






本节重点:
- 让学生了安装上Python,配置好环境变量
Python目前已支持所有主流操作系统,在Linux,Unix,Mac系统上自带Python环境,在Windows系统上需要安装一下,超简单
Windows安装
打开官网 https://www.python.org/downloads/windows/ 下载中心

测试安装是否成功
windows --> 运行 --> 输入cmd ,然后回车,弹出cmd程序,输入python,如果能进入交互环境 ,代表安装成功。
提示:以下是本篇文章正文内容,下面安装过程仅供参考
一、下载Python
Python官网下载地址:🔗
进入界面后点击Download Python
根据系统选择下载的版本,此处演示Windows的版本

下载的文件

二、安装过程
1)安装
1.双击python-3.9.2-amd64.exe文件

2. 勾选Add Python 3.9 to PATH,然后再点击Customize installation进入到下一步;

3.进入Optional Features后,不用操作,直接点击Next;

4.点击Browse进行自定义安装路径,也可以直接点击Install进行安装,点击install安装;

5.点击Disable path length limit(修改电脑中对程序字符长度的限制);

6.点击Close ,安装完成;

2)验证是否安装成功
1.在win查看最近添加或者直接搜索python


如何正确学习 Python
小编这次带来的,是从朋友那里薅到的一套完整的学习路线图,以及配套学习资料,它涵盖了Python学习的方方面面,且文献全彩,字迹清晰,很适合我们学习观看。


下面来看看资料详细内容:
一、Python基础
基础真的蛮重要的,因为Python的易应用性很容易让大家产生我什么都会了的感觉,但实际上还是不怎么会。


相关的视频学习资料:

二、爬虫阶段
应该有很多人都对爬虫感兴趣吧?
爬虫不只是爬虫工程师会用到,业余时间也可以用来爬点自己想要的东西,又或者是做兼职也是可以的,比如日常办公自动化、电商抓取商品信息、分析销售数据做报表等等。
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
所以爬虫的简要学习路径大概有:
- 学习 Python 包并实现基本的爬虫过程
- 了解非结构化数据的存储
- 学习scrapy,搭建工程化爬虫
- 学习数据库知识,应对大规模数据存储与提取
- 掌握各种技巧,应对特殊网站的反爬措施
- 分布式爬虫,实现大规模并发采集,提升效率

相关的视频学习资料:

三、Python数据分析
数据分析也是当下的一大热门方向,用Python来做的话比其他语言强很多。
但往往只会数据分析还是差点意思,如果能具备爬虫能力来爬取数据就更好了。(分析爬虫抓取的数据,分析规律,用于商业化)

相关的学习资料:

四、数据库与ETL数仓
企业需要定期将冷数据从业务数据库中转移出来存储到一个专门存放历史数据的仓库里面,各部门可以根据自身业务特性对外提供统一的数据服务,这个仓库就是数据仓库。
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。
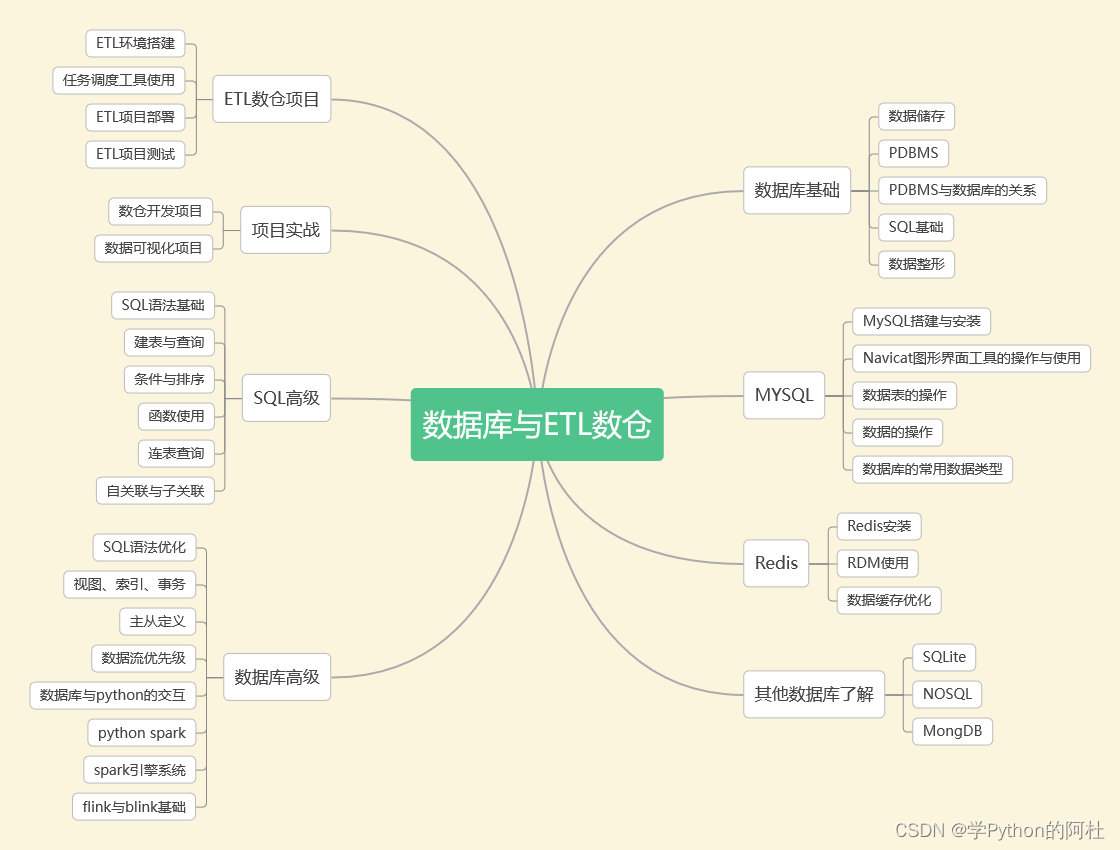 相关的学习资料:
相关的学习资料:

五、Python机器学习
现在不是各种吹人工智能么,机器学习就是人工智能的一个分支,它的应用太广泛了,比如自然语言处理,搜索引擎,各种识别技术,数据挖掘等等。
这难度不用我多说了吧,不会点算法就别碰,一碰就是各种高斯过程回归、线性判别分析、决策树、线性回归…

相关的学习资料:
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









