







💓博主CSDN主页:麻辣韭菜-CSDN博客💓
⏩专栏分类:C++知识分享⏪
🚚代码仓库:C++高阶🚚
🌹关注我🫵带你学习更多C++知识
🔝🔝
目录
一.二叉搜索树的定义
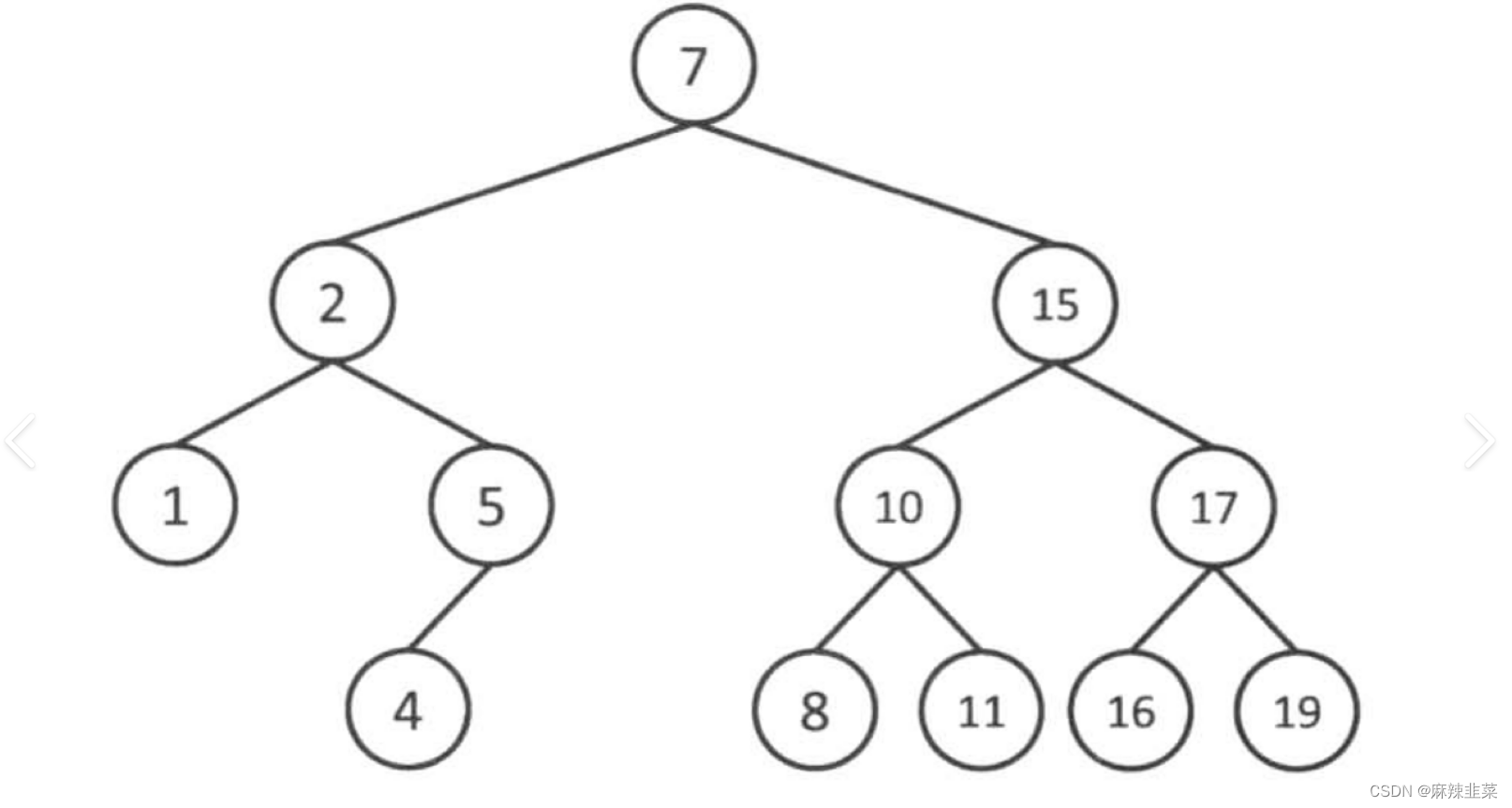
观察上图,我们可以发现根节点7的左边节点是小于右边的节点,左子树的上所有的节点都小于根节点,右子树的所有节点都大于根节点。而且根的左右子树也都是搜索二叉树
二. 二叉搜索树循环操作
1. 二叉搜索树的插入
先定义出二叉搜索树结构
//定义二叉树节点
template<class K>
struct BSTreeNode
{
BSTreeNode* _left;
BSTreeNode* _right;
K _key;
BSTreeNode(const K& key)
:_left(nullptr)
,_right(nullptr)
,_key(key)
{}
};
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
private:
Node* _root = nullptr;
};二叉搜索树插入实现方法↓
public:
//二叉搜索树插入实现
bool Insert(const K& key)
{
if (_root == nullptr) //第一次就不用说了。
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key) //小于要插入的数就在右子树
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key) //大于要插入的数就在左子树
{
parent = cur;
cur = cur->_left;
}
else // 相等后面AVL 红黑在说。
{
return false;
}
}
cur = new Node(key);
//链接
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}这里有个细节必须要说以下记录下父节点,cur出了作用域就销毁了,我们在链接过程中是找不到cur,就存在内存泄漏了野指针问题。先编写个中序遍历函数打印看看是不是对的
//中序遍历函数
void Inorder()
{
_InOrder(_root);
cout << endl;
}
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}我们在主函数中,调中序函数传参是个问题,我们在类的内部再实现一个调用中序遍历的函数。

打印结果没有问题,接着实现查找和删除
2. 二叉搜索树的查找
bool Find(const K& key)
{
if (_root == nullptr) //如果二叉树为空直接返回假
{
return false;
}
Node* cur = _root;
while (cur)//遍历左右子树
{
if (cur->_key < key) // 根小于要查找数右子树找
{
cur = cur->_right;
}
else if (cur->_key > key) // 根大于要查找数左子树找
{
cur = cur->_left;
}
else //等于就是找到了 返回真
{
return true;
}
}
return false; //循环结束没找到返回假
}
3. 二叉搜索树的删除
删除比较复杂,先画图考虑各种左右子树情况
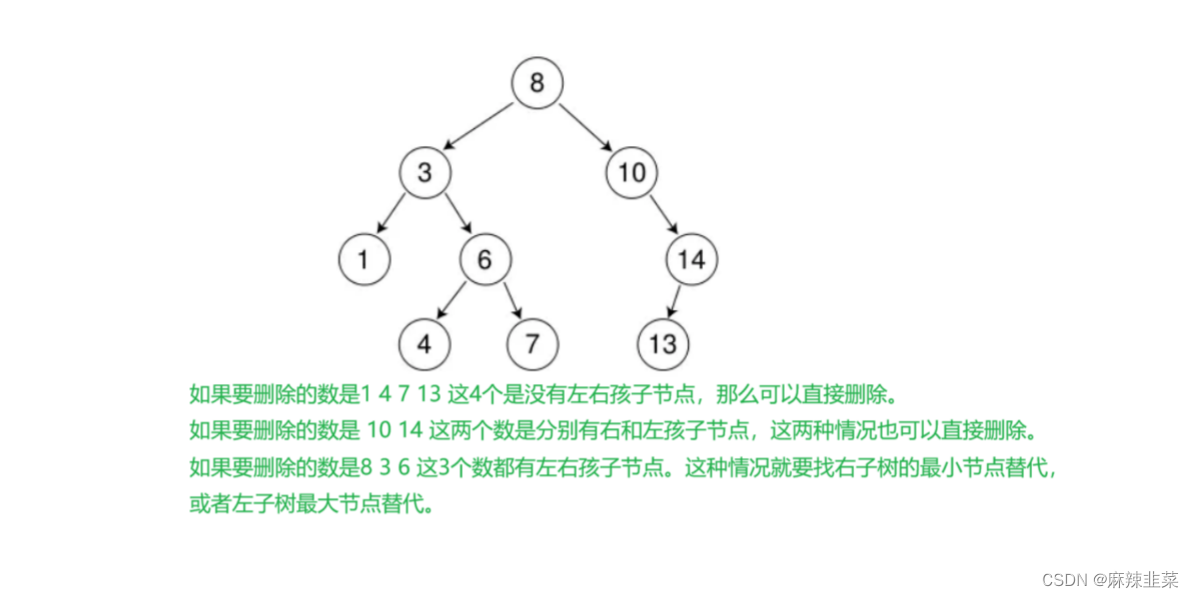
删除1 4 7 13 10 14 这6个数没有问题,直接无脑删除 父节点的左右指针指向nullptr就行。
问题的关键在于如何删除 8 3 6 这3个数?
替换法 比如 我要删除8 那就去左子树找到最大的那个节点 7。
把8修改成7 再删除7 这样就没有破坏二叉搜索树的结构。
bool Earse(const K& key)
{
if (_root == nullptr)
return false; //树为空直接返回
//遍历找到要删除的数
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else //删除
{
//左为空
if (cur->_left == nullptr)
{
if (cur == _root) //如果左子树全部为空,这时如果删除根节点,根节点是没有父亲节点。下面判断就是空指针。
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
//右为空
else if (cur->_right == nullptr)
{
if (cur == _root) //同理左子树
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
//两边都不为空 选择右子树小的节点或者左子树最大的节点。
//以左子树最大节点为例
else
{
Node* pmaxLeft = cur; //如果最大左子树的父亲节点设置为空,下面循环没有进去,父亲没有更新,下面条件判断就会出现空指针问题。
Node* maxLeft = cur->_left;
while (maxLeft->_right)
{
pmaxLeft = maxLeft;
maxLeft = maxLeft->_right;
}
cur->_key = maxLeft->_key;
if (pmaxLeft->_right == maxLeft) //这判断也是一样 如果上面循环没有进去 那么 8这个节点右子树就打乱结构了。
{
pmaxLeft->_right = maxLeft->_left;
}
else
{
pmaxLeft->_left = maxLeft->_left;
}
delete maxLeft;
}
return true;
}
}
return false;
}三.二叉搜索树递归操作
1.二叉搜索树递归算法的插入实现
bool InsertR(const K& key)
{
return _InsertR(_root, key);
}
bool _InsertR(Node* &root, const K& key)
{
if (root == nullptr)
root = new Node(key);
if (root->_key < key)
{
return _InsertR(root->_right, key);
}
else if (root->_key > key)
{
return _InsertR(root->_left, key);
}
else
{
return false;
}
}用递归算法插入,这里有个小细节,我们在类内部实现是需要再套一层函数如上图代码所示
套的那层实现递归算法。如果我们要插入的值大于根的值那就往右子树递归,反之就往左子树递归。一直递归到空,在空这里new一个节点,关键的来了,如果我们传参的值不是引用,那么函数递归返回 栈帧销毁,新开的节点,在上一层递归函数父亲节点没有连接的。
我们传参时用引用就非常巧妙,引用本来就是它自己,父节点的右或左都是它,天然连接。
2.二叉搜索树递归算法的查找实现
bool FindR(const K& key)
{
return _FindR(_root, key);
}
bool _FindR(Node* root ,const K& key)
{
if (root == nullptr)
return false;
if (root->_key == key)
return true;
else if(root->_key < key)
return _FindR(root->_right, key);
else
return _FindR(root->_left, key);
}递归查找就非常简单了,大于就右边找,反之左边找,找到返回真,递归到空还是没有返回假,或者本来就是空。
3.二叉搜索树递归算法的删除实现
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
//小于根就左边找
if (root->_key > key)
{
return _EraseR(root->_left, key);
}
//大于根就右边找
else if (root->_key < key)
{
return _EraseR(root->_right, key);
}
//相等
else
{ //删除
Node* del = root; //先记录要删除的节点,
//右为空直接删除
if (root->_right == nullptr)
root = root->_left;
//左为空直接删除
else if (root->_left == nullptr)
root = root->_right;
//两边都不为空,以右子树为例 找最小的
else
{
Node* MinRight = root->_right;
while (MinRight->right)
{
MinRight = MinRight->left; //找到右边最小的节点
}
swap(root->_key, MinRight->_key);//替换法:右边节点最小的值和根交换值
return _EraseR(root->_right, key);//替换了之后我们要删除就是它,
//我们再次递归是不是就变成了上面两种情况,左右各为空的情况。
}
delete del;
return true;
}
}递归算法删除的实现 我直接在代码讲解了。有那个地方不懂得可以私信我
四.二叉搜索树拷贝构造(赋值重载)与析构函数
BSTree() = default; // 制定强制生成默认构造
BSTree(const BSTree<K>& k)
{
_root = Copy(k._root);
}
//现代拷贝写法
BSTree<K>& operator=(BSTree<K> t)
{
swap(_root, t._root);
return *this;
}
~BSTree()
{
Destroy(_root);
}
//构造
Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newRoot = new Node(root->_key);
newRoot = Copy(root->_left);
newRoot = Copy(root->_right);
return newRoot;
}
//析构
void Destroy(Node* &root)
{
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
root = nullptr;
}这3个默认成员函数这里不在多讲 ,不太理解的可以先看C++类和对象-CSDN博客。对于递归算法不太理解,自己可以下去多画一画递归展开图
五.二叉搜索树应用场景
1. K模型
比如: 给一个单词 word ,判断该单词是否拼写正确 ,具体方式如下:以词库中所有单词集合中的每个单词作为 key ,构建一棵二叉搜索树在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
2. KV模型
该种方式在现实生活中非常常见:比如 英汉词典就是英文与中文的对应关系 ,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文 <word, chinese> 就构成一种键值对;再比如 统计单词次数 ,统计成功后,给定单词就可快速找到其出现的次数, 单词与其出现次数就是 <word, count> 就构成一种键值对 。
先讲之前K模型改造成KV模型
namespace gx
{
template<class K, class V>
struct BSTreeNode
{
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
K _key;
V _value;
BSTreeNode(const K& key, const V& value)
:_left(nullptr)
, _right(nullptr)
, _key(key)
, _value(value)
{}
};
template<class K, class V>
class BSTree
{
typedef BSTreeNode<K, V> Node;
public:
bool Erase(const K& key)
{
if (_root == nullptr)
return false; //树为空直接返回
//遍历找到要删除的数
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else //删除
{
//左为空
if (cur->_left == nullptr)
{
if (cur == _root) //如果左子树全部为空,这时如果删除根节点,根节点是没有父亲节点。下面判断就是空指针。
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
}
//右为空
else if (cur->_right == nullptr)
{
if (cur == _root) //同理左子树
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
//两边都不为空 选择右子树小的节点或者左子树最大的节点。
//以左子树最大节点为例
else
{
Node* pmaxLeft = cur; //如果最大左子树的父亲节点设置为空,下面循环没有进去,父亲没有更新,下面条件判断就会出现空指针问题。
Node* maxLeft = cur->_left;
while (maxLeft->_right)
{
pmaxLeft = maxLeft;
maxLeft = maxLeft->_right;
}
cur->_key = maxLeft->_key;
if (pmaxLeft->_right == maxLeft) //这判断也是一样 如果上面循环没有进去 那么 8这个节点右子树就打乱结构了。
{
pmaxLeft->_right = maxLeft->_left;
}
else
{
pmaxLeft->_left = maxLeft->_left;
}
delete maxLeft;
}
return true;
}
}
return false;
}
Node* Find(const K& key)
{
if (_root == nullptr) //如果二叉树为空直接返回假
{
return nullptr;
}
Node* cur = _root;
while (cur)//遍历左右子树
{
if (cur->_key < key) // 根小于要查找数右子树找
{
cur = cur->_right;
}
else if (cur->_key > key) // 根大于要查找数左子树找
{
cur = cur->_left;
}
else //等于就是找到了 返回真
{
return cur;
}
}
return nullptr; //循环结束没找到返回假
}
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key,value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key,value);
//链接
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
protected:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
private:
Node* _root = nullptr;
};
}在主函数写一个测试函数,看看结果
3.二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有 n 个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二 叉搜索树的深度的函数,即结点越深,则比较次数越多。但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜树:
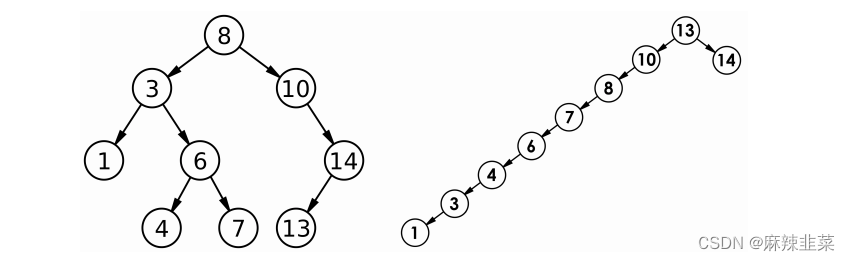
最优情况下,二叉搜索树为完全二叉树 ( 或者接近完全二叉树 ) ,其平均比较次数为: $log_2 N$最差情况下,二叉搜索树退化为单支树 ( 或者类似单支 ) ,其平均比较次数为: $\frac{N}{2}$问题:如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,二叉搜索树的性能都能达到最优?下篇讲解 AVL 树和红黑树就可以上场了。















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









