






1.项目介绍
主要内容:通过影刀RPA循环爬取不同页面的详情信息。
下载链接:影刀RPA - 影刀官网 (yingdao.com)
2.图文展示
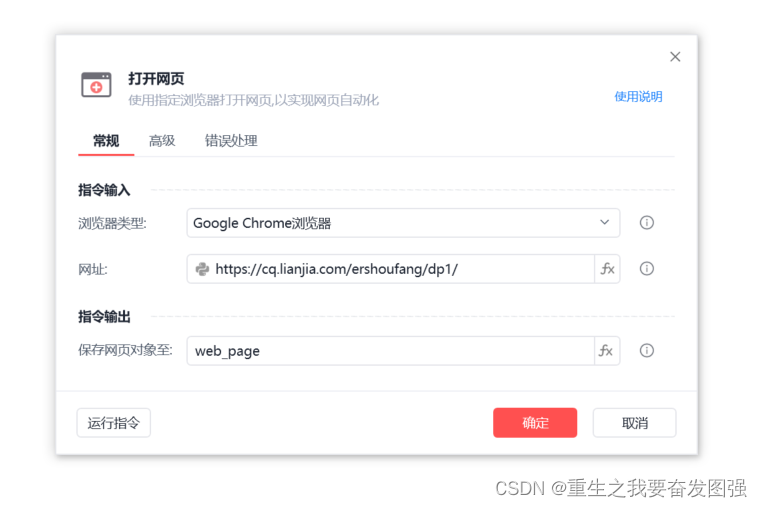
1.打开影刀工具,选择打开网页,需要注意的是选择已下载影刀插件的浏览器
网页自动化--打开网页
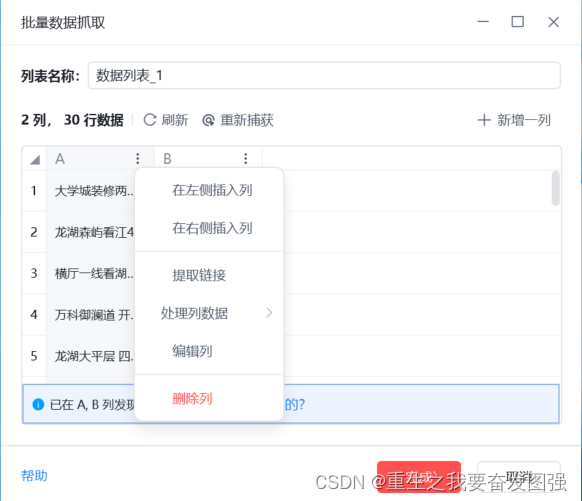
2.批量数据抓取
网页自动化--数据提取--批量数据抓取--去元素库选择--批量抓取数据
通过ctrl+鼠标左键抓取,因为我们需要的是具体网页信息,所以删除掉其余信息。
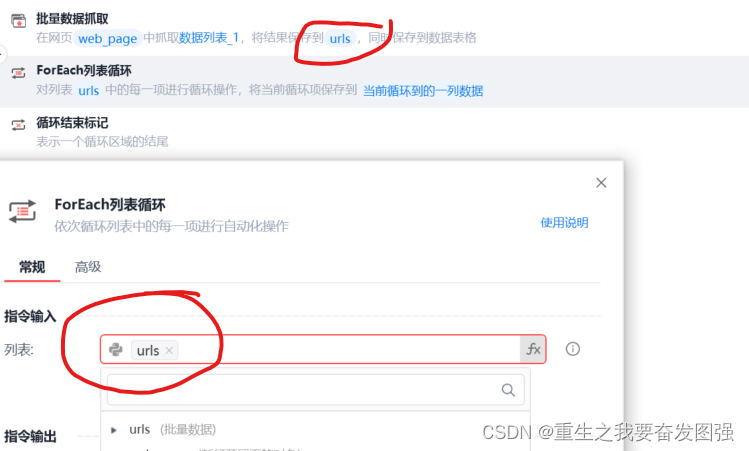
3.ForEach列表循环
循环--ForEach列表循环,注意这里的选项一定要对,是刚刚爬取数据存储的地方
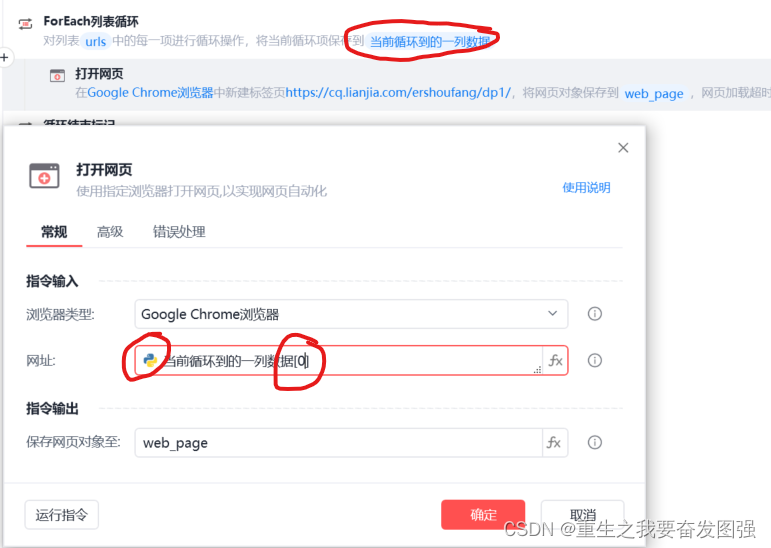
4.在循环中加入打开网页,注意这里的三个选项。在这步之后加上关闭网页,形成一个闭环,这时就可以选择点击正中心上方的运行开启测试了。测试无误,开启下一步。
5.获取元素信息
网页自动化--数据提取--获取元素信息,同步骤2.
6.写入内容至表格数据
最后项目基本完成,选择下方的数据表格查看效果即可。
整体的结构如下图:
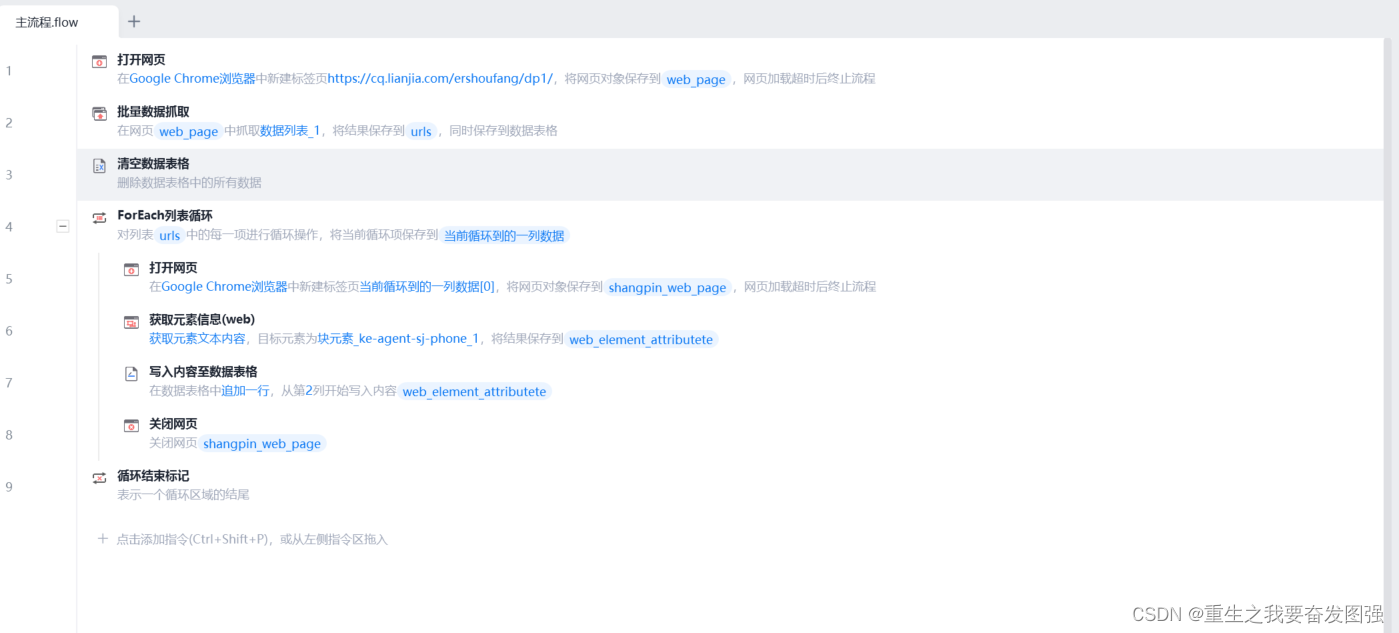
3.总结
最后希望此篇可以为大家提供一些帮助,第一次用影刀,也是第一次写这种类型的博客,表述可能存在一定的问题,欢迎大家在评论区留言,也希望高手可以指正,会及时回复!

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









