







第一部分:准备工作
1 安装虚拟机
2 安装centos7
3 安装JDK
以上三步是准备工作,至此已经完成一台已安装JDK的主机

第二部分:准备3台虚拟机
以下所有工作最好都在root权限下操作
1 克隆
上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;
1.1 进行克隆2
 1.2 下一步
1.2 下一步
 1.3 下一步
1.3 下一步
 1.4 下一步
1.4 下一步

1.5 根据子机需要,命名和安装路径
 1.6 完成克隆
1.6 完成克隆

1.7 重复上述1-6步骤克隆出另外一台slave1.如图

2 参数确定(IP地址,主机名称)(三台虚拟机都要操作)
2.1 分别在三台虚拟机查看三台虚拟机的ip地址,ifconfig即可
 2.2 分别在三台虚拟机查看机器名称,并修改,主机改成master
2.2 分别在三台虚拟机查看机器名称,并修改,主机改成master
 2.3 重复上面步骤检查3台虚拟机IP地址和名称,可以更改自己所想改的.三台机器具体参数如下:
2.3 重复上面步骤检查3台虚拟机IP地址和名称,可以更改自己所想改的.三台机器具体参数如下:
192.168.119.135 master
192.168.119.132 slave1
192.168.119.134 slave2
3 修改/etc/hosts(三台虚拟机都要操作)
3.1 修改 vim /etc/hosts文件
 3.2 点击i进入编辑模式,加入三台机器的参数,:wq 保存退出(复制别人得图像,ip和名字参考自己得)
3.2 点击i进入编辑模式,加入三台机器的参数,:wq 保存退出(复制别人得图像,ip和名字参考自己得)
 3.3 检查三台虚拟机是否ping通,以master为例,都能ping通.
3.3 检查三台虚拟机是否ping通,以master为例,都能ping通.


第三部分:给3台虚拟机配置密钥
1 配置密钥文件(三台虚拟机都要操作)
1.1 生成密钥文件,红色箭头处需要再敲一次空格键
 1.2 查看生成的文件,id_rsa , id_rsa.pub
1.2 查看生成的文件,id_rsa , id_rsa.pub
 在另外两台子机上重复1.1和1.2
在另外两台子机上重复1.1和1.2
2 创建authorized_keys 文件(三台虚拟机都要操作,这里采用xftp6完成)
2.1 创建文件
 2.2 查看是否创建
2.2 查看是否创建
 2.3 将三台虚拟机的id_rsa.pub内容全部保存至mater的authorized_keys文件内
2.3 将三台虚拟机的id_rsa.pub内容全部保存至mater的authorized_keys文件内
三台心机的id_rsa.pub分别是


 将上面的三个内容全部保存至authorized_keys
将上面的三个内容全部保存至authorized_keys

3 将authorized_keys复制到另外两个子机中,(此处的复制通过xftp6完成),如图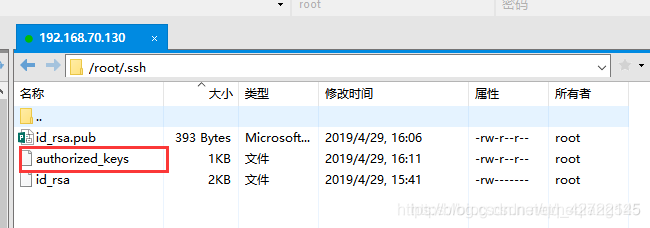
3.1 下载本地桌面,直接拖拽即可
 3.2 登陆另外两台子机,还没有authorized_keys
3.2 登陆另外两台子机,还没有authorized_keys
 3.3 将2.4.1拖到桌面上的authorized_keys拖到另外两台子机的对于文件目录下,即可完成复制工作
3.3 将2.4.1拖到桌面上的authorized_keys拖到另外两台子机的对于文件目录下,即可完成复制工作


4 测试ssh无密码登陆
4.1 测试slave1,将图片得slave改成slave1

4.2 exit 退出(必须退出,否正其余的操作实在别的虚拟机上)
 4.3 测试slave2
4.3 测试slave2
 4.4 exit 退出(必须退出,否则其余的操作都是在别的虚拟机上进行的)
4.4 exit 退出(必须退出,否则其余的操作都是在别的虚拟机上进行的)

第四部分:安装Hadoop
此处已经不需要安装JDK了,因为克隆时候主机已经安装JDK,所以三台虚拟机已经有JDK了
1 安装hadoop
1.1 新建hadoo文件夹(三台虚拟机都需要新建hadoop文件夹)
 1.2 把下载好的Hadoop依次拖进三台虚拟机的/usr/hadoop文件夹里
1.2 把下载好的Hadoop依次拖进三台虚拟机的/usr/hadoop文件夹里
 1.3 分别在三台虚拟机对应的hadoop文件夹下压缩Hadoop文件(三台虚拟机都需要操作)
1.3 分别在三台虚拟机对应的hadoop文件夹下压缩Hadoop文件(三台虚拟机都需要操作)
cd /usr/hadoop 切换到制定目录
tar -zxvf hadoop-2.7.3 解压文件
查看如下图:
 在另外两台子机上进行如上操作
在另外两台子机上进行如上操作
2 新建几个文件夹(只在master上操作即可)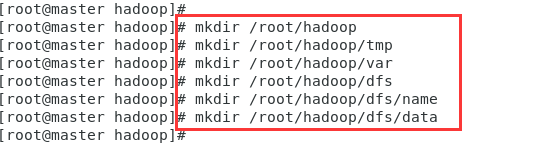
3 修改Hadoop配置文件(只在master上操作即可,除了3.2三台虚拟机都要操作)
修改etc/hadoop目录下部分文件
 3.1 修改core-site.xml,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,)
3.1 修改core-site.xml,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,)
路径: /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml

<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
3.2 修改hadoop-env.sh(三台都需要操作)
路径: /usr/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}改成下面的红框jdk路径(这个jdk路径就是之前安装jdk的路径),老师安装得jdk路径为/export/servers/jdk
 3.3 修改hdfs-site.xml,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,)
3.3 修改hdfs-site.xml,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,)
路径: /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
<description>need not permissions</description>
</property>
3.4 新建并且修改mapred-site.xml,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,),原来没有mapred-site.xml,这个是自己新建得
路径: /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template

<property>
<name>mapred.job.tracker</name>
<value>master:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.5 修改slaves(通过vim > i > 输入内容 > esc > :wq ,)
路径: /usr/hadoop/hadoop-2.7.3/etc/hadoop/slaves文件,将里面的localhost删除,添加如下内容:将图片里得slave,slave1,换成自己得slave1,slave2
 3.6 修改yarn-site.xml文件,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,)
3.6 修改yarn-site.xml文件,在节点内加入配置(通过vim > i > 输入内容 > esc > :wq ,)
路径: /usr/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
第五部分:启动Hadoop
1 初始化
进入到master这台机器的/usr/hadoop/hadoop-2.7.3/bin目录
cd /usr/hadoop/hadoop-2.7.3/bin 切换到指定目录
./hadoop namenode -format 执行命令

 格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件
 2 启动hadoop
2 启动hadoop
进入到master这台机器的/usr/hadoop/hadoop-2.7.3/sbin目录,
cd /usr/hadoop/hadoop-2.7.3/sbin 切换到指定目录
./start-all.sh 执行命令

测试Hadoop
1 执行命令,关闭防火墙,CentOS7下,命令是:
 2 在本地浏览器里访问如下地址: http://localhost:50070/ 自动跳转到了overview页面,这里得localhost就是master IP
2 在本地浏览器里访问如下地址: http://localhost:50070/ 自动跳转到了overview页面,这里得localhost就是master IP
 3 在本地浏览器里访问如下地址: http://localhost:8088/自动跳转到了cluster页面
3 在本地浏览器里访问如下地址: http://localhost:8088/自动跳转到了cluster页面
















 2517
2517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









