






 本文详细探讨了C语言中的整型提升机制,如何在运算中处理不同类型整数,算术转换的规则,以及整型数据在内存中的存储,包括大小端字节序的概念和判断方法。
本文详细探讨了C语言中的整型提升机制,如何在运算中处理不同类型整数,算术转换的规则,以及整型数据在内存中的存储,包括大小端字节序的概念和判断方法。
一. 整型提升
1. 什么是整型提升
C的整型算术运算总是至少以缺省整型类型的精度来进行的。
为了获取足够精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这个转换过程称为整型提升。
2. 整型提升的意义
- 表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器的操作数的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
- 因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
- 通用CPU是难以直接实现两个8bit直接相加运算。所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或是unsigned int,然后才能送入CPU去执行运算。
3. 整型提升实例
整型的提升是按照数据类型的符号位来提升的
- 对于有符号数,发生截断后补符号位
- 对于无符号数,发生截断后直接补0。
负数的整型提升:

正数的整型提升:

实例1:
#include <stdio.h>
int main()
{
char a = 5;
char b = 126;
char c = a + b;
printf("%d\n", c);
return 0;
}
打印结果:
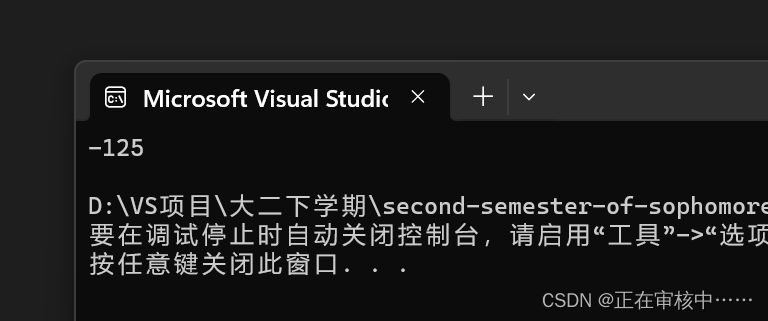
画图展示计算过程:

实例2:
#include <stdio.h>
int main()
{
char a = 0xb6;
short b = 0xb600;
int c = 0xb6000000;
if (a == 0xb6)
printf("a");
if(b == 0xb600)
printf("b");
if(c == 0xb6000000)
printf("c");
return 0;
}
打印结果:
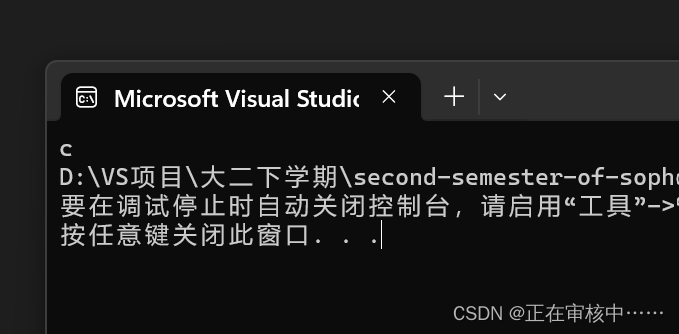
解释:这是因为a和b都不是int类型,在判断时会发生整型提升(高位补的是1),提升后值会改变,与原16进制不同。但c是int类型,不会改变。
实例3:
#include <stdio.h>
int main()
{
char c = 1;
printf("%zd\n", sizeof(c));//1
printf("%zd\n", sizeof(-c));//4
printf("%zd\n", sizeof(+c));//4
return 0;
}
打印结果:
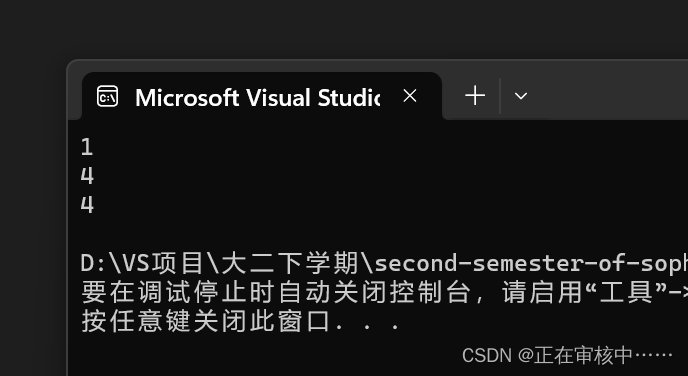
二. 算术转换
前文我们讨论的整型提升是当表达式大小达不到整型大小是才会转换为普通整型进行计算,但是当表达式大小是大于等于整型的呢?
它们在使用时也会发生转换,这种转换叫做算术转换。
- long double
- double
- float
- unsigned long int
- long int
- unsigned int
- int
从下到上类型的大小是从小到大,小类型会往大类型转换。
三. 整型数据存储
1. 大小端的介绍
要了解什么是大小端,首先我们先来观察整型数据在内存中的存储:
#include <stdio.h>
int main()
{
int a = 20;
//补码的16进制表示:0x00 00 00 14
int b = -10;
//补码的16进制表示:0xff ff ff f6
return 0;
}
我们对a和b进行内存监视:


通过观察,我们可以发现,在内存中存储的a和b的补码是倒着存储的。这是为什么呢?
其实内存在储存数据时一般有两种储存方式:

- 大端【字节序】存储:
把一个数据的高位字节序内容存放在低地址处,把低位字节序内容放在高地址处,就是大端字节序存储。- 小端【字节序】存储:
把一个数据的低位字节序内容存放在低地址处,把高位字节序内容放在高地址处,就是小端字节序存储。
注意:
- 大端字节序和小端字节序描述的是一个数据在内存中进行存储时到底是按什么顺序进行存储的。
- char类型的字符进行存储时没有大小端序列之分,因为它只有一个字节,而大小端讨论的是字节的顺序,要>=2个字节。
- 是机器的硬件决定了是大端还是小端存储,与当前编译器无关。
2. 判断当前机器的字节序
#include <stdio.h>
int main()
{
int a = 1;
if (*(char*)&a == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}
要判断当前机器是大端存储还是小端存储,其实思路非常简单:
我们可以对整数1进行操作,它的二进制为:00000000000000000000000000000001,
转换成16进制为:0x00 00 00 01,
根据上文介绍,a在内存中有两种存储方式:

我们可以发现它们的第一个字节有明显差异,只要我们取出a的第一个字节,判断是00(打印出来就是0)还是01(打印出来就是1),如果打印结果为1,则当前机器是小端存储,若是0,则当前机器是大端存储。
上述代码的输出结果为:
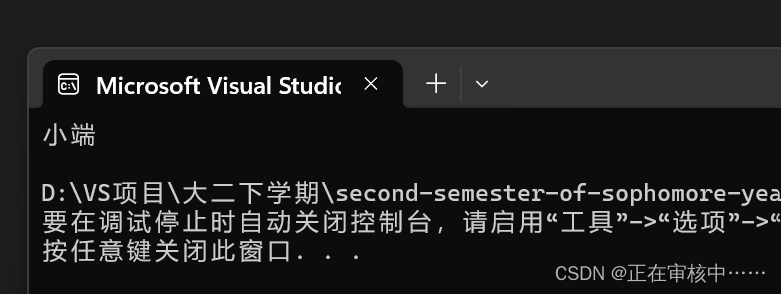
我们可知当前机器是小端字节序存储。















 1880
1880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









