






在PyTorch中,模型可以通过两种方式保存和加载:保存整个模型(包括模型架构和参数)或仅保存模型的参数(state_dict)。
保存整个模型: 保存模型的架构和所有的权重参数。这样做的好处是可以直接加载使用,无需再定义模型架构,但是无法再对模型做出调整,不够灵活。
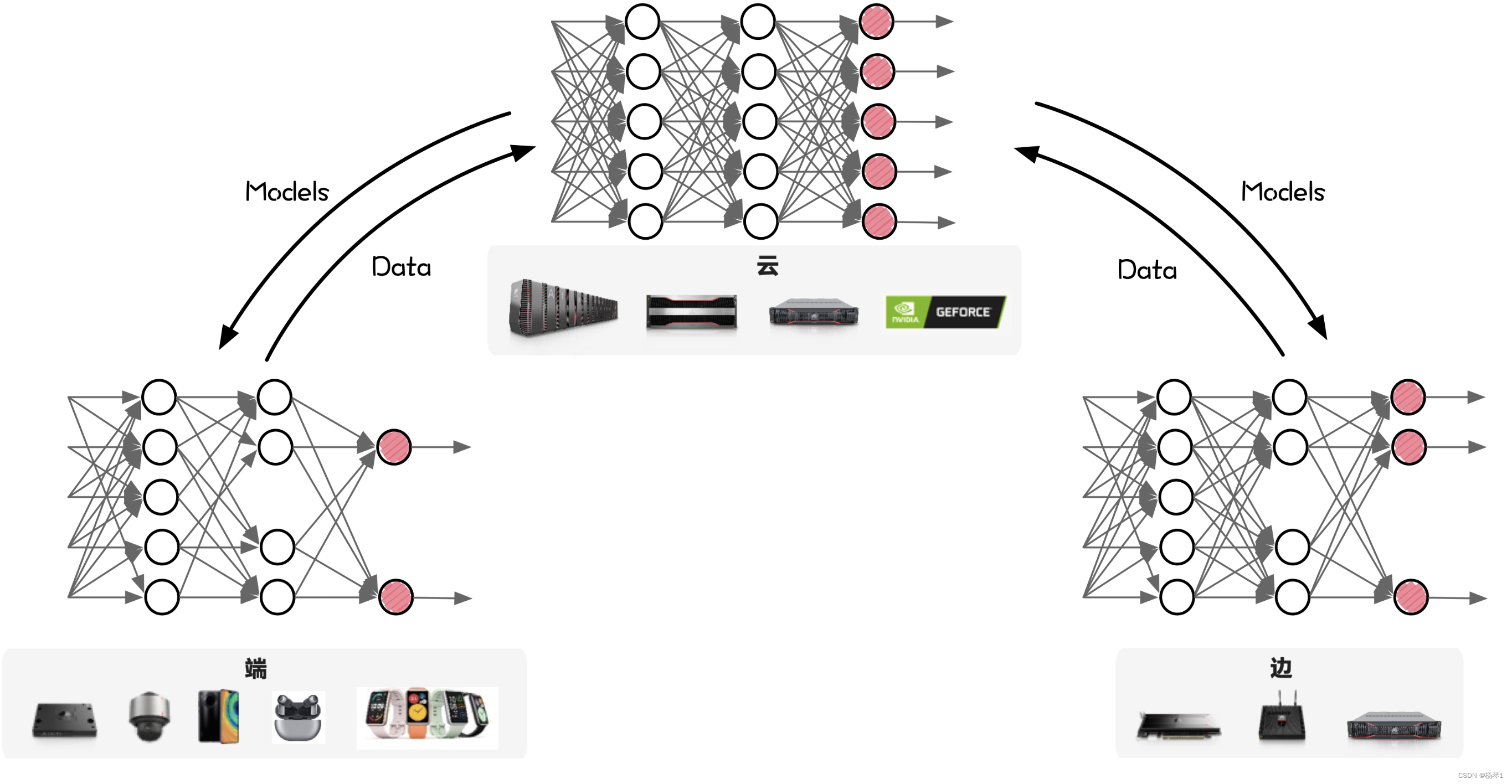
通常推荐此方式,因为它仅保存权重参数,体积更小,更灵活,需要时可用新定义的模型结构加载参数。
保存的参数通过model.state_dict()获取,得到一个有序字典类型:collections.OrderedDict,其中key是参数名称,value是保存了参数数值的tensor类型。
介绍了如何调整超参数,并进行网络模型训练。在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,本章节我们将介绍如何保存与加载模型。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
import numpy as np
import mindspore
from mindspore import nn
from mindspore import Tensor
def network():
model = nn.SequentialCell(
nn.Flatten(),
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10))
return model
保存和加载模型权重
保存模型使用save_checkpoint接口,传入网络和指定的保存路径:
model = network()
mindspore.save_checkpoint(model, "model.ckpt")
要加载模型权重,需要先创建相同模型的实例,然后使用load_checkpoint和load_param_into_net方法加载参数。
model = network()
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
[]
param_not_load是未被加载的参数列表,为空时代表所有参数均加载成功。
保存和加载MindIR
除Checkpoint外,MindSpore提供了云侧(训练)和端侧(推理)统一的中间表示(Intermediate Representation,IR)。可使用export接口直接将模型保存为MindIR。
model = network()
inputs = Tensor(np.ones([1, 1, 28, 28]).astype(np.float32))
mindspore.export(model, inputs, file_name="model", file_format="MINDIR")
MindIR同时保存了Checkpoint和模型结构,因此需要定义输入Tensor来获取输入shape。
已有的MindIR模型可以方便地通过load接口加载,传入nn.GraphCell即可进行推理。
nn.GraphCell仅支持图模式。
mindspore.set_context(mode=mindspore.GRAPH_MODE)
graph = mindspore.load("model.mindir")
model = nn.GraphCell(graph)
outputs = model(inputs)
print(outputs.shape)
(1, 10)















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









