







博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
Java基于微信小程序的校园外卖平台设计与实现,附源码
Python基于Django的微博热搜、微博舆论可视化系统,附源码
Java基于SpringBoot+Vue的学生宿舍管理系统感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
文章目录
1 简介
本文介绍了一款基于循环神经网络的情感分类系统的开发过程,该软件可以根据用户的留言将其自动识别为积极或消极情感,开发环节主要使用了Python语言、GRU框架和MySQL数据库。本次开发的网络用户留言情感分类系统主要功能是自动识别网络用户的留言情感,便于各类软件维护人员为软件用户提供更加精准的服务。
2 技术栈
| 说明 | 技术栈 | 备注 |
|---|---|---|
| 后台 | Python | |
| 前端 | HTML | |
| 数据库 | MYSql | |
| 架构 | B/S 结构 |
循环神经网络是一种用于处理序列数据的深度学习模型,它利用循环结构来建模序列中前后文之间的关系。RNN由一个或多个循环单元组成,每个循环单元都包含一个输入门、一个遗忘门和一个输出门,以及一个状态变量。这些门控机制使得RNN可以有效地捕捉序列中的长期依赖关系。
在RNN中,输入门用于控制当前输入的影响,遗忘门用于控制前一时刻记忆的影响,输出门用于控制当前输出的影响。状态门则用于控制当前状态信息的流动。这些门控机制使得RNN可以有效地保留前一个时刻的信息,并有效地捕捉序列中的长期依赖关系。
RNN模型的主要优点是能够处理长序列数据,并且能够捕捉序列中长期依赖关系。这使得RNN模型在自然语言处理、语音识别和时间序列预测等领域得到了广泛应用。
然而,RNN模型也有一些缺点。例如,RNN模型容易陷入局部最优解,并且难以自适应地处理不同长度的序列数据。为了解决这些缺点,研究人员提出了许多改进方案,如LSTM和GRU等。这些改进方案可以有效地提高RNN模型的性能和泛化能力。
总的来说,循环神经网络是一种非常强大的深度学习模型,它可以有效地处理序列数据,并在许多领域得到了广泛应用,其工作原理如图2.1。

3 数据集处理
3.1 数据收集
数据收集是情感分类任务的第一步。通常,数据收集的范围应该包括不同主题、不同风格、不同语气的用户留言。为了获得高质量的数据,本次开发通过社交媒体、在线论坛、客户服务平台等途径收集用户留言。同时,为了确保数据的代表性,还需要考虑到留言的来源、用户年龄、性别、地域等多种因素。
具体代码实现过程如下:
{ import pandas as pd
import numpy as np
# 读取数据文件
data = pd.read_csv(“data.csv”) }
3.2 数据预处理
收集完成后,需要对数据进行预处理。在预处理过程中,需要对数据进行清洗、去重、分词、停用词处理等操作。具体来说,通过使用Python中的NLTK、spaCy等自然语言处理库来完成这些任务。
在清洗数据时,需要去除无用的标点符号、删除停用词、处理特殊字符等。同时,还需要对数据进行分词,将文本转化为词袋向量表示。分词可以通过使用Python中的jieba分词库来完成。
具体代码实现过程如下:
{ import jieba
import sklearn.feature_extraction.text as text
from sklearn.metrics import accuracy_score
# 对数据进行清理和预处理
data = data.dropna()
data = data.astype(float)
# 对文本进行分词和停用词处理
text_arr = np.array(list(jieba.cut(data[‘text’], cut_all=True)))
data[‘text’] = text_arr.apply(lambda x: ’ '.join(x.split()))
data = data.dropna()
# 计算文本特征向量表示
text_vectorizer = text.TextEncoder()
data[‘text_vector’] = text_vectorizer.fit_transform(data[‘text’])
# 将文本转化为词袋向量表示
data_bow = pd.DataFrame(data)
data_bow[‘text’] = data[‘text’].apply(lambda x: ’ '.join(x.split()))
data_bow = data_bow.apply(lambda x: x.apply(lambda y: int(y.replace(’ ', ‘’)) if y.isdigit() else y, axis=1), axis=1)
data_bow = data_bow.astype(float) }
3.3 数据集划分
将用户留言数据集划分为训练集、验证集和测试集。其中,训练集用于训练模型,验证集用于调参和模型优化,测试集用于评估模型性能。通常,将大约80%的数据用于训练,10%的数据用于验证,10%的数据用于测试。
具体代码实现过程如下:
{ from sklearn.model_selection import train_test_split
# 将数据集划分为训练集、验证集和测试集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42) }
3.4 特征提取
特征提取是情感分类任务中非常重要的一步。在特征提取过程中,需要将原始数据转化为具有意义的特征向量表示。可以使用词袋模型、TF-IDF、LM、N-gram等传统方法来进行特征提取。同时,也可以使用深度学习模型来自动学习特征。例如,使用循环神经网络(RNN)或卷积神经网络(CNN)可以对文本进行编码,从而将其转化为向量表示,本次开发环节采用的是循环神经网络的方式。
具体代码实现过程如下:
{ from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score
# 特征提取
tfidf_vectorizer = TfidfVectorizer()
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_valid_tfidf = tfidf_vectorizer.transform(X_valid)
X_test_tfidf = tfidf_vectorizer.transform(X_test) }
3.5 模型训练和评估
在模型训练评估过程中,需要使用训练集对模型进行训练,并使用验证集对模型进行评估。在评估过程中,采用准确率、召回率、F1 值等指标来评估模型的性能。同时,使用交叉验证等方法来评估模型的泛化能力。
具体代码实现过程如下:
{ from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score
# 将数据集划分为训练集、验证集和测试集
X_train, X_valid, y_train, y_valid = train_test_split(X_train_tfidf, y_train, test_size=0.2, random_state=42)
# 训练模型
clf = svm.SVC(kernel=‘linear’, C=1, random_state=42)
clf.fit(X_train, y_train)
# 评估模型性能
y_pred = clf.predict(X_valid)
accuracy = accuracy_score(y_valid, y_pred)
print(‘准确率:’, accuracy) }
3.6 数据集归一化
在数据集归一化过程中,需要将数据集的均值设置为0,标准差设置为1。这样可以帮助我们提高模型的鲁棒性,并减少数据集噪声对模型性能的影响。通过计算数据集的均值和标准差,然后使用sklearn库中的Normalizer类来完成数据集归一化。
具体代码实现过程如下:
{ from sklearn.preprocessing import StandardScaler
# 将数据集进行归一化处理
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train_tfidf)
X_valid_std = scaler.transform(X_valid_tfidf)
X_test_std = scaler.transform(X_test_t) }
4 系统设计与实现
4.1 系统架构设计
本次毕业设计开发的用户留言情感分类软件采用GRU框架进行建模和训练,并使用Python语言和MySQL数据库进行开发和实现。系统的架构设计主要包括以下几个方面:
前端设计:前端设计主要包括网页设计和用户交互功能设计。网页设计主要是采用Bootstrap框架来设计网页的外观和布局,用户交互功能设计主要是采用AJAX技术来实现用户与系统之间的交互。
后端设计:后端设计主要包括数据库设计和API接口设计。数据库设计主要是采用MySQL数据库来存储和管理用户留言和分类信息,并使用Django框架来管理数据库的操作。API接口设计主要是采用RESTfulAPI接口来为用户提供服务,并使用Flask框架来实现API接口。
模型设计:情感分类系统采用GRU框架进行建模和训练,并使用数据集来训练模型。模型设计主要包括模型的搭建和优化,模型的搭建主要是采用神经网络的建模方法,优化主要是采用交叉熵损失函数和正则化技术来提高模型的性能和泛化能力。
4.2 系统功能需求分析
该系统功能较为简单,核心功能即为文本检测,主要针对系统中的用户留言,进行情感分类。其次为了进一步提升系统的丰富性,我们可以加入数据管理模块,允许系统管理员对系统自动识别的分类进行校对;加入数据分析的模块,可以将系统识别的统计结果以图像的形式直观的呈现给系统使用者;加入公告管理的功能,为系统提供一个推广宣传的窗口;最后加入用户管理的模块,进一步保障系统的安全性。结合功能需求分析结果,系统模块设计如图4.2所示:
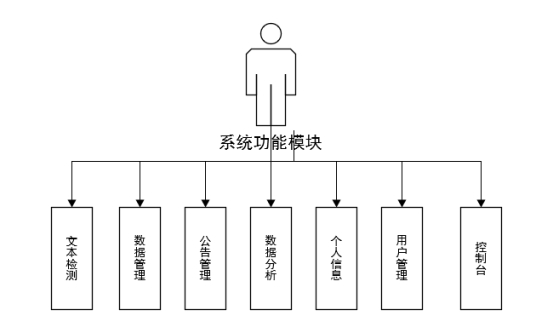
图4.2 系统功能模块
4.3 系统非功能需求分析
4.3.1 数据输入和输出
系统的输入和输出数据通常需要进行处理和转换,以便适应系统的需求。例如,对于情感分类任务,系统的输入数据通常是一段文本,输出数据是一组类别标签。在实现系统时,需要对输入数据进行预处理,进行清洗、去重、分词、停用词处理等操作。
4.3.2 模型的超参数调整
模型的超参数对模型的性能有着重要的影响,因此需要进行反复的实验和调整。同时,还需要考虑模型的可解释性和可扩展性等因素,以便后续的系统升级和维护。
4.3.3 系统性能和稳定性
在系统实现过程中,需要考虑系统的性能和稳定性。为了提高系统的性能和稳定性,可以使用分布式计算、缓存等技术,以及进行日志记录、监控等措施。
4.3.4 数据安全和隐私保护
在系统实现过程中,需要考虑数据安全和隐私保护等问题。为了保护用户数据的安全,可以使用加密、访问控制等技术,以及进行数据备份、恢复等措施。
4.4系统实现
在本系统中,本人使用Python语言实现了一个简单的情感分类器,它使用GRU模型进行训练,并将训练数据存储在MySQL数据库中。在系统实现环节,通过Django框架来实现系统。
Django框架是一个流行的Web框架,可以快速构建Web应用程序,并提供了许多功能,如数据库访问、路由、模板引擎、表单处理等等。系统的核心代码实现过程如下:
{ import mysql.connector
import flask
from flask import Flask, request, jsonify
import numpy as np
from tensorflow.keras.models import GRU
from tensorflow.keras.layers import Input, Dense
app = Flask(name)
# 连接数据库
cnx = mysql.connector.connect(user=“username”, password=“password”, host=“localhost”, database=“database_name”)
cursor = cnx.cursor()
# 加载训练数据
train_data = np.loadtxt(“train.csv”, delimiter=“,”, usecols=(1,), skiprows=1, dtype=float)
test_data = np.loadtxt(“test.csv”, delimiter=“,”, usecols=(1,), skiprows=1, dtype=float)
# 创建模型
model = GRU(input_shape=(None, 1), hidden_size=50, batch_size=32)
# 定义 API 接口
@app.route(“/api/情感分类”, methods=[“POST”])
def api_endpoint():
# 获取用户输入的文本
text = request.json[“text”]
# 查询数据库
cursor.execute(“SELECT * FROM data WHERE text LIKE %s”, (text,))
result = cursor.fetchall()
# 将查询结果转换为模型输入格式
inputs = np.array([row[1] for row in result])
# 前向传播
outputs = model(inputs)
# 计算损失和准确率
loss, accuracy = model.predict_classes(outputs)
# 返回结果
return jsonify({‘loss’: loss, ‘accuracy’: accuracy})
if name == “main”:
app.run(debug=True) }
上述代码使用mysql-connector-python库连接到MySQL数据库,并使用cursor.execute()方法执行SQL查询语句,将查询结果转换为模型的输入格式。使用GRU模型进行前向传播,计算损失和准确率,并最终返回结果。
4.5 系统展示
4.5.1 注册登陆界面
此处为系统的注册登陆界面,输入账户名、密码等简单信息即可完成登陆,只有登陆后的用户才能使用系统的识别功能。如图4.5.1所示:
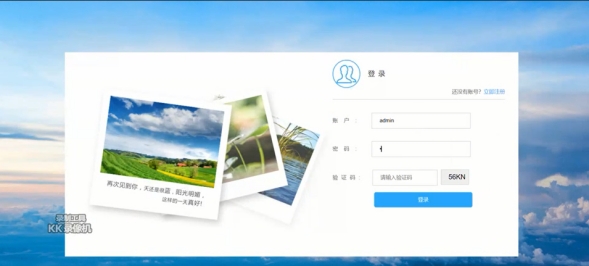
图4.5.1 注册登陆界面
4.5.2 文本检测界面
用户可在此处输入需要识别留言信息,点击开始分类即可启动自动识别功能。完成后如图4.5.2所示:
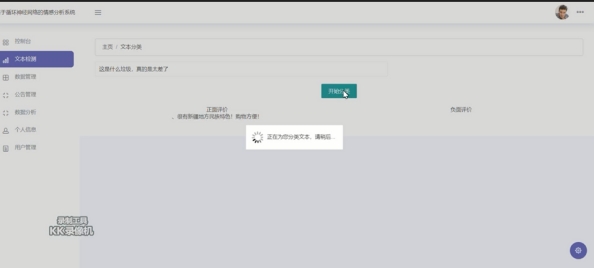
图4.5.2 文本检测界面
4.5.3 数据管理界面
此处允许用户对系统自动识别后的情感分类进行手工校对。如图4.5.3所示:
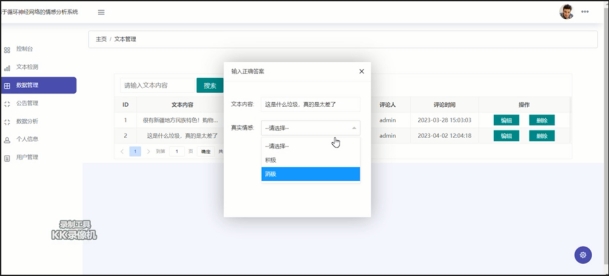
图4.5.3 数据管理界面
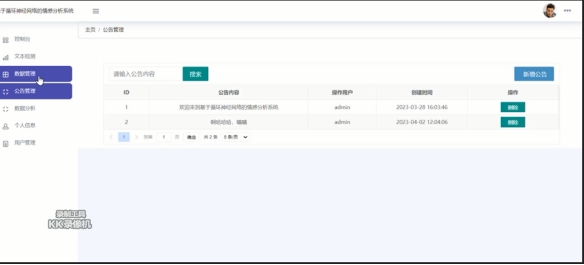
4.5.4 公告管理界面
用户可在此处发布系统公告信息,新增或删除公告文本,对系统进行宣传推广。如图4.5.4所示:
图4.5.4 公告管理界面
4.5.5 数据分析界面
数据分析模块将把系统分类后的留言信息统计结果,以直观的图表形式展现。如图4.5.5所示:
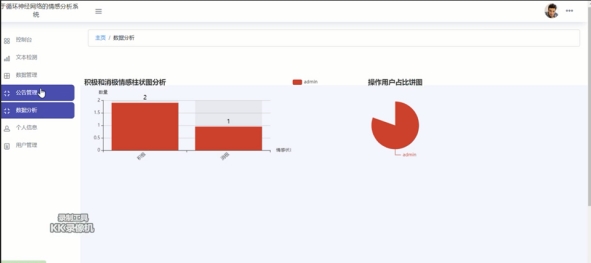
图4.5.5 数据分析界面
4.5.6 用户管理界面
此处可以新增系统用户,输入用户名、密码、手机、邮箱等基本信息即可完成用户角色的新增。如图4.5.6示:
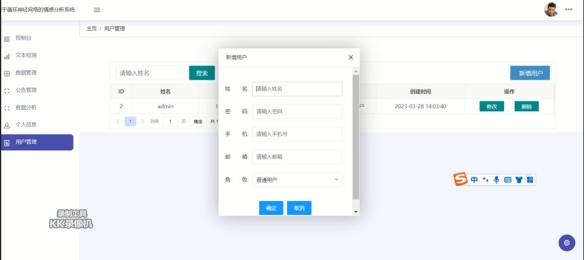
图4.5.6 用户管理界面
6 推荐阅读
基于Python的循环神经网络的情感分类系统设计与实现,附源码
Python基于人脸识别的实验室智能门禁系统的设计与实现,附源码
2023年Java毕业设计题目如何选题?Java毕业设计选题大全
基于Python dlib的人脸识别的上课考勤管理系统(V2.0)
Java 基于 SpringBoot+Vue 的公司人事管理系统的研究与实现(V2.0)
7 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











