






 本文详细指导了如何从零开始安装和配置Hadoop,包括虚拟机设置、Linux安装、JDK配置、Hadoop环境变量的配置以及HDFS和YARN服务的初始化和启动过程。
本文详细指导了如何从零开始安装和配置Hadoop,包括虚拟机设置、Linux安装、JDK配置、Hadoop环境变量的配置以及HDFS和YARN服务的初始化和启动过程。
希望本教程能帮助你顺利搭建起自己的 Hadoop 环境,迈出大数据处理的第一步。如果你在安装过程中遇到问题,欢迎参考 Hadoop 官方文档或查阅相关社区的讨论,相信你会逐步掌握更多技巧,迎接大数据时代的挑战。
Hadoop搭建前提:搭建三台机器
1.配置三台机器的主机名和IP地址映射
vim /etc/hosts (输入三台主机IP和对应主机名)vim /etc/hostname (输入主机名)
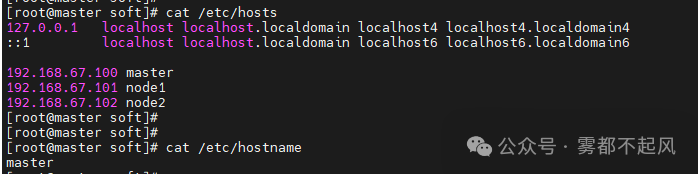
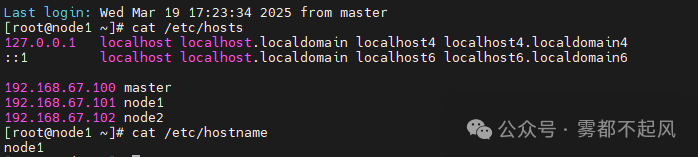
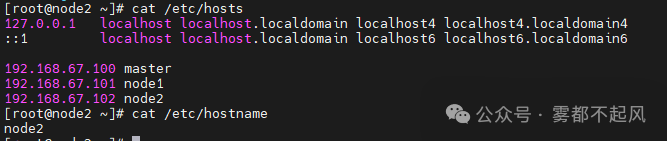
三台机器全部修改完毕以后 保存退出 输入reboot命令重启使其生效
2.关闭防火墙并禁止开机自启动(所有节点)
systemctl stop firewalldsystemctl disable firewalld

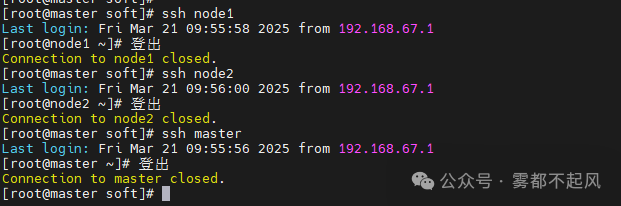
3.配置免密登录
ssh-keygen -t rsa (master节点运行 一直回车生成密钥)ssh-copy-id master (将密钥文件同步至所有节点 需要输入密码)ssh-copy-id node1ssh-copy-id node2
4.上传JDK软件包并解压(master节点)
tar -zxvf jdk1.8.0_171.tar.gz 
5.配置JDK的环境变量
vim /etc/profilesource !$

6.上传Hadoop软件包并解压(master节点)
tar -zxvf hadoop-2.7.6.tar.gz
7.配置Hadoop环境变量
vim /etc/profilesource !$

8.修改Hadoop配置文件
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop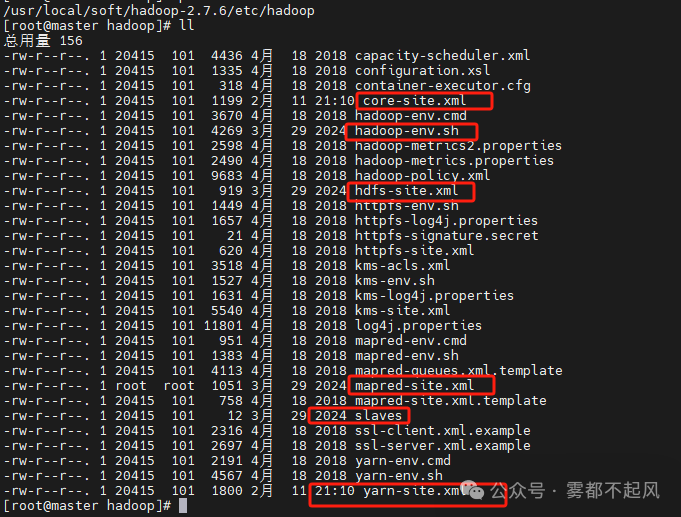
(1)修改slaves文件 添加node1 node2
vim slaves
(2)修改hadoop-env.sh文件 添加JDK路径

(3)修改core-site.xml文件 在configuration中间增加以下内容
vim core-site.xml<property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/soft/hadoop-2.7.6/tmp</value></property><property><name>fs.trash.interval</name><value>1440</value></property>
(4)修改hdfs-site.xml文件 在configuration中间增加以下内容
vim hdfs-site.xml<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property>
(5)修改yarn-site.xml文件 在configuration中间增加以下内容
vim yarn-sit.xml<property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>20480</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property>
(6)修改mapred-site.xml文件 在configuration中间增加以下内容
cp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
9.将Hadoop软件包和JDK以及环境变量同步至子节点
scp -r /usr/local/soft/jdk1.8.0_171/ node1:/usr/local/soft/scp -r /usr/local/soft/jdk1.8.0_171/ node2:/usr/local/soft/scp -r /usr/local/soft/hadoop-2.7.6/ node1:/usr/local/soft/scp -r /usr/local/soft/hadoop-2.7.6/ node2:/usr/local/soft/scp -r /etc/profile node1:/etc/scp -r /etc/profile node2:/etc/
10.格式化namenode
hdfs namenode -format11.启动Hadoop
start-all.sh (全部启动)start-dfs.shstart-yarn.sh
12.访问hdfs界面验证是否安装成功
http://master.5007013.停止hadoop
stop-all.sh通过本教程,我们已经成功地搭建了一个基本的 Hadoop 集群,并配置了相关的环境和服务。Hadoop 为大规模数据存储和处理提供了强大的支持,其分布式计算框架能够帮助企业处理海量数据,提升数据处理效率。虽然本教程覆盖了基础的安装和配置步骤,但实际应用中可能还会涉及更复杂的调优、故障排除及安全性配置等内容,建议根据具体需求进一步学习和探索。
祝你在大数据的旅程中取得成功!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









