






hive行列互换
今天你用钱袋里的铜板充满你的内心,明天你的内心就可以把你的钱袋注满黄金。
目录
1.创建表
CREATE EXTERNAL TABLE IF NOT EXISTS learn3.student20(
id STRING COMMENT "学生ID",
name STRING COMMENT "学生姓名",
age int COMMENT "年龄",
gender STRING COMMENT "性别",
subject STRING COMMENT "学科"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
STORED AS TEXTFILE;2.上传数据
load data local inpath "/usr/local/soft/hive-3.1.2/data/student_20.txt" INTO TABLE learn3.student20;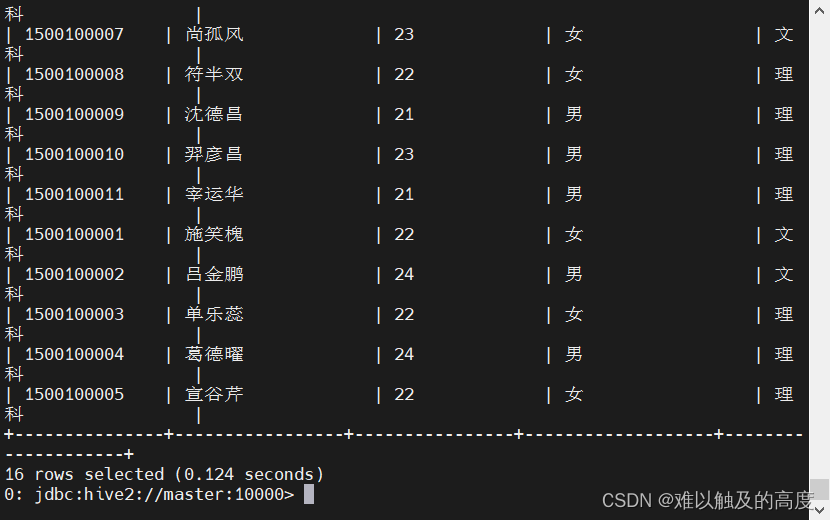
3.实现需求
理科|男 1500100020|杭振凯,1500100019|娄曦之
---需求:将两列数据进行拼接 按照上面的格式存储输出
select
CONCAT(subject,"|",gender) as subject_gender
,CONCAT(name,"|",id) as name_id
from learn3.student20;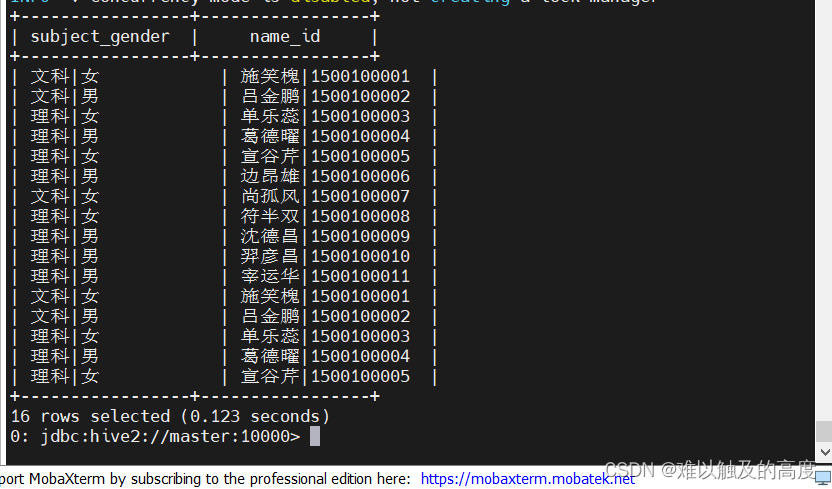
然后我们需要进行合并
select r.subject_gender,collect_list(r.name_id)
from
(
select
CONCAT(subject,"|",gender) as subject_gender
,CONCAT(name,"|",id) as name_id
from learn3.student20
) r group by subject_gender;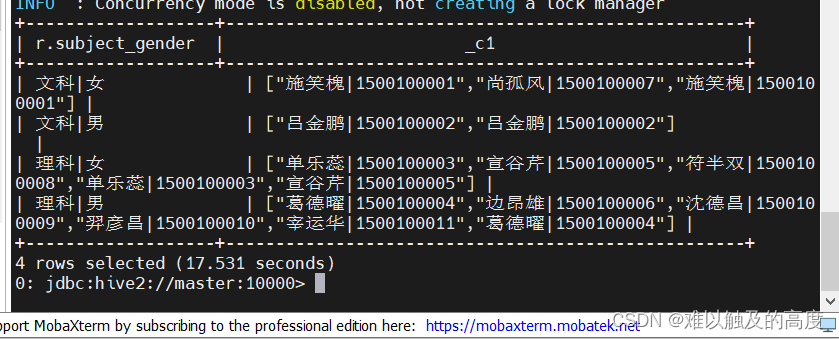
但是 我们如果想要达到需要的结果 我们还需要做一些其他操作 去掉两边的[ ] 我们对SQL语句做一下改进
select r.subject_gender,CONCAT_WS(",",collect_list(r.name_id))
from
(
select
CONCAT(subject,"|",gender) as subject_gender
,CONCAT(name,"|",id) as name_id
from learn3.student20
) r group by subject_gender;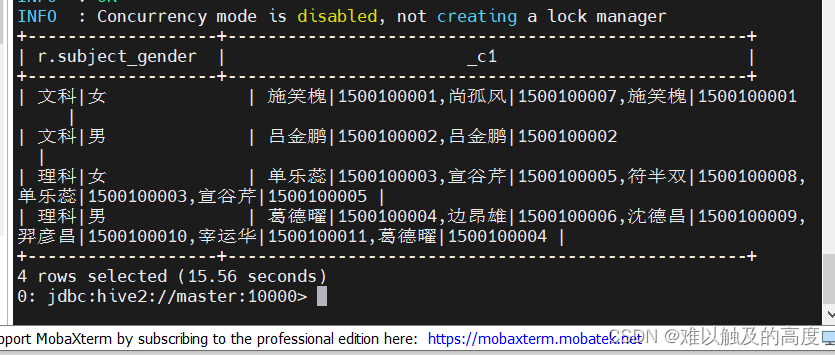
对以上代码 我们也可以使用WITH AS写法
WITH concat_stu AS(
select
CONCAT(subject,"|",gender) as subject_gender
,CONCAT(name,"|",id) as name_id
from learn3.student20)
select concat_stu .subject_gender,CONCAT_WS(",",collect_list(concat_stu .name_id))
from concat_stu group by subject_gender;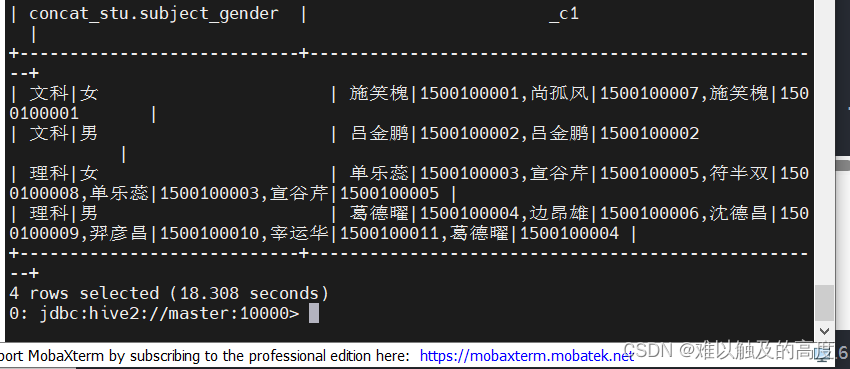
| 文科|女 | ["1500100001|施笑槐","1500100007|尚孤风","1500100016|潘访烟","1500100018|骆怜雪"] |
| 文科|男 | ["1500100002|吕金鹏","1500100013|逯君昊"] |
| 理科|女 | ["1500100003|单乐蕊","1500100005|宣谷芹","1500100008|符半双","1500100012|梁易槐","1500100015|宦怀绿","1500100017|高芷天"] |
| 理科|男 | ["1500100004|葛德曜","1500100006|边昂雄","1500100009|沈德昌","1500100010|羿彦昌","1500100011|宰运华","1500100014|羿旭炎","1500100019|娄曦之","1500100020|杭振凯"] |
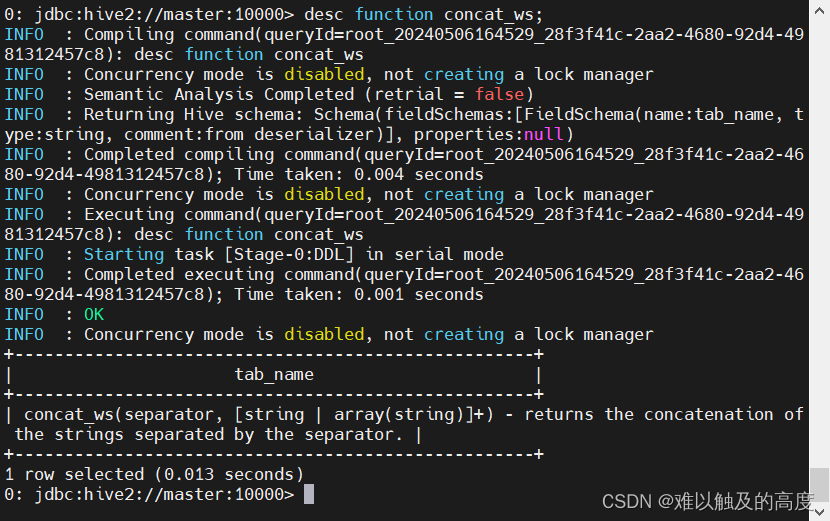
desc function concat_ws;
| concat_ws(separator, [string | array(string)]+) - returns the concatenation of the strings separated by the separator. |
我们通过查看 可以看到 concat_ws()中的既可以是array类型的参数 也可以传入一个string类型的参数 所以我们可以使用concat_ws()函数用 , 号将它们拼接在一起
4.行列互换
+-----------------+-----------------+
| subject_gender | id_name |
+-----------------+-----------------+
| 文科|女 | 1500100001|施笑槐 |
| 文科|男 | 1500100002|吕金鹏 |
| 理科|女 | 1500100003|单乐蕊 |
| 理科|男 | 1500100004|葛德曜 |
| 理科|女 | 1500100005|宣谷芹 |
| 理科|男 | 1500100006|边昂雄 |
| 文科|女 | 1500100007|尚孤风 |
| 理科|女 | 1500100008|符半双 |
| 理科|男 | 1500100009|沈德昌 |
| 理科|男 | 1500100010|羿彦昌 |
| 理科|男 | 1500100011|宰运华 |
| 理科|女 | 1500100012|梁易槐 |
| 文科|男 | 1500100013|逯君昊 |
| 理科|男 | 1500100014|羿旭炎 |
| 理科|女 | 1500100015|宦怀绿 |
| 文科|女 | 1500100016|潘访烟 |
| 理科|女 | 1500100017|高芷天 |
| 文科|女 | 1500100018|骆怜雪 |
| 理科|男 | 1500100019|娄曦之 |
| 理科|男 | 1500100020|杭振凯 |
| 文科|女 | 1500100001|施笑槐,1500100007|尚孤风,1500100016|潘访烟,1500100018|骆怜雪 |
| 文科|男 | 1500100002|吕金鹏,1500100013|逯君昊 |
| 理科|女 | 1500100003|单乐蕊,1500100005|宣谷芹,1500100008|符半双,1500100012|梁易槐,1500100015|宦怀绿,1500100017|高芷天 |
| 理科|男 | 1500100004|葛德曜,1500100006|边昂雄,1500100009|沈德昌,1500100010|羿彦昌,1500100011|宰运华,1500100014|羿旭炎,1500100019|娄曦之,1500100020|杭振凯 |
1)行转列:
将原先多行数据转成一行
转换方式:
通过COLLECT_SET() 或者 COLLECT_LIST() 和 GROUP BY 进行配合使用
将GROUP BY 分组的数据进行存放于一个集合当中
2)列传行:
将一行数据转换为多行数据
①如何转换:(案例)
案例:
| wordcount.word |
+-----------------+
| hello,word |
| hello,java |
| hello,hive |
| hello,word |
| hello,java |
| hive,hello |
结果:
+----------+
| _u1.col |
+----------+
| hello |
| hive |
| java |
| word |
| hello |
| hive |
+----------+如果是这种格式一致的表 我们在进行列转行的操作时 可以使用拼接的方式
WITH split_res AS
(
select split(word,",")[0] as clo1,
split(word,",")[1] as clo2
from learn3.wordcount
)
,c1 AS
(
select clo1 as clo,count(*) as num
from split_res group by clo1
)
,c2 AS
(
select clo2 as clo,count(*) as num
from split_res group by clo2
)
select clo from c1
UNION ALL
select clo from c2;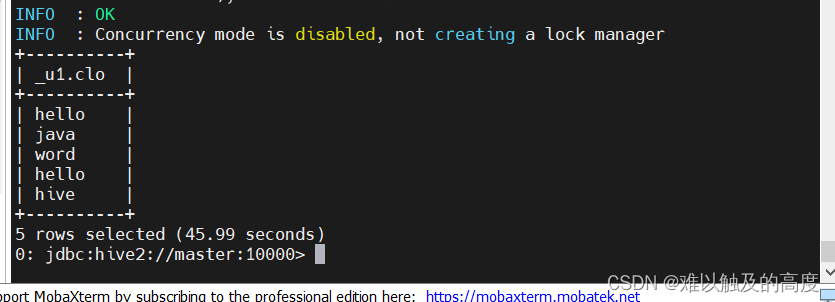
现在我们的数据参差不齐 刚才的方法就没办法使用了 那么 有没有什么更方便的方法呢?
我们再插入一行数据
INSERT INTO TABLE learn3.wordcount (word) VALUES ("hello,word,hello,java,hello,spark");②EXPLODE() 函数:将集合中的一行数据转换为多行
select
EXPLODE(split(word,",")) as word
FROM learn3.wordcount;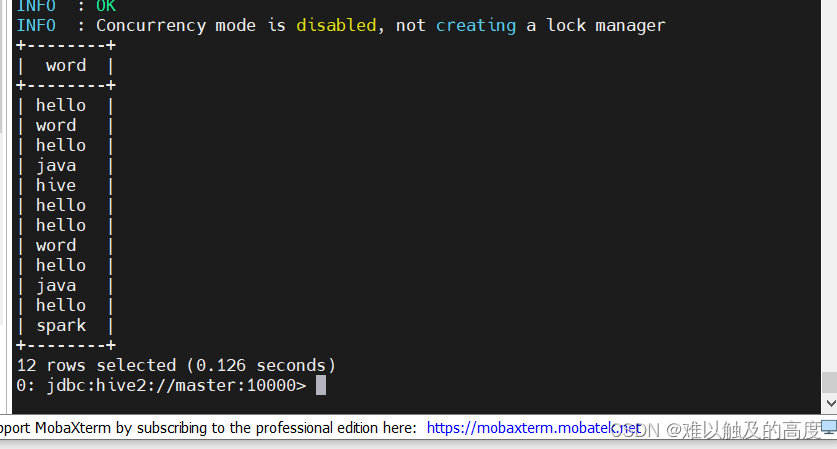
现在我们再对这个表做wordcount也就非常方便了 直接使用count和group by就可以了
select count(a.word) as num,a.word
from
(
select
EXPLODE(split(word,",")) as word
FROM learn3.wordcount
) a group by a.word;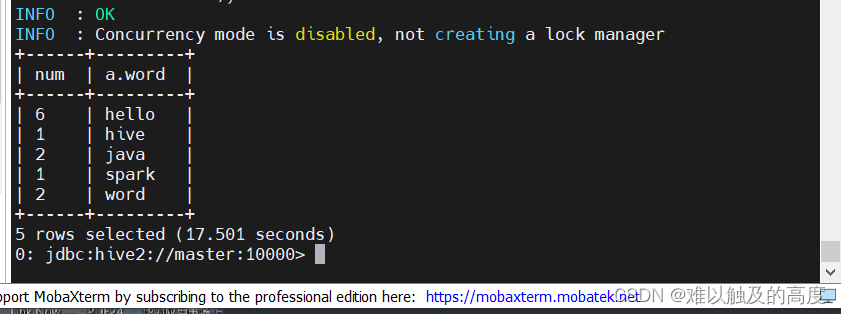
③示例2:增加一列数据
CREATE TABLE learn3.movie(
movie_name STRING COMMENT "电影名",
types STRING COMMENT "电影类型"
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath "/usr/local/soft/hive-3.1.2/data/moive.txt" INTO TABLE learn3.movie;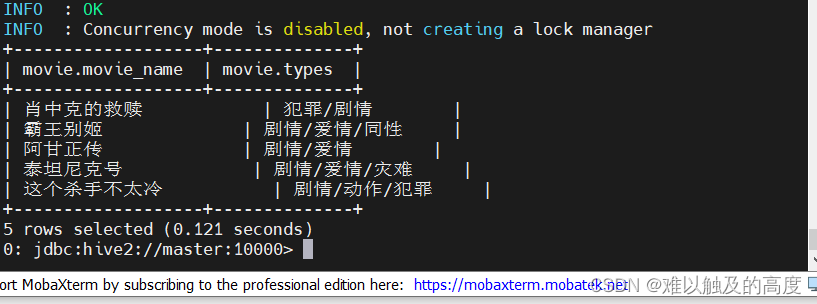
需求:
---- 将types列中的电影类型进行分隔,并且与电影名进行对应
由 |肖申克的救赎 | 犯罪/剧情 |
转换为:
肖申克的救赎 犯罪
肖申克的救赎 剧情
如果我们直接使用查询语句 我们会发现报下面的错误 因为我们现在多了一列数据 他怎么实现对应 这是一个问题
select movie_name
,EXPLODE(split(types,"/")) as type
FROM learn3.movie;
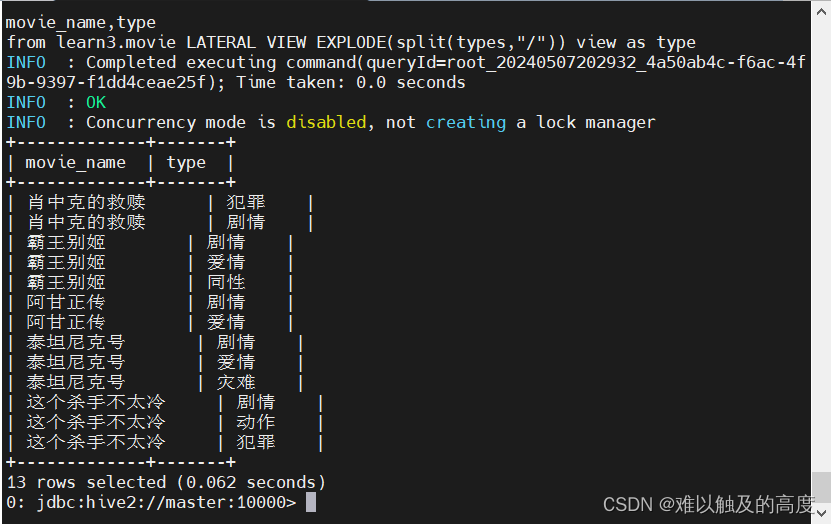
lateral view 用法:行转列

我们根据示例修改一下我们的SQL语句
select
movie_name,type
from learn3.movie LATERAL VIEW EXPLODE(split(types,"/")) view as type;
| movie.movie_name | movie.types |
+-------------------+--------------+
| 肖申克的救赎 | 犯罪/剧情 |
| 霸王别姬 | 剧情/爱情/同性 |
| 阿甘正传 | 剧情/爱情 |
| 泰坦尼克号 | 剧情/爱情/灾难 |
| 这个杀手不太冷 | 剧情/动作/犯罪 |
| movie_name | type |
+-------------+-------+
| 肖申克的救赎 | 犯罪 |
| 肖申克的救赎 | 剧情 |
| 霸王别姬 | 剧情 |
| 霸王别姬 | 爱情 |
| 霸王别姬 | 同性 |
| 阿甘正传 | 剧情 |
| 阿甘正传 | 爱情 |
| 泰坦尼克号 | 剧情 |
| 泰坦尼克号 | 爱情 |
| 泰坦尼克号 | 灾难 |
| 这个杀手不太冷 | 剧情 |
| 这个杀手不太冷 | 动作 |
| 这个杀手不太冷 | 犯罪 |
LATERAL VIEW EXPLODE(split(types,"/")) view as type
解析:
① 通过split方法将types中的字符串切分为数组
② 通过EXPLODE方法将数组由一行数据转换为多行
③ 通过LATERAL VIEW 将EXPLODE转换的结果包装成一个名为view的一个侧写表,并且列名为type
④ 通过全连接将侧写表中的数据与原表 learn3.movie 中的一行数据进行全连接















 7927
7927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









