







节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以文末加入我们。
混元DiT是一个基于Diffusion transformer的文本到图像生成模型,此模型具有中英文细粒度理解能力。
为了构建混元DiT,我们精心设计了Transformer结构、文本编码器和位置编码。我们构建了完整的数据管道,用于更新和评估数据,为模型优化迭代提供帮助。为了实现细粒度的文本理解,我们训练了多模态大语言模型来优化图像的文本描述。
最终,混元DiT能够与用户进行多轮对话,根据上下文生成并完善图像。

该模型具备如下优势
-
中文元素理解:混元DiT提供双语生成能力,中国元素理解具有优势。
-
长文本理解能力:混元DiT能分析和理解长篇文本中的信息并生成相应艺术作品。
-
细粒度语义理解:混元DiT能捕捉文本中的细微之处,从而生成完美符合用户需要的图
-
多轮对话文生图:混元DiT可以在多轮对话中通过与用户持续协作,精炼并完善的创意构想。
开源代码链接:
https://github.com/Tencent/HunyuanDiT
最佳实践
按照混元DiT文生图模型的模型页面,需要的计算显存如下:
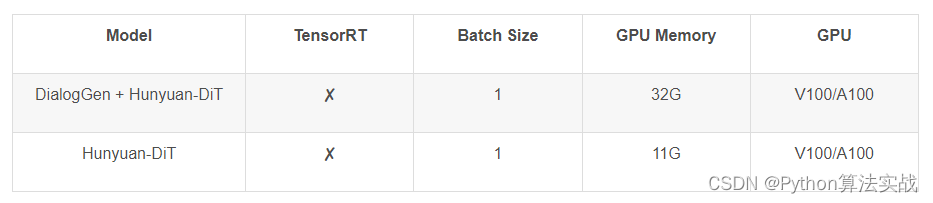
环境配置和安装
-
python 3.10及以上版本
-
pytorch推荐2.0及以上版本
下载和部署
第一步:clone代码到本地
git clone https://github.com/tencent/HunyuanDiT
cd HunyuanDiT
# 安装魔搭镜像中缺少的依赖
pip install loguru==0.7.2
第二步:下载模型
# 使用git下载模型
git clone https://www.modelscope.cn/modelscope/HunyuanDiT.git
# 或者使用modelscope SDK下载模型
# from modelscope import snapshot_download
# model_dir = snapshot_download('modelscope/HunyuanDiT')
第三步:因为混元DiT依赖clip-vit-large-patch14-336,需要提前下载该模型到工作目录
# 下载clip模型
git clone https://www.modelscope.cn/AI-ModelScope/clip-vit-large-patch14-336.git ./openai/clip-vit-large-patch14-336
第四步:按照pr修改对应的代码
Pr地址:
https://github.com/Tencent/HunyuanDiT/pull/16
修改的文件如下:

第五步:运行推理接口
python sample_t2i.py --prompt "渔舟唱晚"
在HunyuanDiT/results/文件夹下得到结果:

显存占用:

中文prompt效果体验
小编用一些中文的成语,古诗等测试了该模型的效果,出图稳定,分辨率高,且效果不错,尤其是单张图多个实体上,依然保障了很好的出图质量。非常开心看到优秀的支持中文的文生图模型,魔搭社区未来期待与社区开发者同行,一起研究和推动基于DiT模型上如LoRA,控图等生态发展。
龟兔赛跑

守株待兔

三只羊驼坐在麻将桌上

一只红色的小狐狸和一只黑色的老鹰在森林中对话

醉后不知天在水,满船清梦压星河

技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流


















 5731
5731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









