






循环字典
字典是一个键值对,初学者可能有点不习惯如何去循环一个字典:
方法1:循环key
scores = {'zhangsan':98, 'lisi':89, 'maishu':96}
for name in scores:
print(f'{name}:{scores[name]}')
- 默认情况下,循环字典,其实是循环的字典的keys,所以name就是一个个key。
- 如果需要访问value,可以通过scores[name]来取用。
执行结果:
zhangsan:98
lisi:89
maishu:96
[Finished in 15ms]
因为默认循环的就是keys,下面的代码和上面是完全一样的原理:
for name in scores.keys():
print(f'{name}:{scores[name]}')
我们调用了scores.keys()方法获得key的列表,再去循环它。这和上面效果是一样的。
方法2:循环key和value
如果想要更方便的取用key和value,可以这样写:
for name, score in scores.items():
print(f'{name}:{score}')
通过items()函数,把字典转成了一个(key, value)元组的列表,这样就可以直接访问key和value了。
代码中为了更加直观,我们用了name和score表示key和value。
注意这里还用到了Python的自动开包功能,把元组自动变成两个变量。
方法3:打印序号
如果除了key和value,还想打印序号。期望的结果是这样的:
0 zhangsan 98
1 lisi 89
2 maishu 96
可以使用enumerate函数,代码如下:
scores = {'zhangsan':98, 'lisi':89, 'maishu':96}
for i, (name, score) in enumerate(scores.items()):
print(i, name, score)
先用items()函数转成元组的列表,再使用enumerate函数加上序号。
注意,因为是元组,for的变量中一定要加上括号:i, (name, score)。Python只会做简单的自动开包,这里还有个变量i,它就不会自动开包,它只是单个变量元组,需要加上括号。
职业发展
作为一个代码打工仔,对于绝大部分程序员来说,想要成为牛逼的真正挣钱程序员的路还很长,一刻都不能懈怠。
我们无法从HR角度,或者技术leader的角度来臆测哪种状态的面试更能获取面试官青睐。但通过我们积攒的大量的面试经验,大家多少可以推断一些成为有竞争力的程序员的一些必要条件。
大佬云集、资料丰富
当初我在字节认识一个非常非常资深的前辈,他到字节比我早三年,但因为各种原因级别不是很高。我当时问他,既然你对现状如此不满,为什么不想着离开寻找更好的机会呢?
他沉思了片刻跟我说,他说我现在在这里虽然待着不顺心,但是我接触到的人都是非常优秀的。我遇到问题,还可以和你们讨论讨论。我如果出去了,我要是再遇到问题,可能连一个讨论的人都没有。
我当时听听只是觉得有道理,现在再回想起来,感受非常深刻。三观、格局、能力,能够进入大公司的,这三个方面一般都不会太差。别的不说,就拿个人能力而言,我曾出国出差过几个月,有幸见识了许多各种海外名校的同事,和他们学习交流人工智能,这真的让我AI有了更深层次的认识。
除了优秀的同事之外,大公司里往往还有丰富的内部文档和资料。我当时在字节内部看到了很多优秀的文章,也有很多优秀的技术沙龙和分享。现在想起来两年下来,也没有去过几次,文章和资料看得也不算多,现在想想颇为遗憾。别的不说,就拿推荐领域而言,近些年质量不错的论文往往都来源于大公司尤其是国内的大公司,以腾讯、华为和头条为主。除了公开的论文,公司内部还有很多技术相关的资料和文档,这些真的可以说是有价无市,非常珍贵。
Python 知识手册

Linux 知识手册

爬虫查询手册

而且,这些资料不是扫描版的,里面的文字都可以直接复制,非常便于我们学习:
数据分析知识手册:

机器学习知识手册:

金融量化知识手册:

小编这次带来的,是从朋友那里薅到的一套完整的学习路线图,以及配套学习资料,它涵盖了Python学习的方方面面,且文献全彩,字迹清晰,很适合我们学习观看。


下面来看看资料详细内容:
一、Python基础
基础真的蛮重要的,因为Python的易应用性很容易让大家产生我什么都会了的感觉,但实际上还是不怎么会。


相关的视频学习资料: 
二、爬虫阶段
应该有很多人都对爬虫感兴趣吧?
爬虫不只是爬虫工程师会用到,业余时间也可以用来爬点自己想要的东西,又或者是做兼职也是可以的,比如日常办公自动化、电商抓取商品信息、分析销售数据做报表等等。
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
所以爬虫的简要学习路径大概有:
- 学习 Python 包并实现基本的爬虫过程
- 了解非结构化数据的存储
- 学习scrapy,搭建工程化爬虫
- 学习数据库知识,应对大规模数据存储与提取
- 掌握各种技巧,应对特殊网站的反爬措施
- 分布式爬虫,实现大规模并发采集,提升效率

相关的视频学习资料: 
三、Python数据分析
数据分析也是当下的一大热门方向,用Python来做的话比其他语言强很多。
但往往只会数据分析还是差点意思,如果能具备爬虫能力来爬取数据就更好了。(分析爬虫抓取的数据,分析规律,用于商业化)

相关的学习资料:

四、数据库与ETL数仓
企业需要定期将冷数据从业务数据库中转移出来存储到一个专门存放历史数据的仓库里面,各部门可以根据自身业务特性对外提供统一的数据服务,这个仓库就是数据仓库。
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。 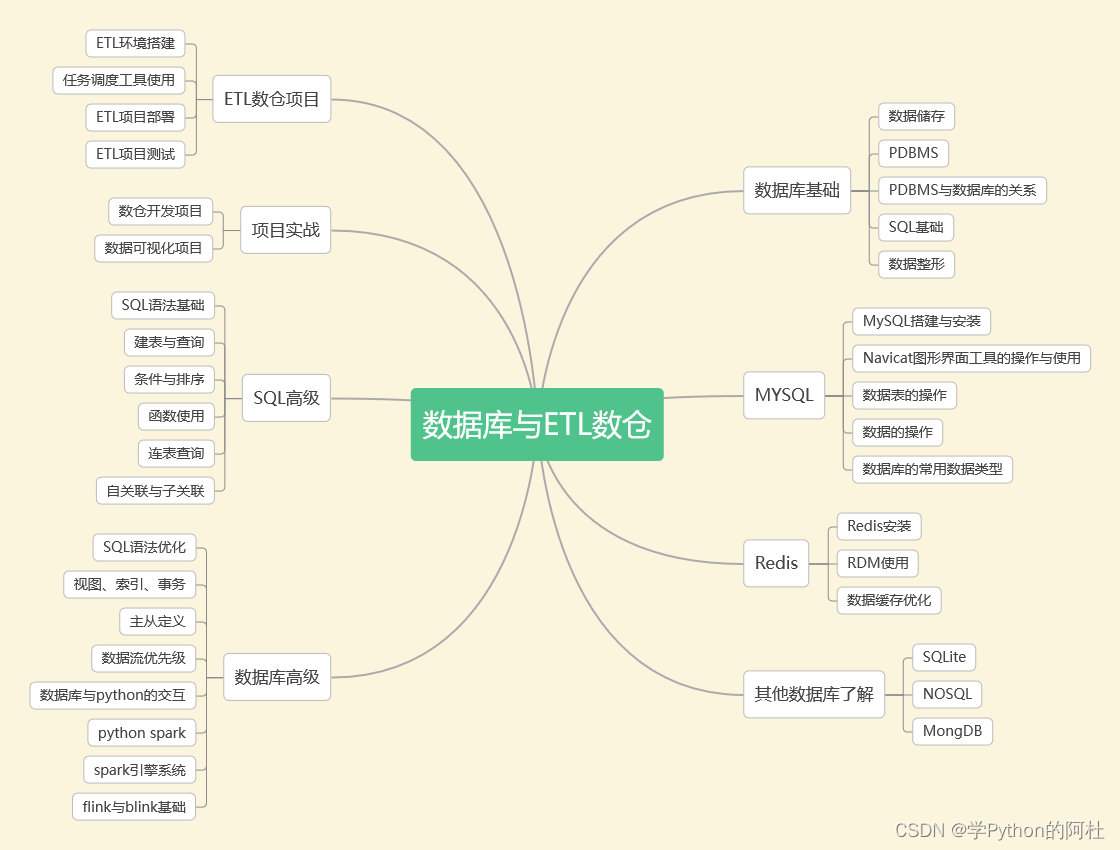 相关的学习资料:
相关的学习资料: 
五、Python机器学习
现在不是各种吹人工智能么,机器学习就是人工智能的一个分支,它的应用太广泛了,比如自然语言处理,搜索引擎,各种识别技术,数据挖掘等等。
这难度不用我多说了吧,不会点算法就别碰,一碰就是各种高斯过程回归、线性判别分析、决策树、线性回归…

相关的学习资料:

[所有资料已整合打包好,斯信我或者评论留个言领取即可!]















 2779
2779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









