






资料解读:大模型在办公方向的实践与思考某著名企业
详细资料请看本解读文章的最后内容。在当今数字化办公的大趋势下,大模型技术正逐渐渗透到办公领域的各个角落,为办公效率的提升和办公体验的优化带来了新的可能。某著名企业在大模型办公应用方面进行了诸多实践与探索,成果斐然。
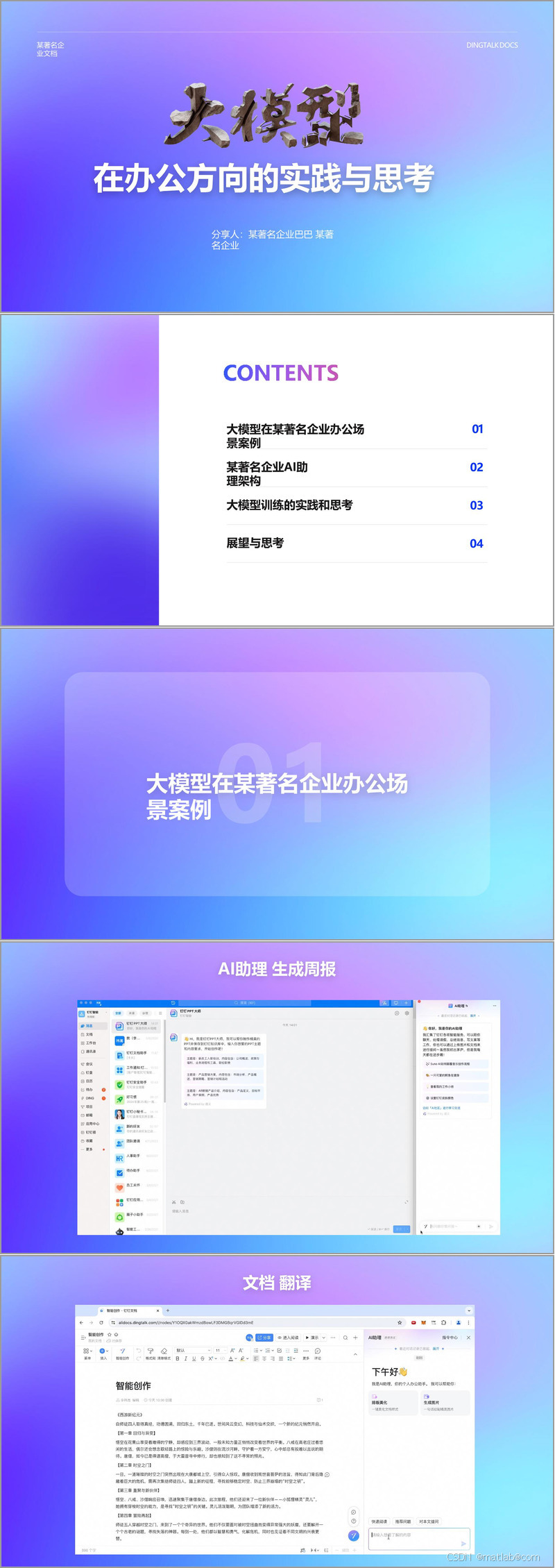
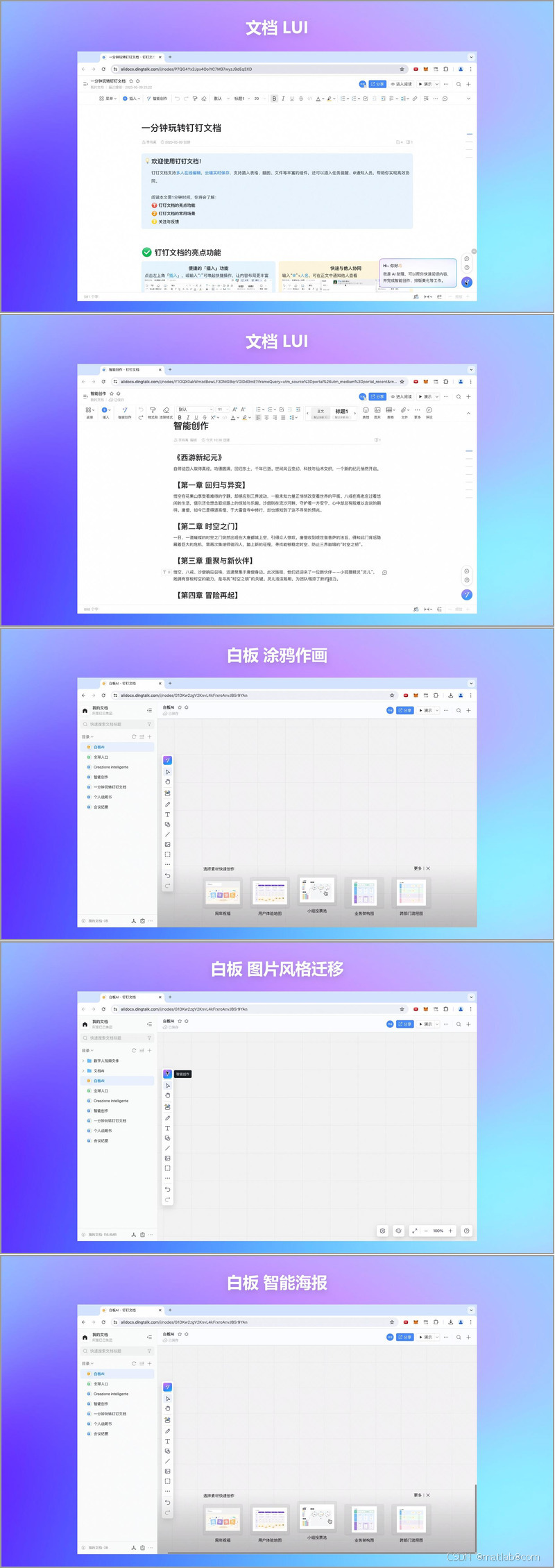
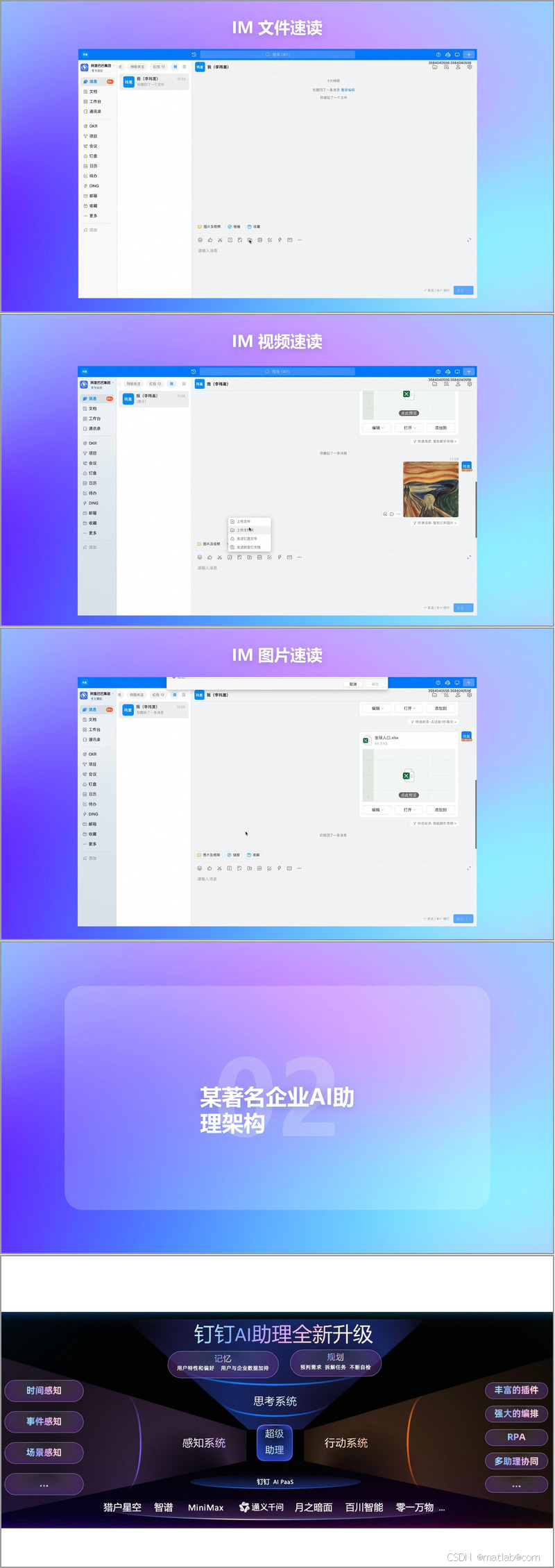
某著名企业在办公场景中积极引入大模型技术,带来了一系列创新应用。以 AI 助理为例,它能够生成周报,帮助员工快速总结工作内容,节省时间和精力。在文档处理方面,不仅可以实现文档翻译,打破语言壁垒,还能进行文档 LUI(可能是指文档的某种交互优化,具体需结合更多背景信息确定),提升文档处理的便捷性。白板功能也因大模型的加入变得更加智能,支持涂鸦作画、图片风格迁移以及智能海报制作,为创意表达和视觉展示提供了更多可能性。在即时通讯(IM)场景中,大模型实现了文件、视频和图片的速读,帮助用户快速获取关键信息,提高信息处理效率。
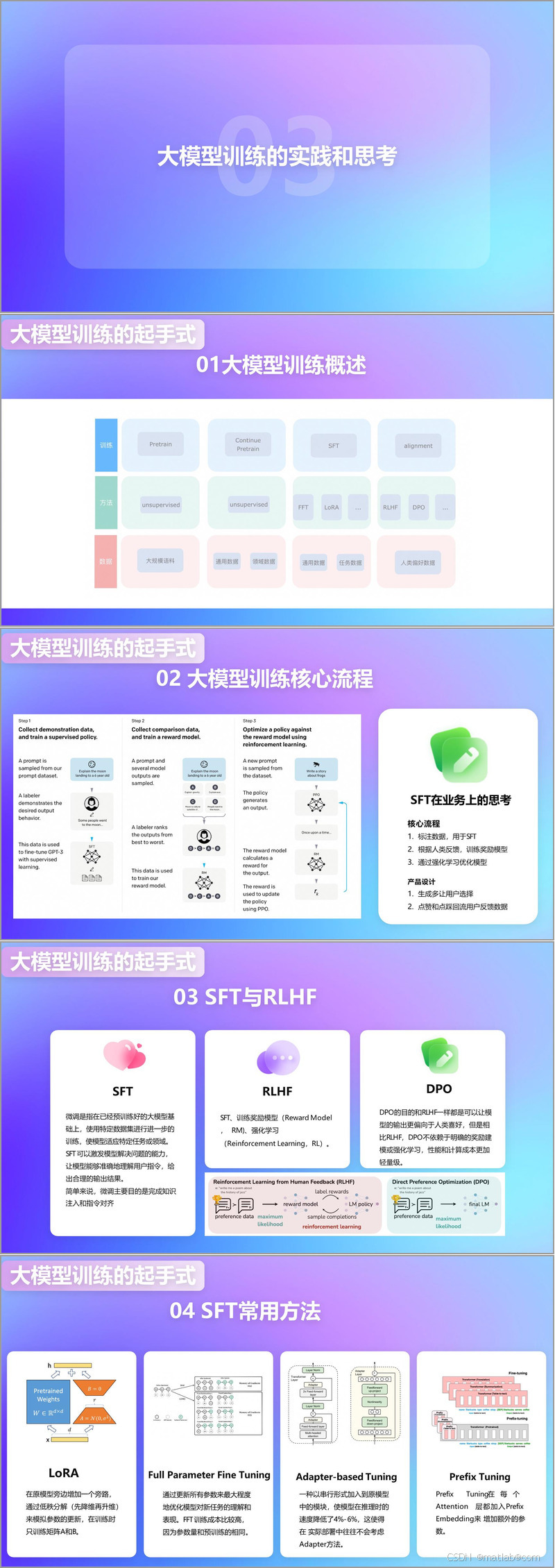
深入探究大模型训练,其过程有着独特的起手式和核心流程。训练起手式中,微调是关键环节。微调是基于预训练好的大模型,利用特定数据集进一步训练,使模型适应特定任务或领域,主要实现知识注入和指令对齐,激发模型解决问题的能力,让模型准确理解用户指令并给出合理输出。在核心流程中,首先要标注数据用于 SFT(Supervised Fine-Tuning,监督微调),接着根据人类反馈训练奖励模型,再通过强化学习优化模型。在产品设计上,会生成多种结果让用户选择,并将用户点赞和点踩的反馈数据回流,以不断优化模型。
SFT 与 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)在大模型训练中起着重要作用。此外,还有 DPO(Direct Preference Optimization,直接偏好优化),它和 RLHF 目的相同,都是使模型输出更符合人类喜好,但 DPO 性能和计算成本更轻量级,不依赖明确的奖励建模或强化学习。在 SFT 常用方法上,有多种选择。LoRA 方法是在原模型旁增加旁路,通过低秩分解模拟参数更新,训练时只需训练特定矩阵,成本较低。Full Parameter Fine Tuning 则是更新所有参数,能最大程度优化模型对新任务的理解,但训练成本高。Adapter-based Tuning 以串行形式加入模块,不过会使推理速度降低,实际部署中较少考虑。Prefix Tuning 在每个 Attention 层加入 Prefix Embedding 增加额外参数。
在大模型训练过程中,数据的重要性不可忽视。在选择预训练模型时,无论是 Chat model 还是 base model,都要谨慎考虑数据因素。过于领域化的数据可能导致灾难性遗忘,但在某些业务场景中,可通过意图识别和业务专属模型解决。同时,数据过多可能引发过拟合问题。在文本数据方面,短文本多涉及用户交互,而长文本多以 “文件” 形式表达,“文档理解” 成为关键。此外,像 LR(学习率)、warmup(预热步骤)、Epoch(训练轮数)等参数的设置,目的是让 Loss 更快收敛,优化模型训练效果。
从具体办公场景分析来看,在文档生成长图场景中,某著名企业文档可转换为多种类型文档,如长图、PDF、word、ppt 等,并且支持各类型文件的相互转换,满足了不同用户在不同场景下的文档格式需求。在文档速读场景里,文档与大模型的交互效果取决于文档还原度,同时还要解决超大文档、超长文档的处理难题。文档问答场景则依赖 RAG(Retrieval-Augmented Generation,检索增强生成)技术,包括文档理解、分片、向量化,Query 优化、召回策略以及排序策略等环节,在架构和产品设计上遵循先学习再检索的原则。
以 AIPPT 的大模型训练实践为例,其核心任务是生成 PPT,训练目标聚焦于 PPT 内存结构。在复杂场景下的推理与训练中,采用分治推理方案,用树描述整体任务并进行遍历推理。在训练时,需要具备拆解任务、叶子结点独立计算以及任务回溯父节点的数据集,以保障训练的有效性和准确性。
展望未来,大模型在办公领域的发展面临着诸多挑战与机遇。安全问题至关重要,包括模型训练的数据安全和模型应用的数据安全,只有确保数据安全,才能让用户放心使用。同时,持续提升大模型效果、降低成本也是关键。随着技术的不断发展,多模态技术迅速崛起,未来大模型有望融合更多模态信息,如语音、图像等,为办公场景带来更加丰富和智能的体验。
大模型在某著名企业办公方向的实践已经取得了显著成果,但仍有很大的发展空间。相关从业者需要不断探索和创新,以应对各种挑战,充分挖掘大模型在办公领域的潜力。接下来请您阅读下面的详细资料吧。

篇幅所限,本文只能提供部分资料内容,完整资料请看下面链接


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











