






篇幅所限,本文只提供部分资料内容,完整资料请看下面链接
https://download.csdn.net/download/2301_78256053/89666470
资料解读:《基于DeepSeek的数据治理》
详细资料请看本解读文章的最后内容
作为数据治理领域的专业研究者,笔者对这份由数桨AI实验室发布的《基于DeepSeek的数据治理》技术文档进行了深入研读。这份2025年2月发布的资料系统性地阐述了人工智能技术在数据治理领域的创新应用,特别是深度求索公司开发的DeepSeek系列大模型如何赋能数据治理全流程。以下将从技术基础、核心能力、应用场景和实施建议四个维度进行全面解读。
一、人工智能技术基础架构
文档开篇首先构建了完整的人工智能技术认知框架。人工智能(AI)被明确定义为"模拟人类智能的技术系统",其核心在于使机器具备学习、思考和决策能力。技术全景图显示,现代AI已形成多层次的技术体系:
在算法层面,机器学习作为基础支撑,可分为监督学习、无监督学习和强化学习三大范式。其中深度学习通过模拟人脑神经元网络结构,实现了对复杂数据特征的自动提取。特别值得注意的是,文档重点介绍了大语言模型(LLM)和生成式AI的最新进展,这正是DeepSeek系列模型的技术根基。
关于大模型性能的关键影响因素,文档提出了"三要素理论":模型参数规模、数据质量与规模、计算资源配置。研究表明,模型参数量与性能表现呈非线性增长关系,当参数规模达到临界点(如GPT-3的1750亿参数)时,模型会展现出惊人的涌现能力。DeepSeek-V3作为6710亿参数的混合专家(MoE)模型,正是这一理论的实践典范。
二、DeepSeek的核心技术能力
文档详细剖析了DeepSeek系列模型的六大核心能力,这些能力构成了赋能数据治理的技术基础:
- 语言理解与分析能力
- 词法分析:支持高精度分词、命名实体识别(NER)和词性标注
- 句法分析:可解析复杂句子的依存关系
- 实体匿名化:自动识别并脱敏敏感信息
- 信息抽取与结构化能力
- 关键词提取:基于上下文语义的权重分析
- 实体关系抽取:构建(头实体,关系,尾实体)三元组
- 事件抽取:从非结构化文本中识别结构化事件
- 分类与聚类能力
- 零样本/小样本分类:解决标注数据稀缺问题
- 情感分析:识别文本的情感极性
- 文本聚类:自动发现潜在的主题分布
- 受控文本生成能力
- 风格控制:可模仿特定作者的写作风格
- 数据到文本:将结构化数据转化为自然语言描述
- 倾向性控制:按需调整生成内容的情感或立场
- 深度理解与问答能力
- 常识推理:基于世界知识的逻辑判断
- 跨语言问答:处理多语言混合的查询
- 意图识别:准确解析用户真实需求
- 代码与SQL生成能力
- 多语言编程:支持Java、Python等主流语言
- 数据库操作:自动生成符合规范的SQL语句
- 脚本编写:根据需求生成可执行脚本
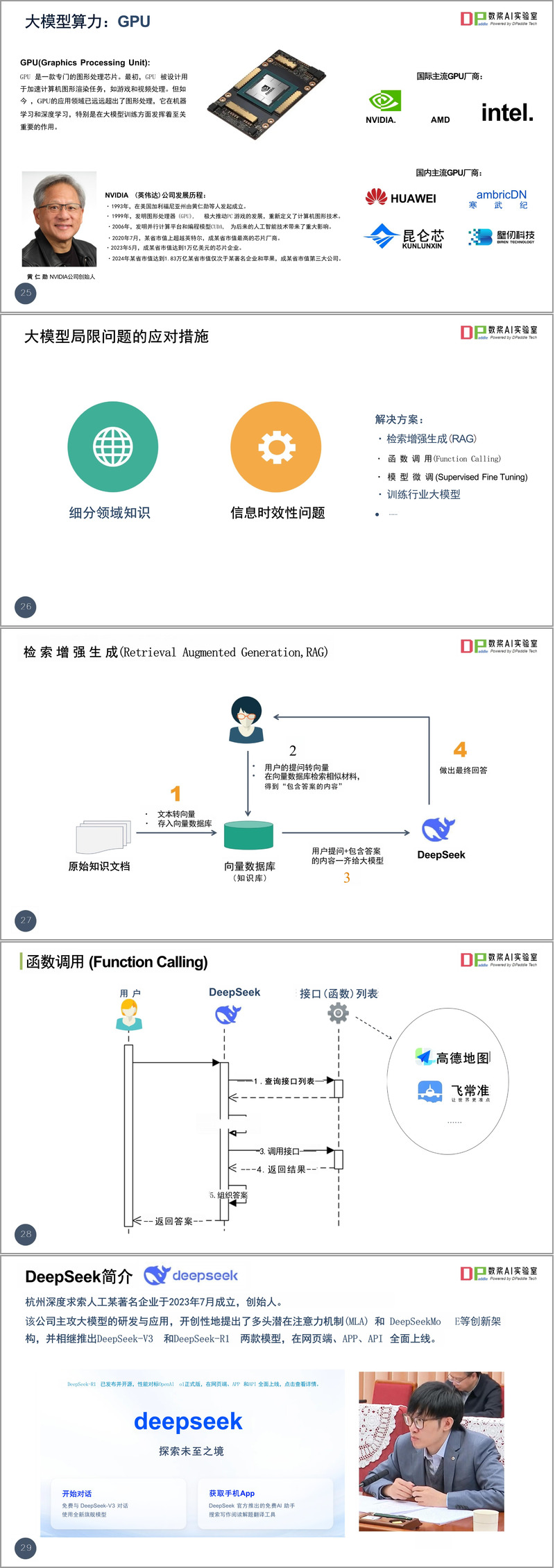
三、数据治理全流程赋能方案
文档第三章系统阐述了DeepSeek在数据治理各阶段的具体应用方案:
1. 数据资产化管理流程
- 识别阶段:自动摸排业务场景和数据产品
- 确认阶段:智能分析数据权属关系
- 入表阶段:生成符合会计准则的资产报表
- 披露阶段:辅助编制财务报告附注说明
2. 数据治理关键技术应用
- 数据清洗:自动修复格式错误、填补缺失值
- 质量检测:基于规则引擎的异常识别
- 元数据管理:自动提取技术/业务元数据
- 血缘分析:可视化展示数据流转路径
3. 典型行业解决方案
文档通过零售业客户数据标准化案例,展示了如何利用DeepSeek实现:
- 多源异构数据的自动对齐
- 脏数据的智能清洗与转换
- 数据质量规则的自动生成
- 标准化报告的智能撰写
四、实施建议与未来展望
基于实践经验,文档最后提出了四点关键建议:
- 需求导向的顶层设计
建议企业建立"数据治理委员会",从战略高度统筹规划,避免技术驱动的盲目投入。某省电网案例显示,明确业务需求可使项目成功率提升40%。 - 人才梯队建设
提出"金字塔"人才培养模型:基础层普及数据素养,中间层培养技术骨干,顶层培育架构专家。建议配置专职数据治理师岗位。 - 持续优化机制
推荐采用PDCA(计划-执行-检查-处理)循环,每季度进行效果评估。某金融机构通过持续优化,三年内数据质量指数提升62%。 - 生态体系建设
强调标准规范、安全管控和组织协同的三位一体。建议参考DCMM(数据管理能力成熟度)模型分阶段实施。
结语
这份技术文档不仅系统梳理了大模型赋能数据治理的理论框架,更提供了详实的实践指南。DeepSeek系列模型展现出的语言理解、信息抽取和智能生成能力,为破解数据治理中的质量管控、安全合规和价值挖掘等难题提供了创新解决方案。特别是在非结构化数据处理、自动化文档生成等传统难点领域,展现出显著的技术优势。
接下来请您阅读下面的详细资料吧


















 4841
4841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











