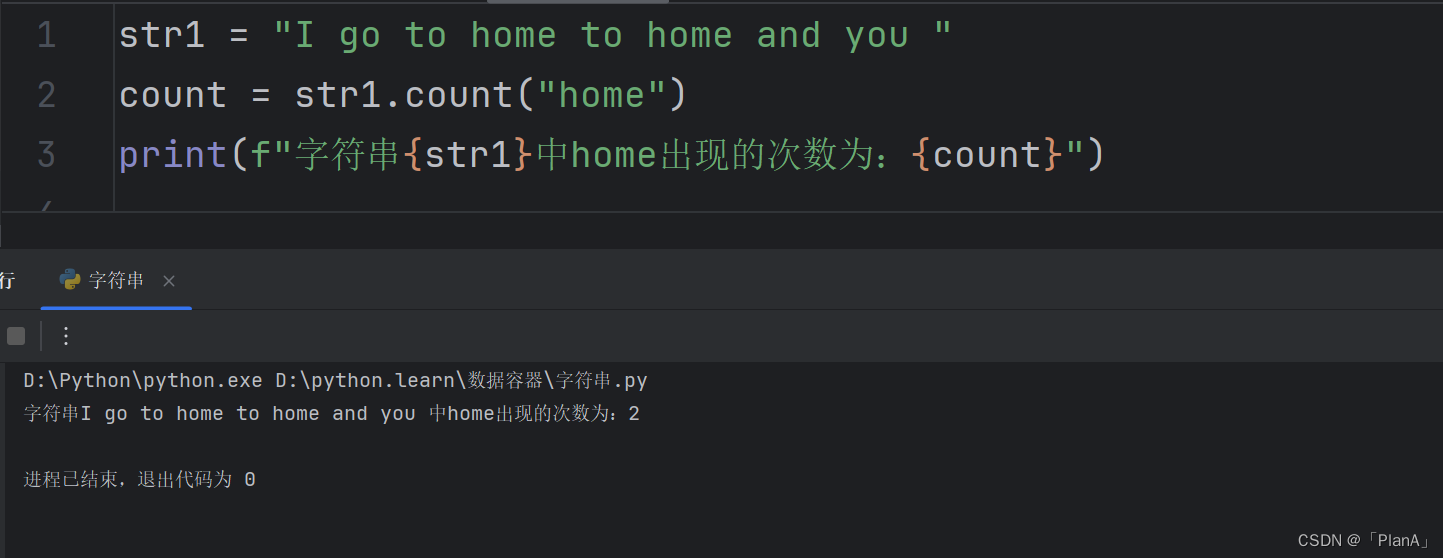
【统计子字符串出现的次数】
语法:字符串.count(字符串)
方法演示:
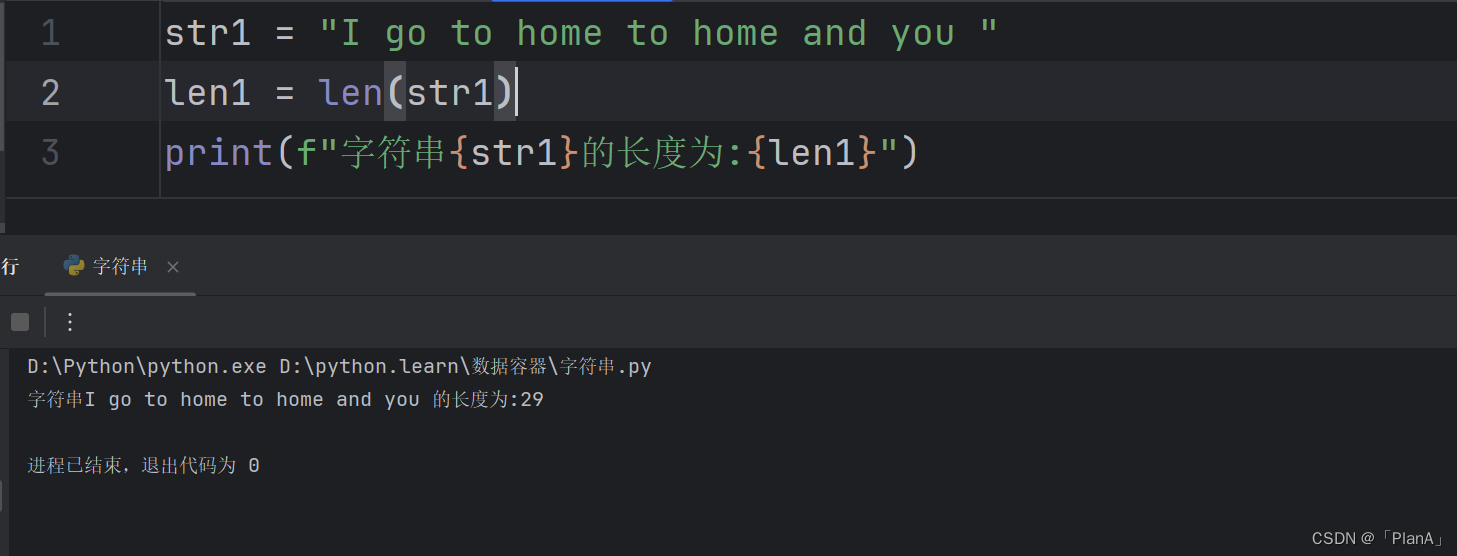
【获取字符串的长度】
语法:len(字符串)
方法演示:
四 数据容器(序列)的切片
序列的常用操作------切片
序列支持切片,即:列表,元组,字符串,均支持进行切片操作。
切片:从一个序列中取出一个子序列。
语法:序列【起始下标:结束下标:步长】
功能:表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾步长表示,依次取元素的间隔
步长1表示,一个个取元素
步长2表示,每次跳过1个元素取·步长N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)注意:切片操作不影响序列本身,而是生成了一个新的序列。
序列切片使用方式
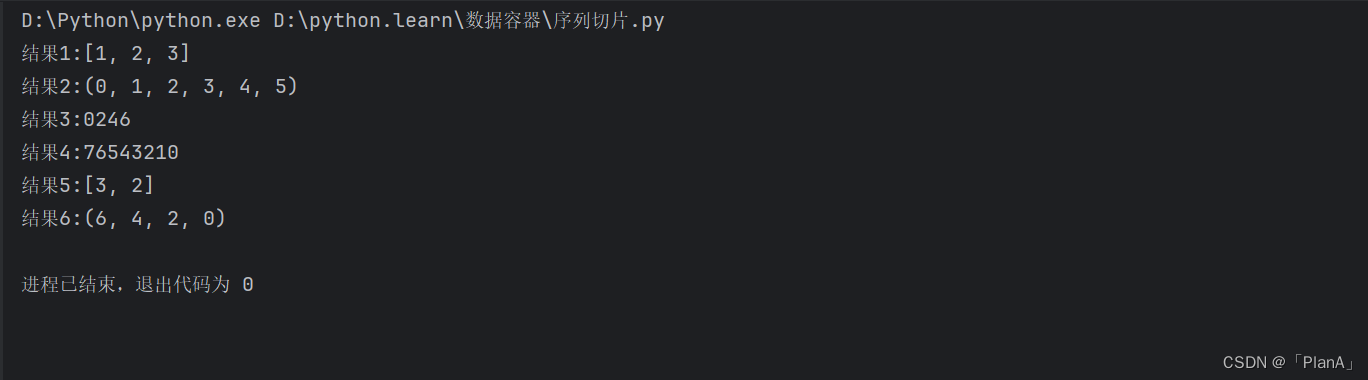
mylist = [0,1,2,3,4,5,6]
result = mylist[1:4] # 省略步长,默认步长为1
print(f"结果1:{result}")
my_tuple = (0,1,2,3,4,5)
result2 = my_tuple[:] # 起始和结束的下标省略,步长默认为1
print(f"结果2:{result2}")
my_str = "0123456"
result3 = my_str[::2]
print(f"结果3:{result3}")
my_str1 = "01234567"
result4 = my_str1[::-1] # 等同于将序列反转
print(f"结果4:{result4}")
my_list = [0,1,2,3,4,5,6]
result5 = my_list[3:1:-1]
print(f"结果5:{result5}")
my_tuple = (0,1,2,3,4,5,6)
result6 = my_tuple[::-2]
print(f"结果6:{result6}")
运行效果
五 集合
为什么使用集合?
通过我们前面学习的数据容器可以发现:
列表可修改,支持重复元素且有序元组,字符串不可修改,支持重复元素且有序
我们可以发现他们的共同点是:都支持元素重复。
如果我们想要达到去重的效果,那么上面的数据容器都不适合。
因此我们引入集合这一个概念。
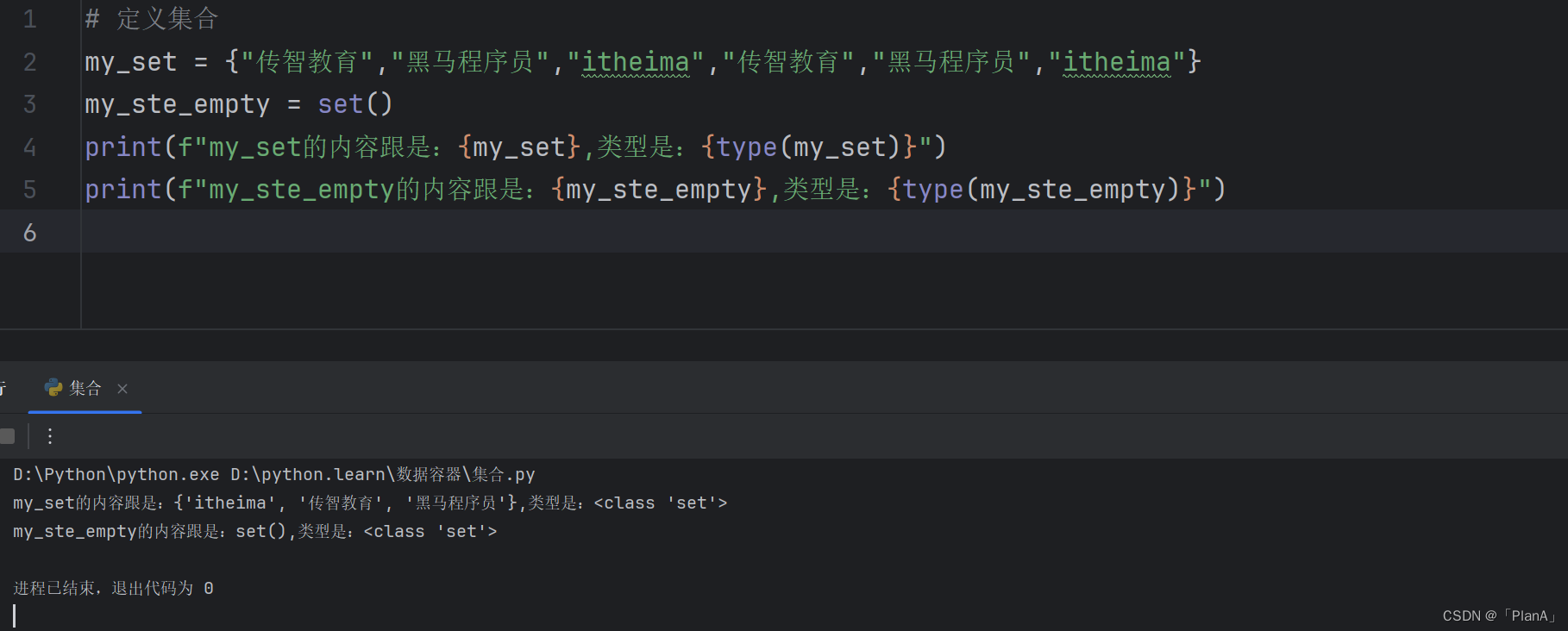
5.1 集合的定义
和列表,元组,字符串的定义相同:
列表使用:【】元组使用:()
集合使用:{}
5.2 集合的操作
首先,因为集合是无序的,所以集合不支持:下标索引访问。但是集合和列表一样,是允许修改的。
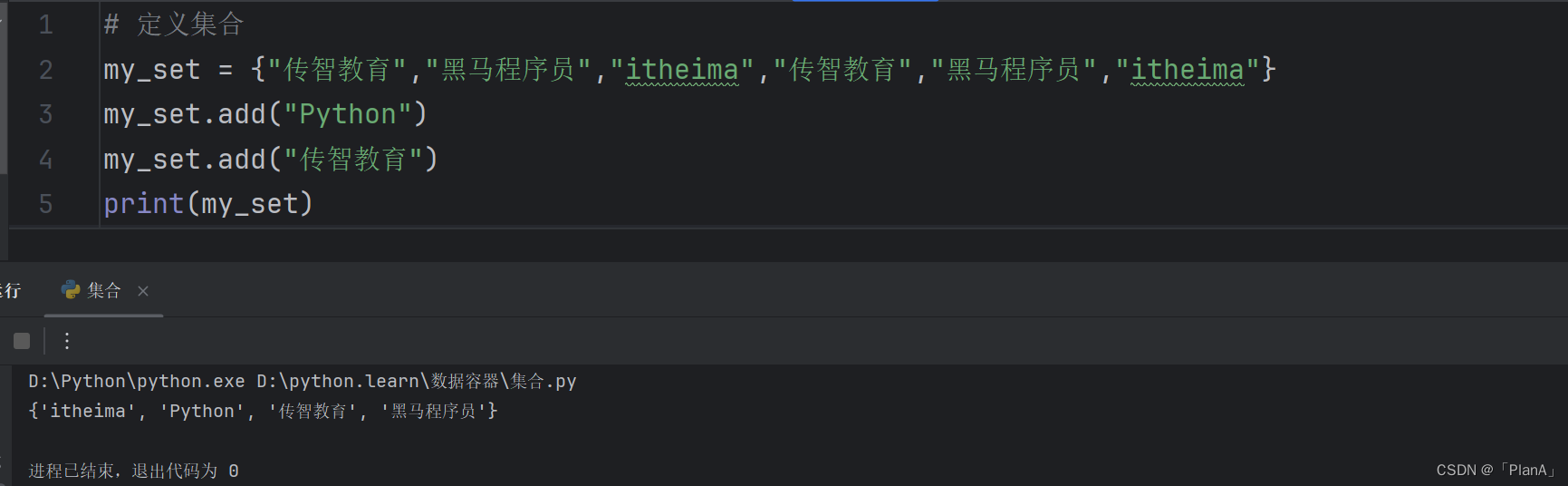
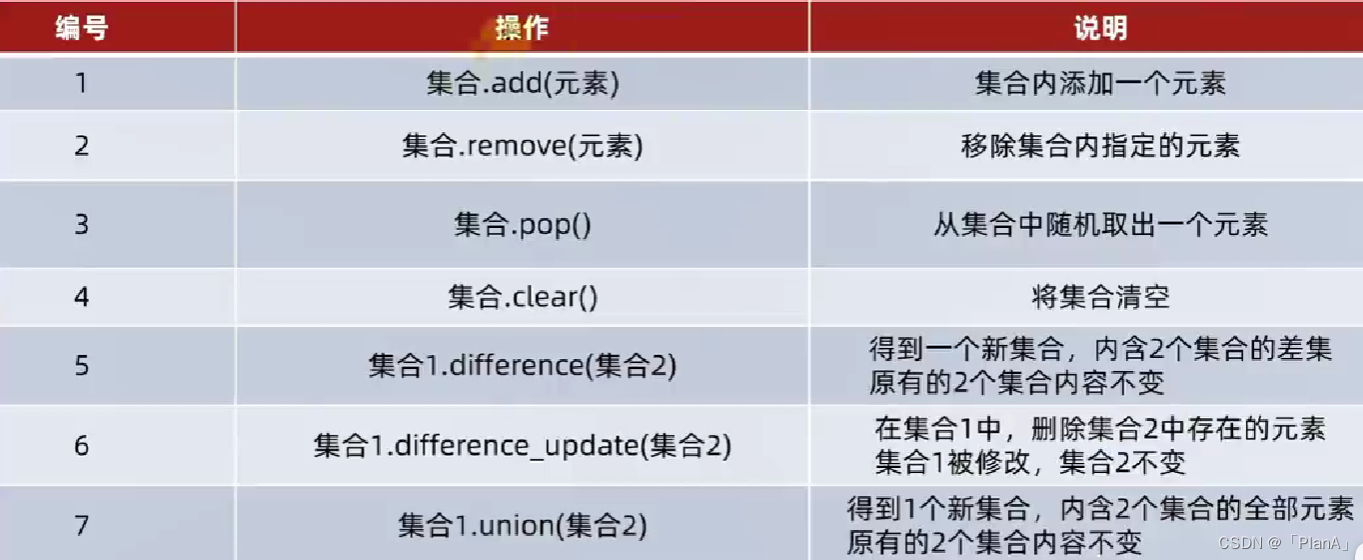
【添加新元素】
语法:集合.add(元素)
功能:将指定元素添加到集合内。
结果:集合本身被修改,添加了新元素
方法演示:
【移除元素】
语法:集合.remove(元素)
功能:将指定元素从集合内部移除
结果:集合本身被修改,移除了元素
方法演示:
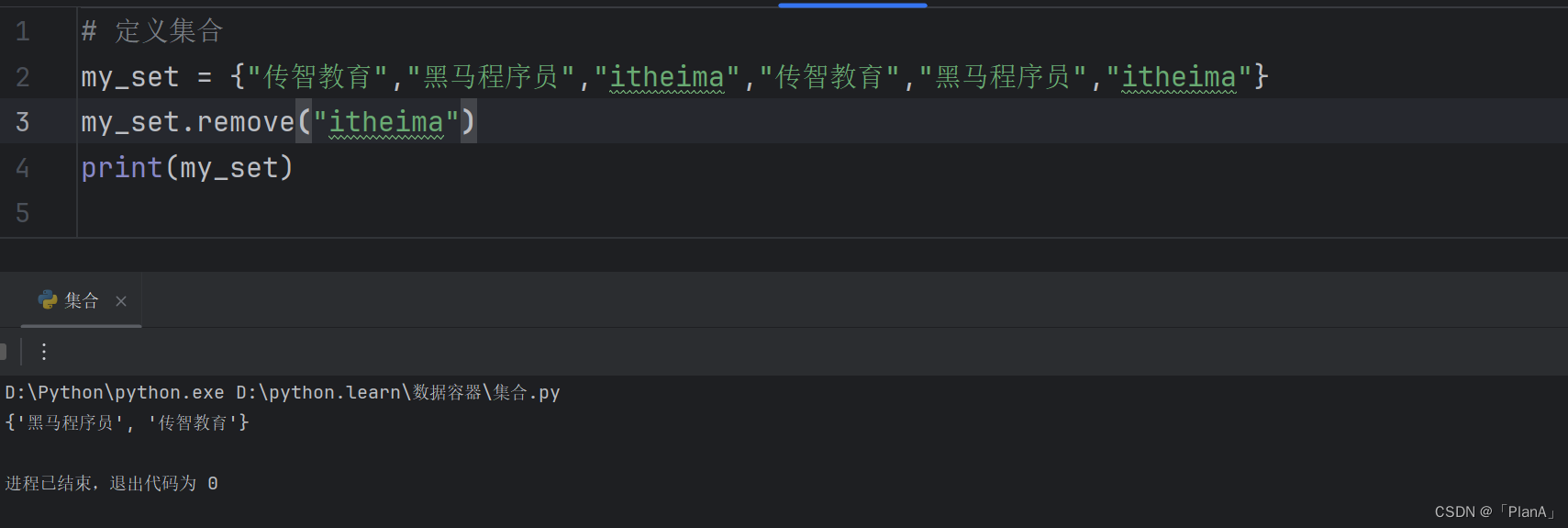
【从集合中随机取出元素】
语法:集合.pop()
功能:从集合中取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
方法演示:
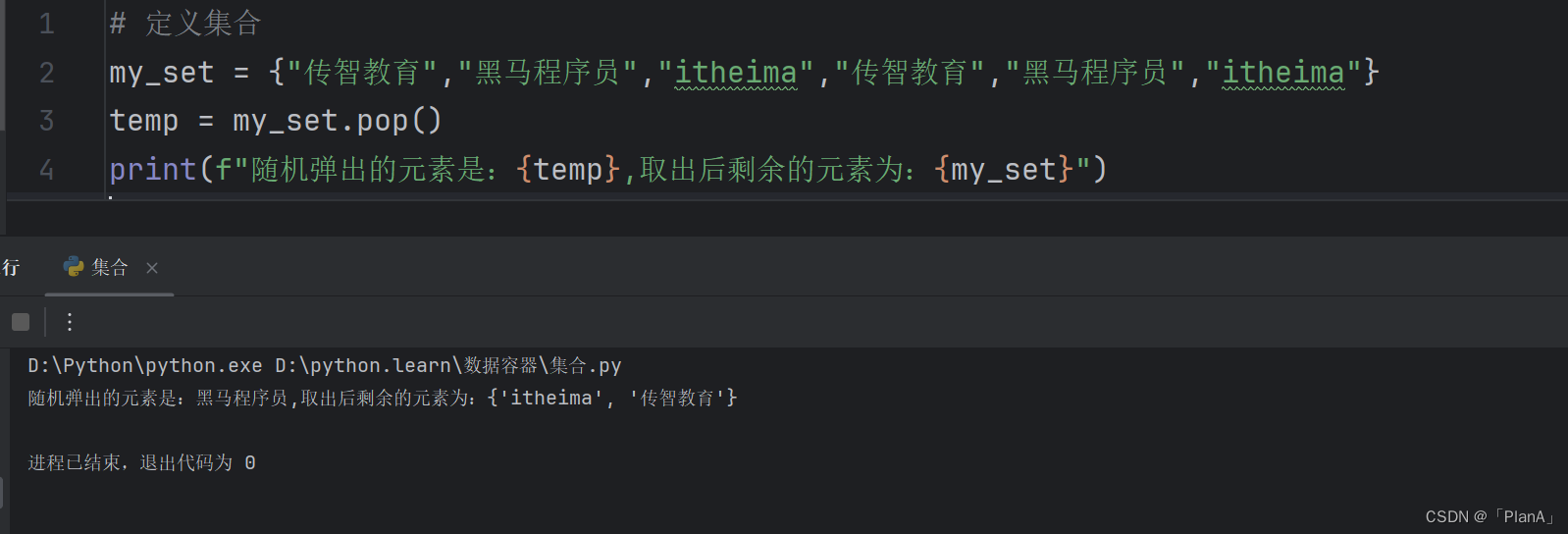
【清空集合】
语法:集合.clear()
功能:清空集合
结果:集合被清空
方法演示:
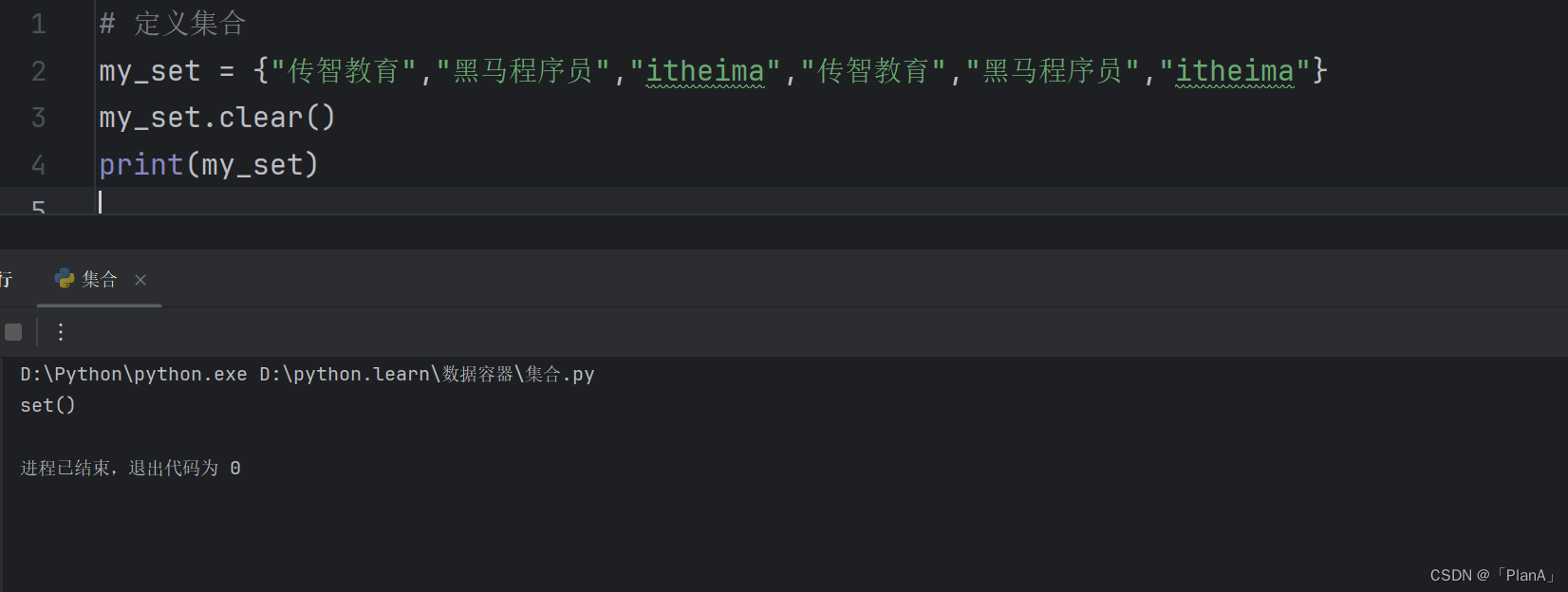
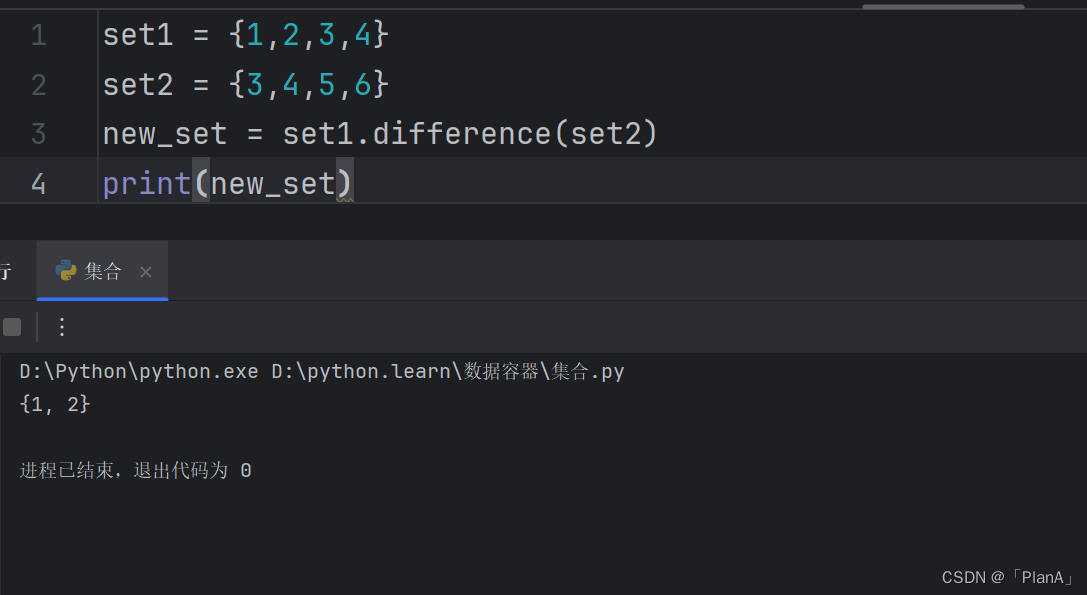
【取两个集合的差集】
语法:集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有集合2没有)
结果:得到一个新发集合,原来的集合1与集合2不变
方法演示:
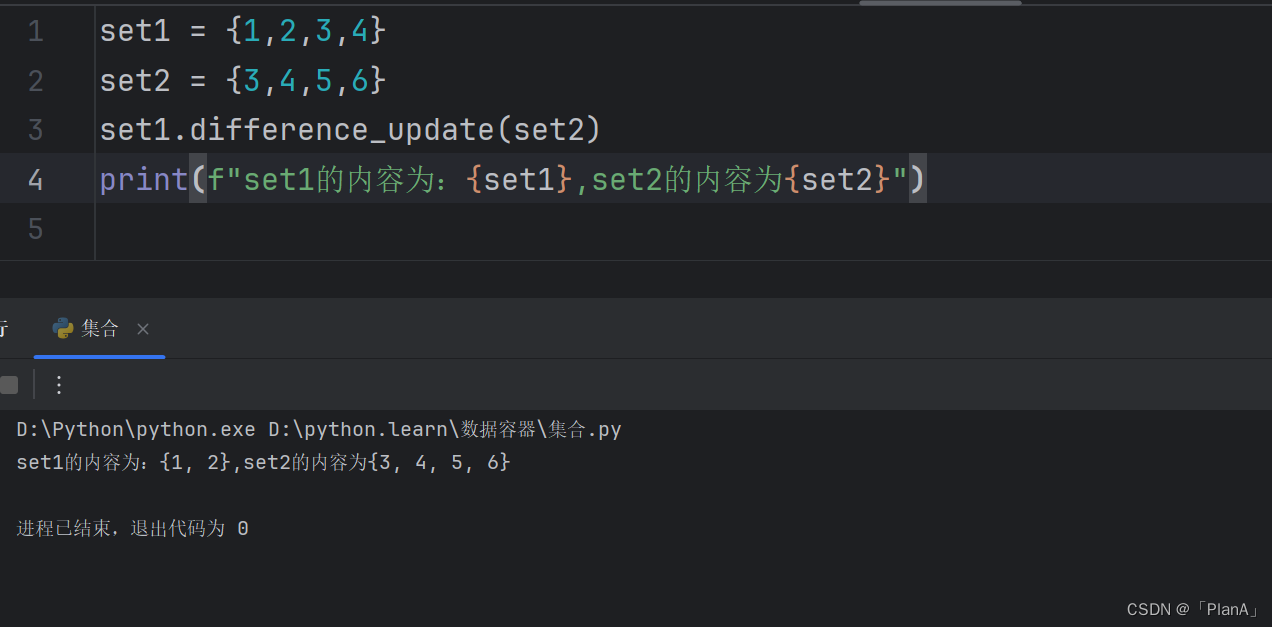
【消除两个集合的差集】
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变
方法演示:
【两个集合合并】
语法:集合1.union(集合2)
功能:将集合1与集合2组成新集合
结果: 得到新集合,集合1和集合2不变
方法演示:

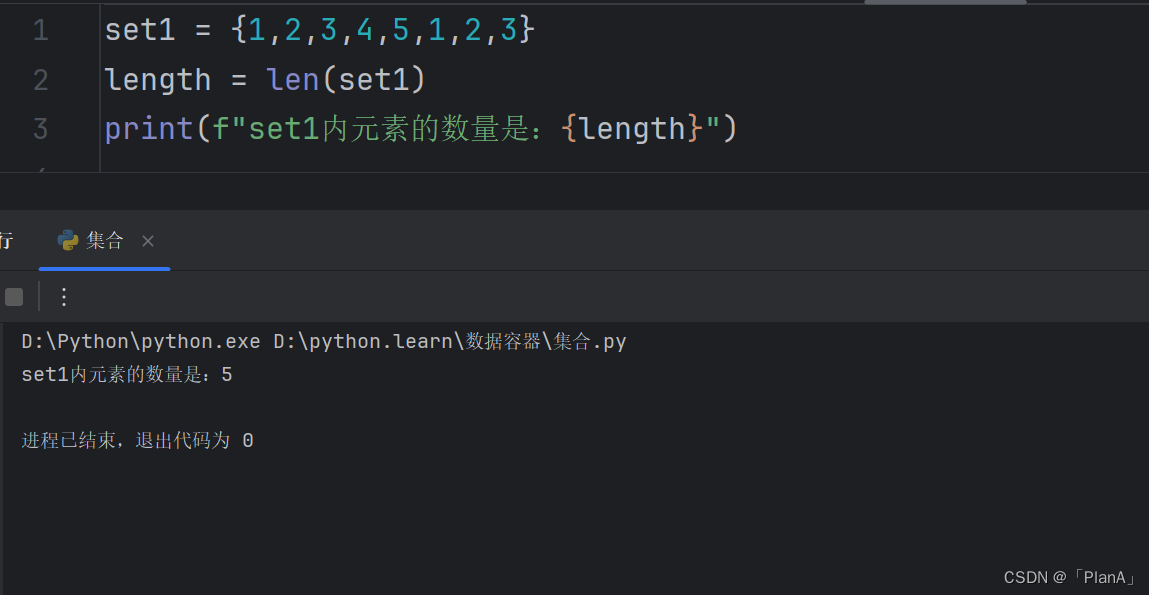
【统计集合元素的数量】
语法:len(集合)
功能:得到集合内元素的数量
方法演示:
总结:
集合的遍历:
由于集合不支持下标索引,因此遍历集合时我们无法使用while语句,只能使用for语句。
六 字典
为什么使用字典?
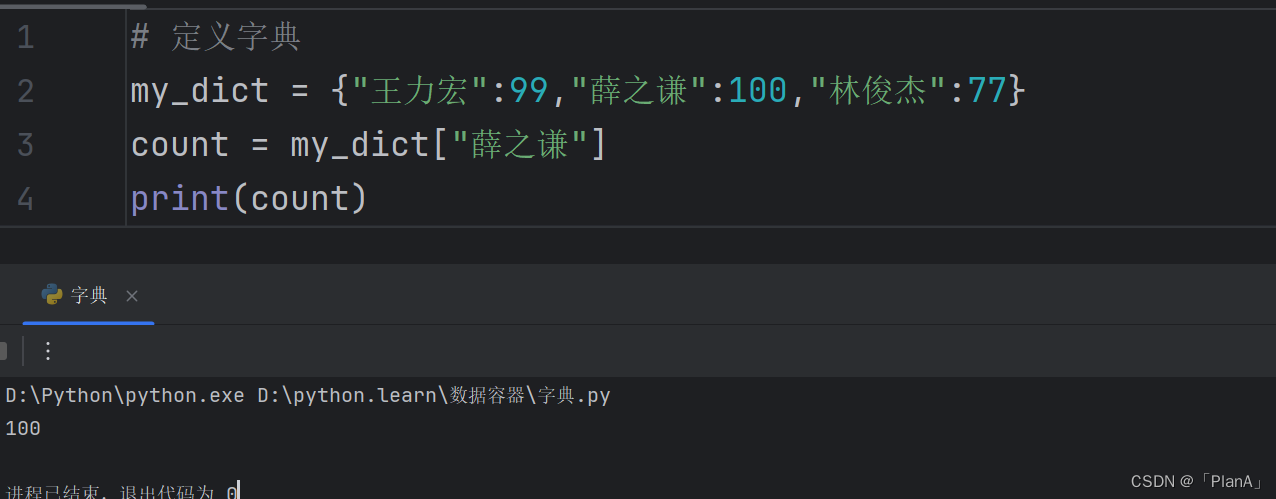
我们知道我们生活中使用字典是为了通过查找某一个字来找到它的意思或者含义。Python中也有相应的,python中通过key与value对应实现查找功能。
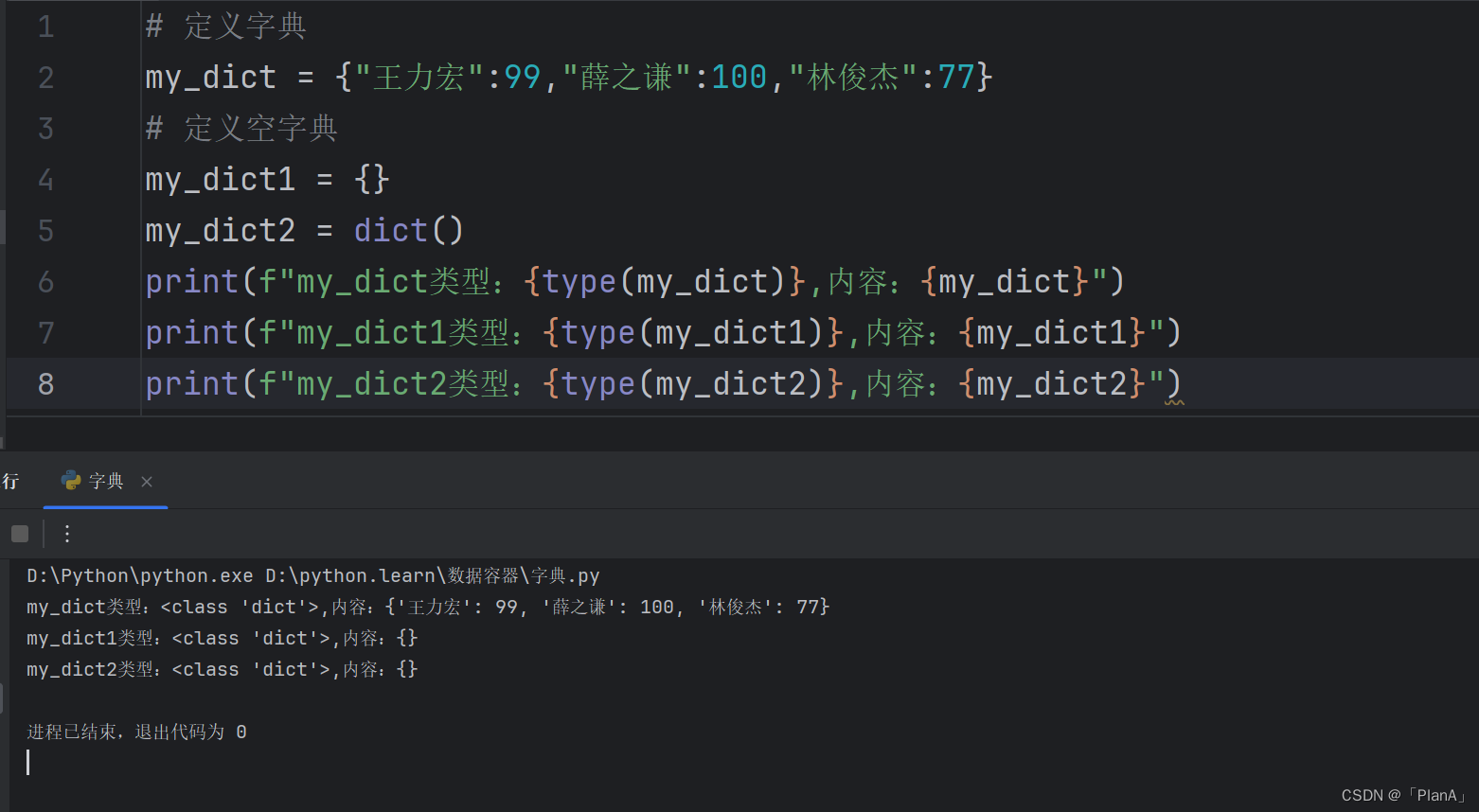
6.1 字典的定义

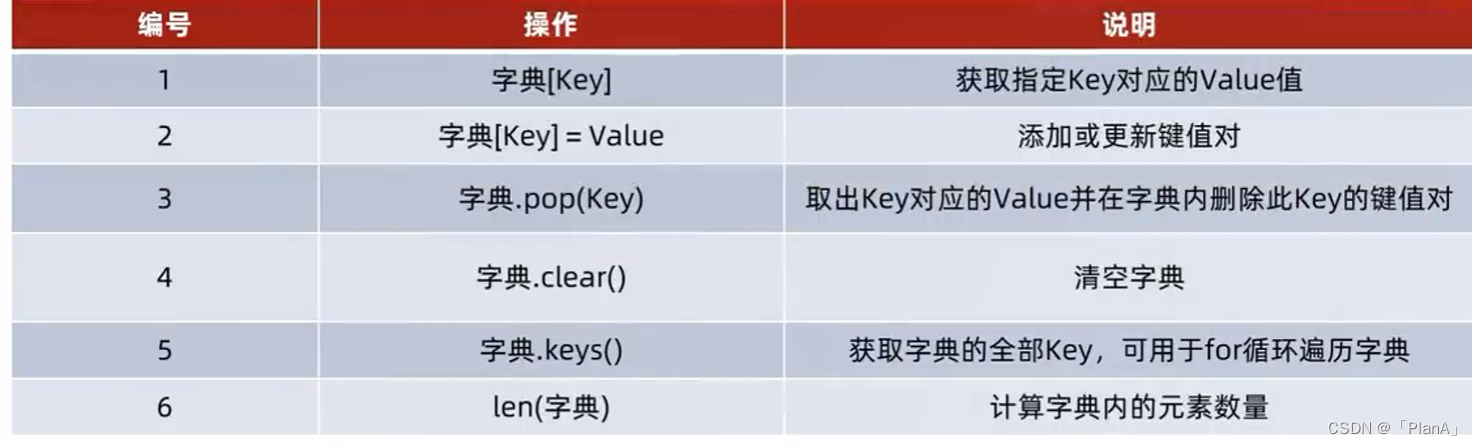
注意:字典内是不允许 key值重复的,新的key值会把原来的key值覆盖掉。字典也是没有下标索引的。但是字典可以通过key值获得相应的value.
字典的嵌套
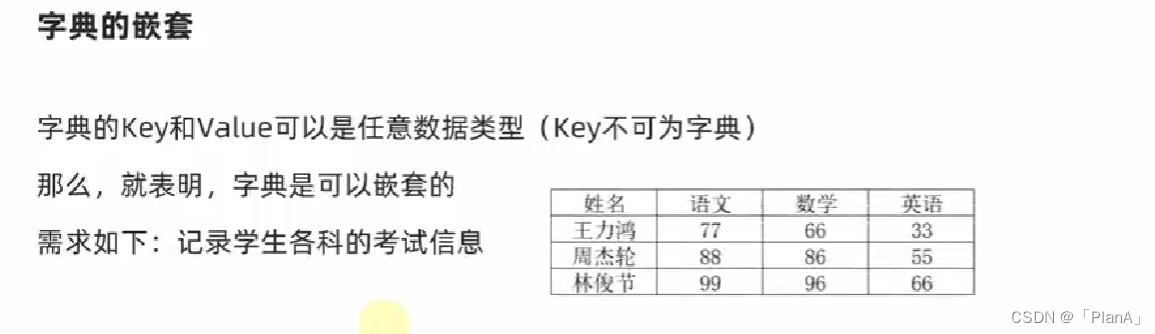
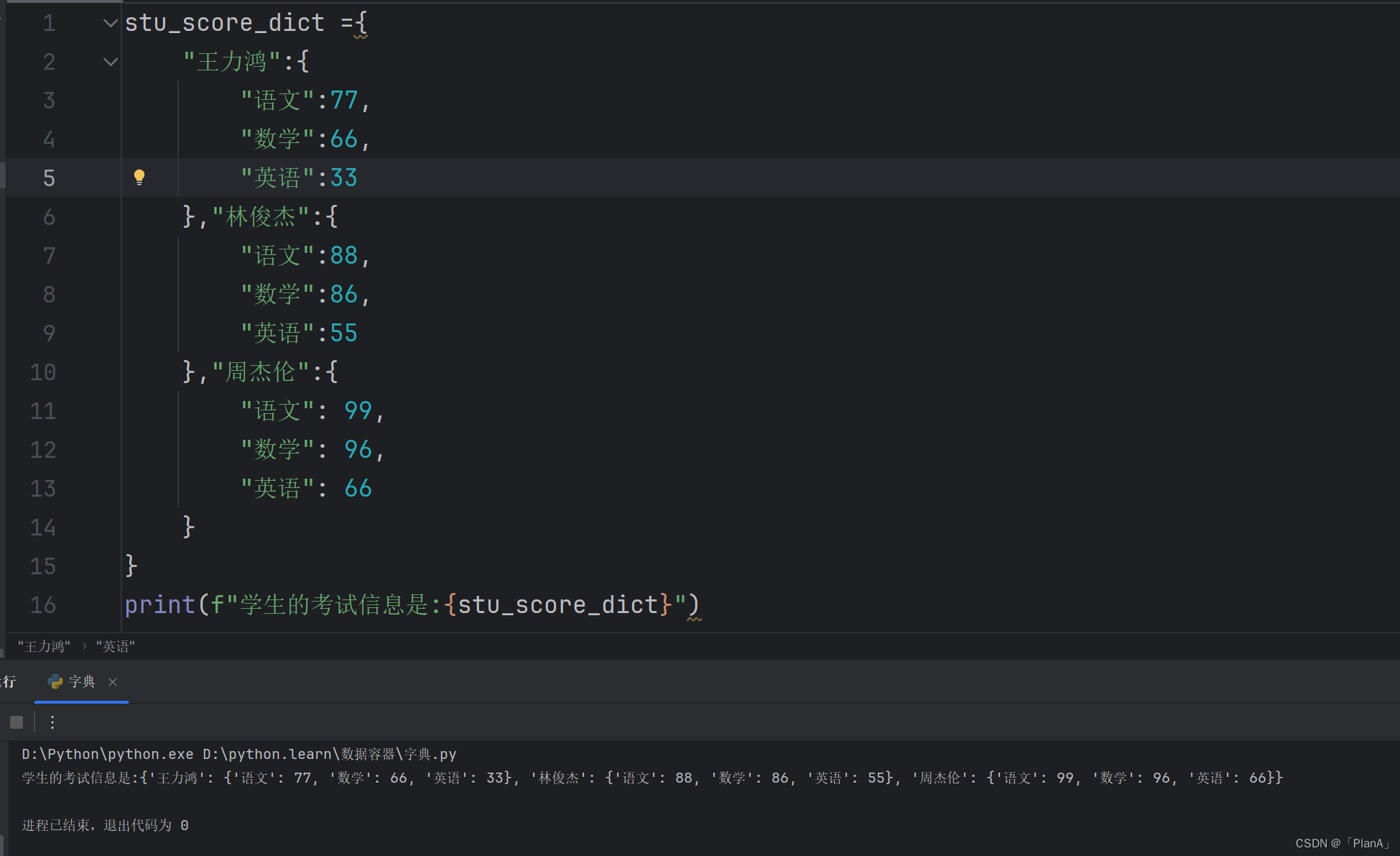
设计如下:使用字典的嵌套
6.2 字典的操作
【新增元素】
语法:字典【key】=value
结果:字典被修改,新增了元素
方法演示:

【更新元素】
语法:字典【key】= value
结果:字典被修改,元素被更新
注意:字典key的值不可以重复,所以对已经存在key执行上述操作,就是更新Value的值。
方法演示:

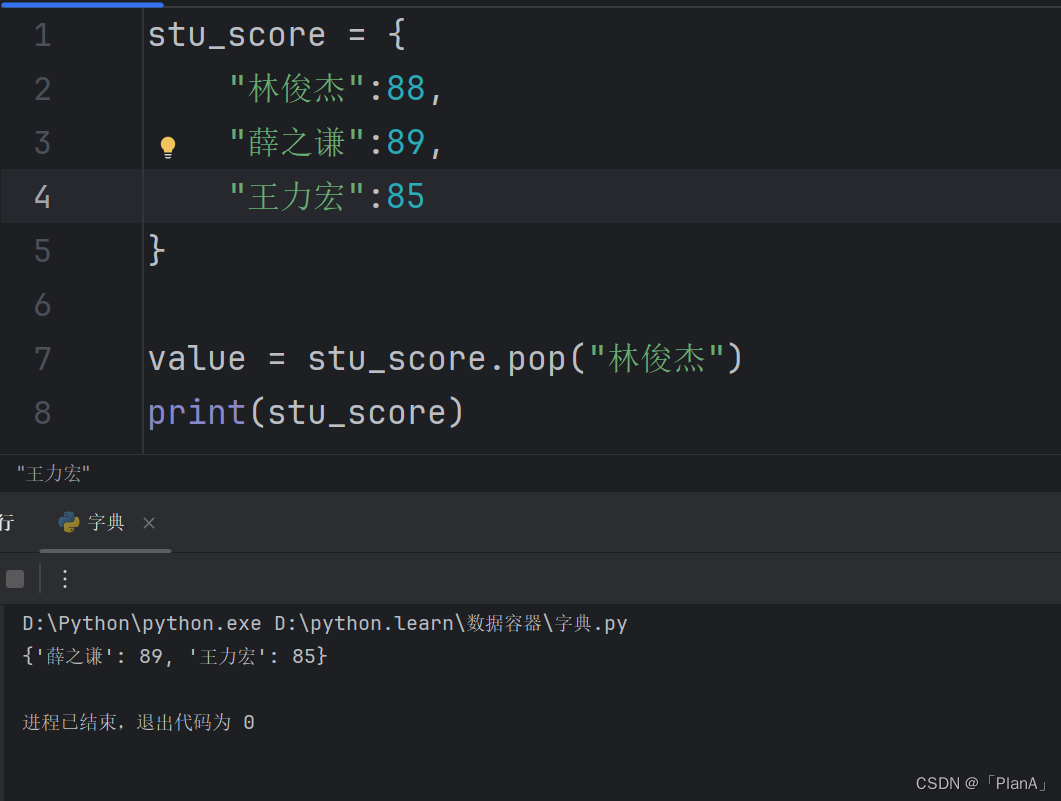
【删除元素】
语法:字典pop(key)
结果:获得指定key的value,同时字典被修改,指定Key的数据被删除
方法演示:
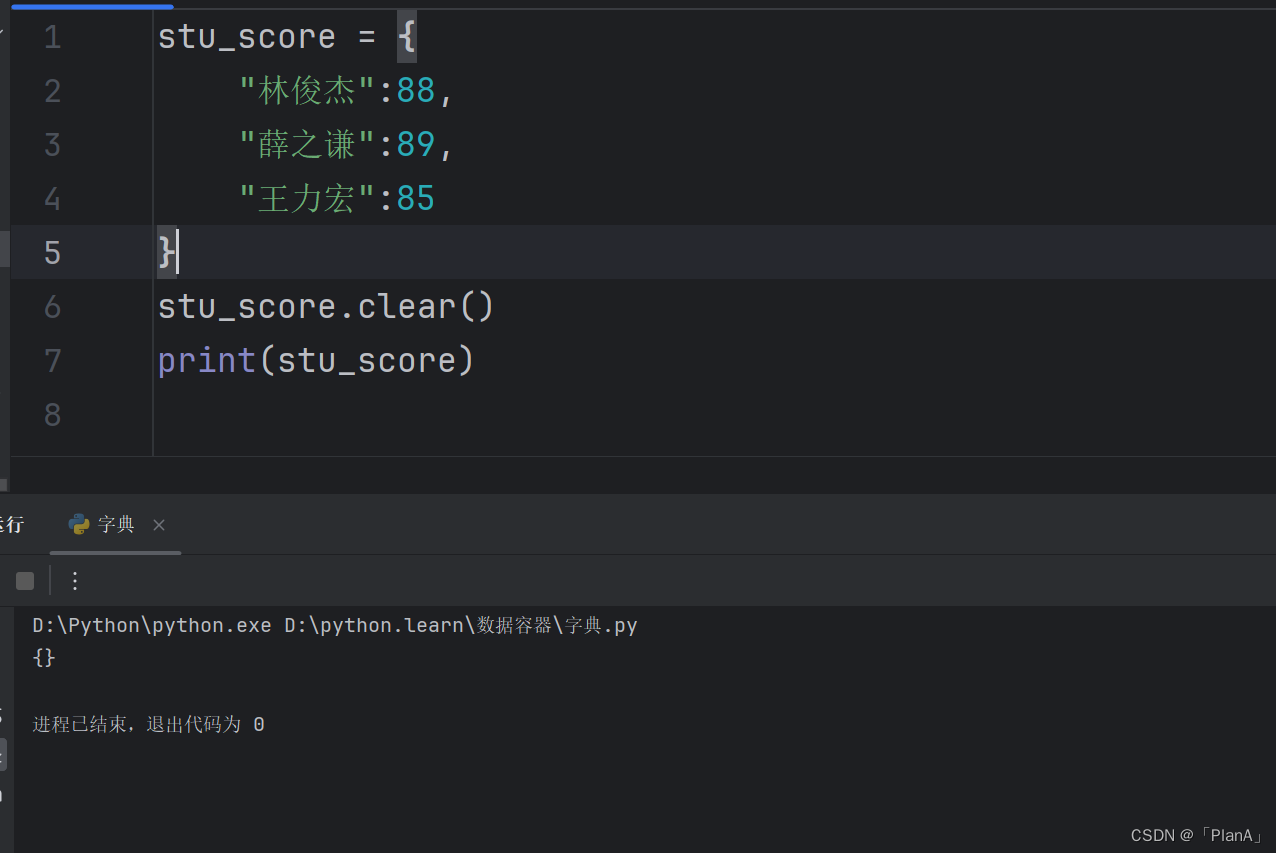
【清空字典】
语法:字典.clear()
方法演示:
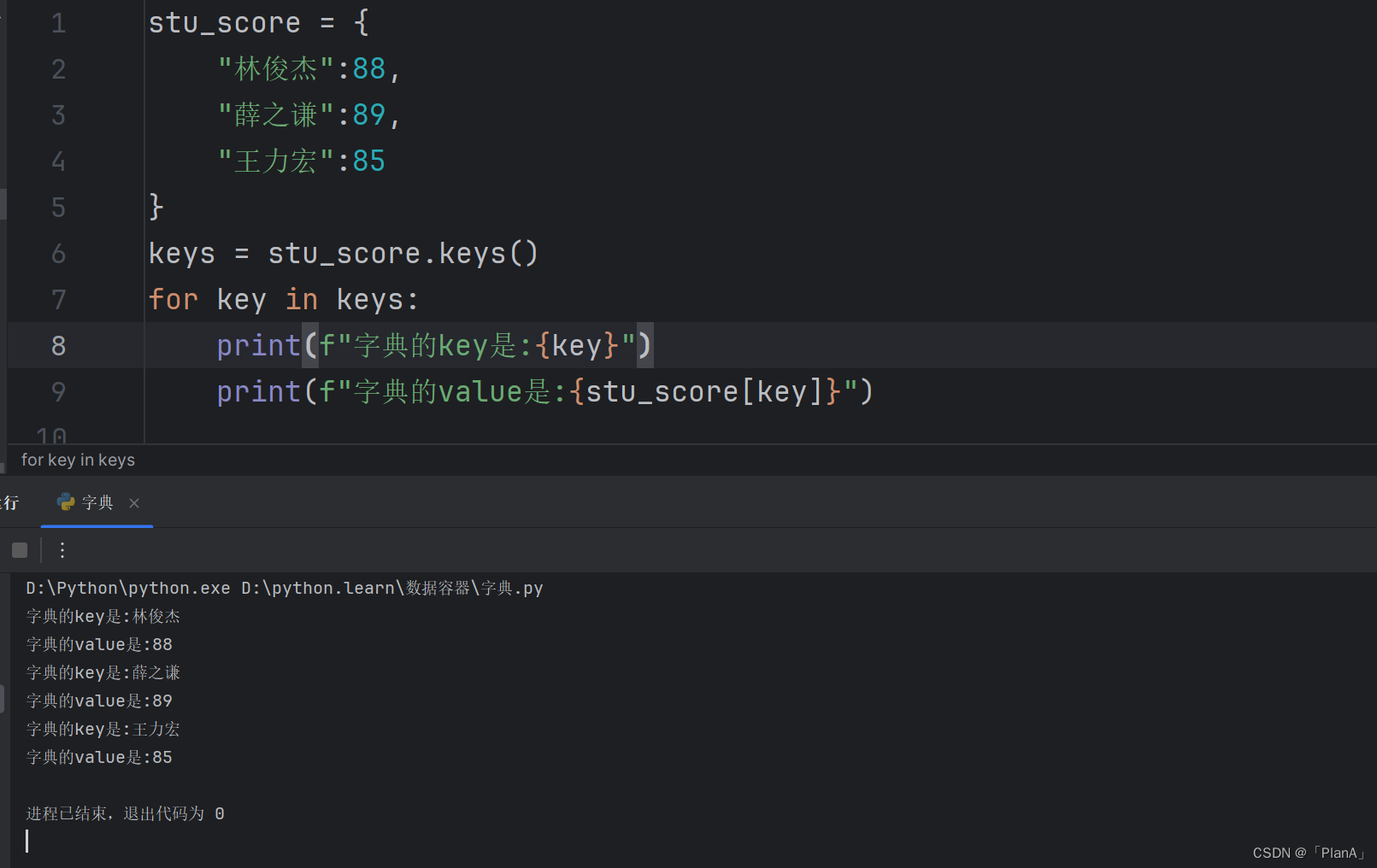
【获取全部的key】
语法:字典.keys()
功能:获得字典中所有的key
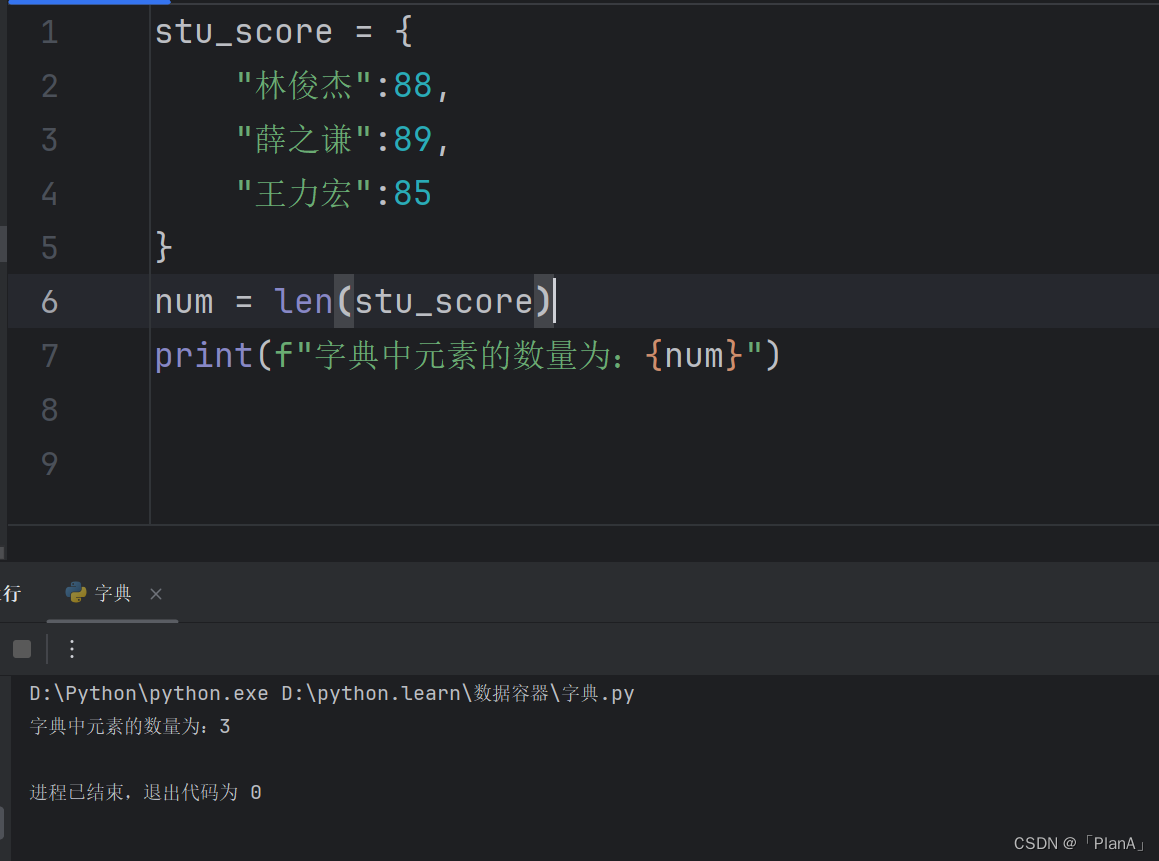
【统计字典内元素的数量】
语法:len(字典)
功能:统计字典中元素的数量
方法演示:
总结:
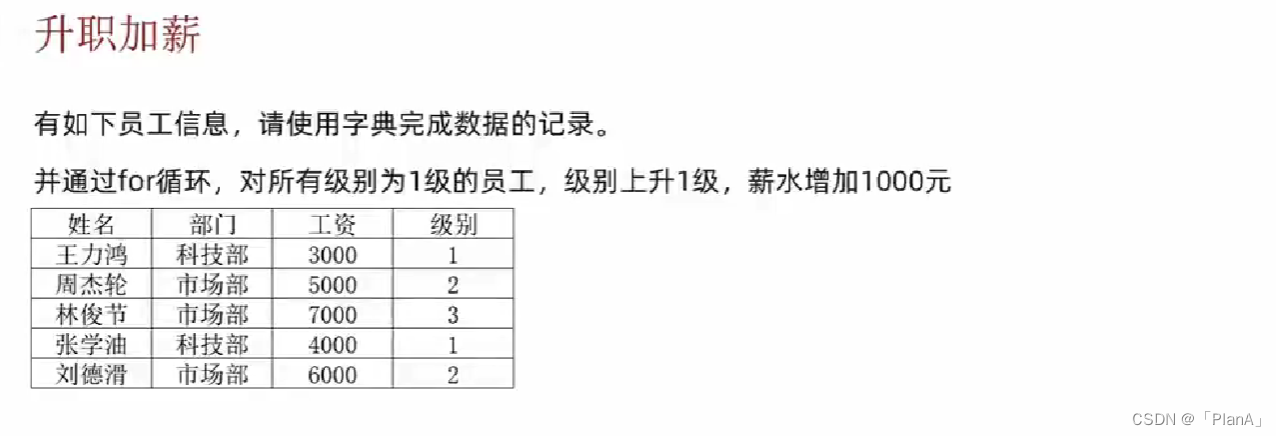
Depart_dict = {
"王力宏":{"部门":"科技部","工资":3000,"级别":1},
"周杰伦":{"部门":"市场部","工资":5000,"级别":2},
"林俊杰":{"部门":"市场部","工资":7000,"级别":3},
"张学友":{"部门":"科技部","工资":4000,"级别":1},
"刘德华":{"部门":"市场部","工资":6000,"级别":1}
}
print(f"全体员工当前信息你如下:")
print(Depart_dict)
for name in Depart_dict:
if Depart_dict[name]["级别"] == 1:
Depart_dict[name]["级别"] += 1
Depart_dict[name]["工资"] += 1000
print(Depart_dict)
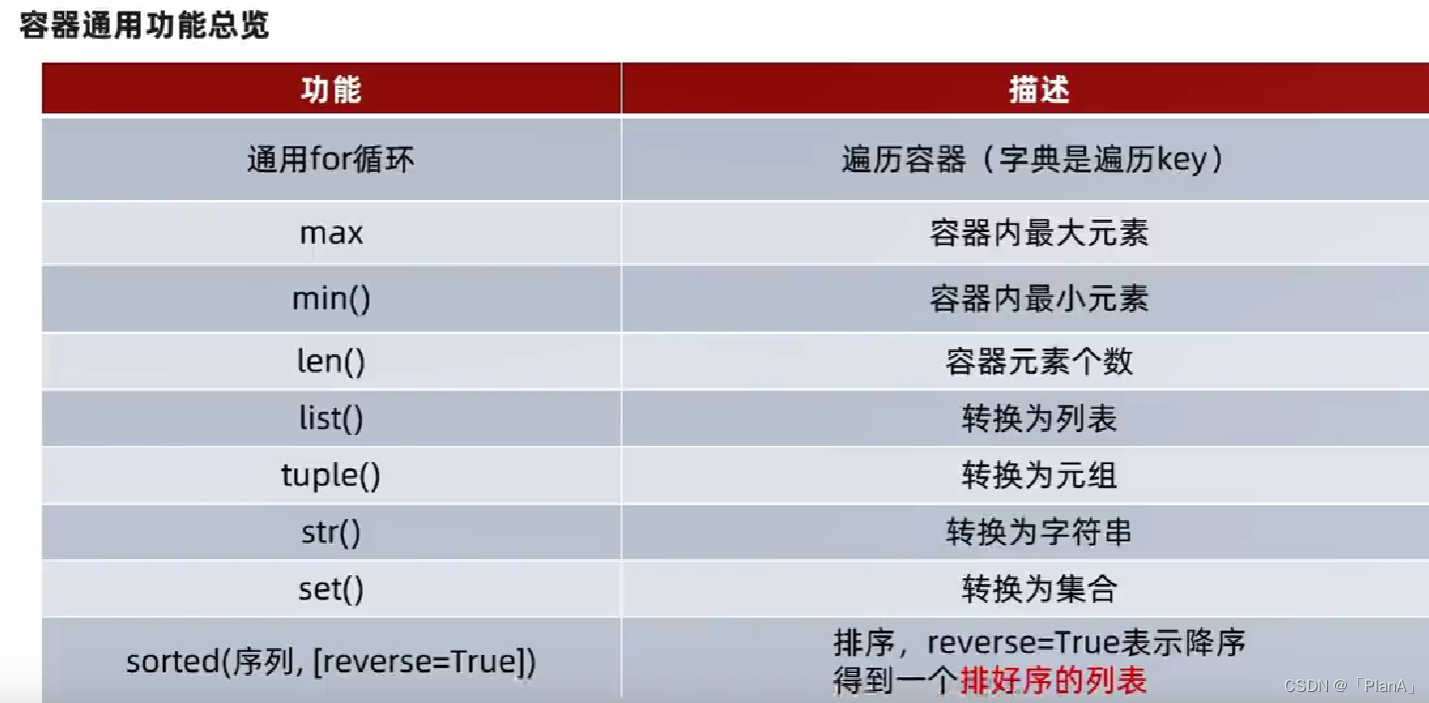
七 数据容器的通用操作
通用操作一

通用操作二

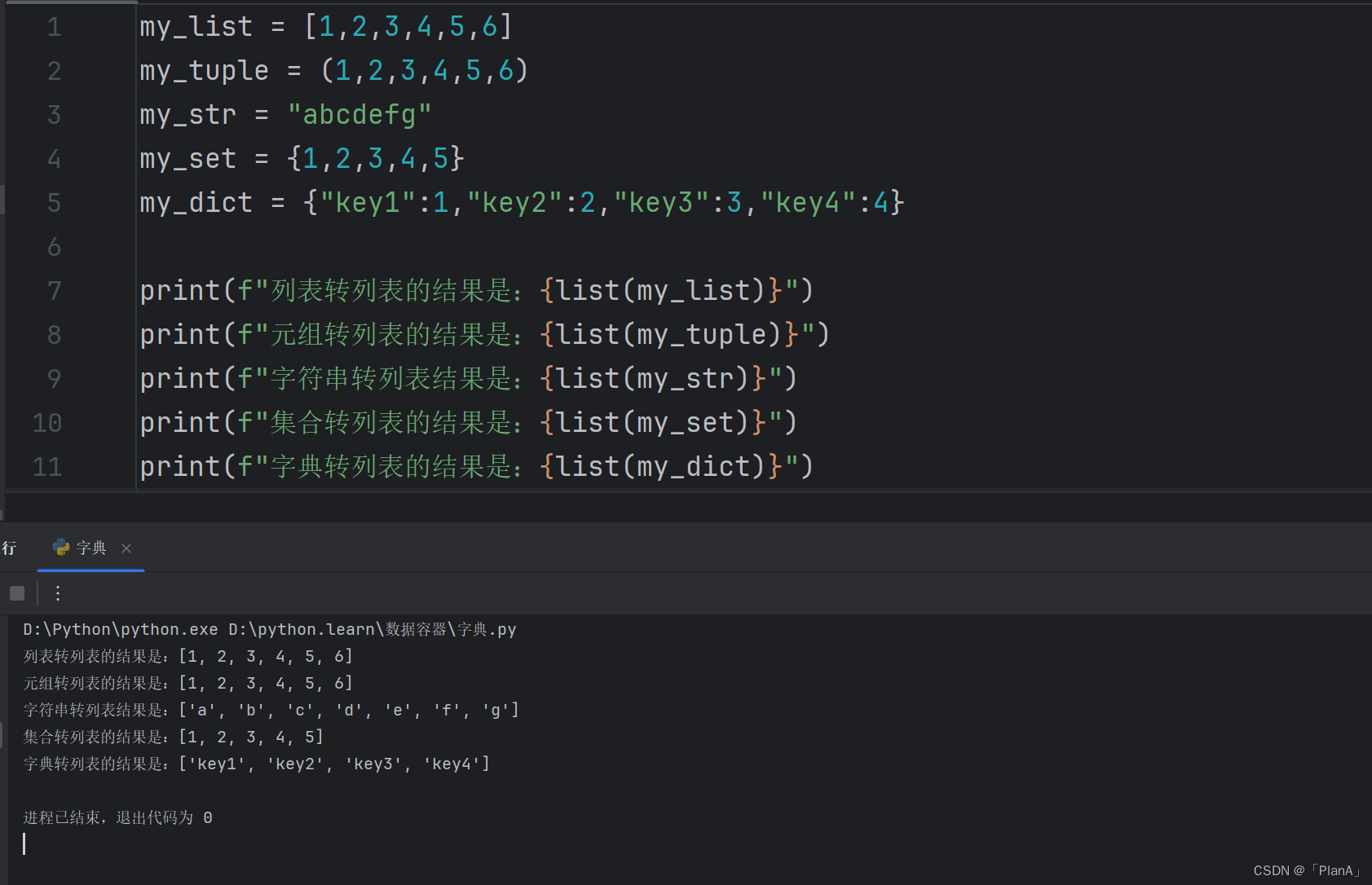
通用操作三

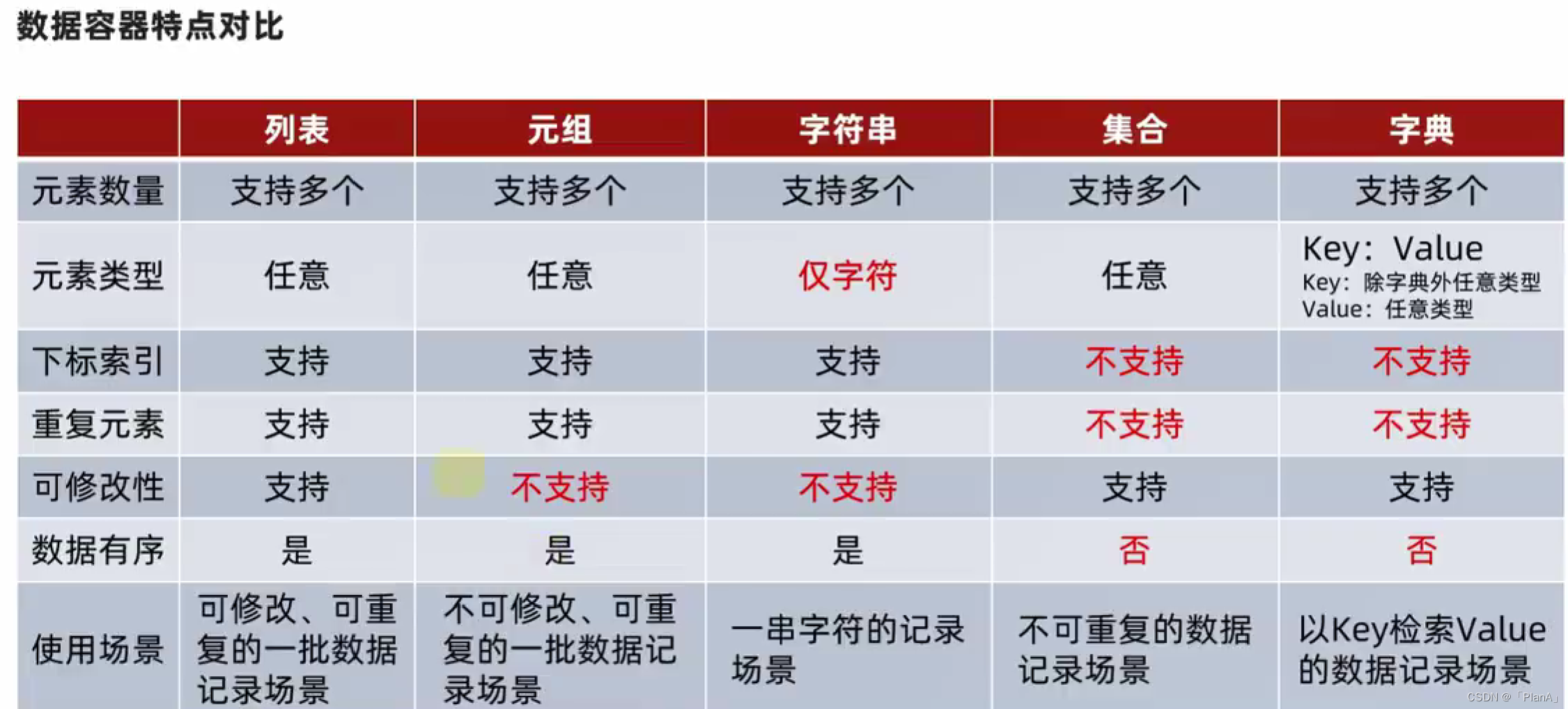
八 数据容器对比总结















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









