







 本文通过IMDB、路透社和波士顿房价三个数据集,介绍深度学习在分类和回归问题中的应用。包括数据预处理、模型构建、编译、验证及预测等步骤,还提及防止过拟合和K倍验证等技术,阐述不同问题适用的损失函数和评估指标。
本文通过IMDB、路透社和波士顿房价三个数据集,介绍深度学习在分类和回归问题中的应用。包括数据预处理、模型构建、编译、验证及预测等步骤,还提及防止过拟合和K倍验证等技术,阐述不同问题适用的损失函数和评估指标。
分类电影评论:一个二元分类的例子
IMDB数据集
一组来自互联网电影数据库的5万个高度两极化的评论。他们被分为25000
条培训评论和25000条测试评论,每一组包括50%的负面评论和50%的正面评论。为什么
要使用单独的训练集和测试集?因为你不应该在你以前训练它的相同数据上测试机器学
习模型!仅仅因为一个模型在训练数据上表现良好并不意味着它在它从未见过的数据上
表现良好;你关心的是你的模型在新数据上的表现(因为你已经知道你的训练数据的标
签——显然你不需要你的模型来预测这些)。例如,你的模型最终可能只记忆训练样本和
目标之间的映射,这对于预测模型从未见过的数据目标的任务是无用的。就像MNIST数据集一样,IMDB数据集与Keras一起打包。它已经进行了预处理:评论(单词序列)已经变成了整数序列,其中每个整数代表字典中的一个特定单词。
加载IMDB数据集
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)
#从imdb中下载词汇数据
#num_words = 10000将常用的前一万的单词进行编号,超过的则表示2
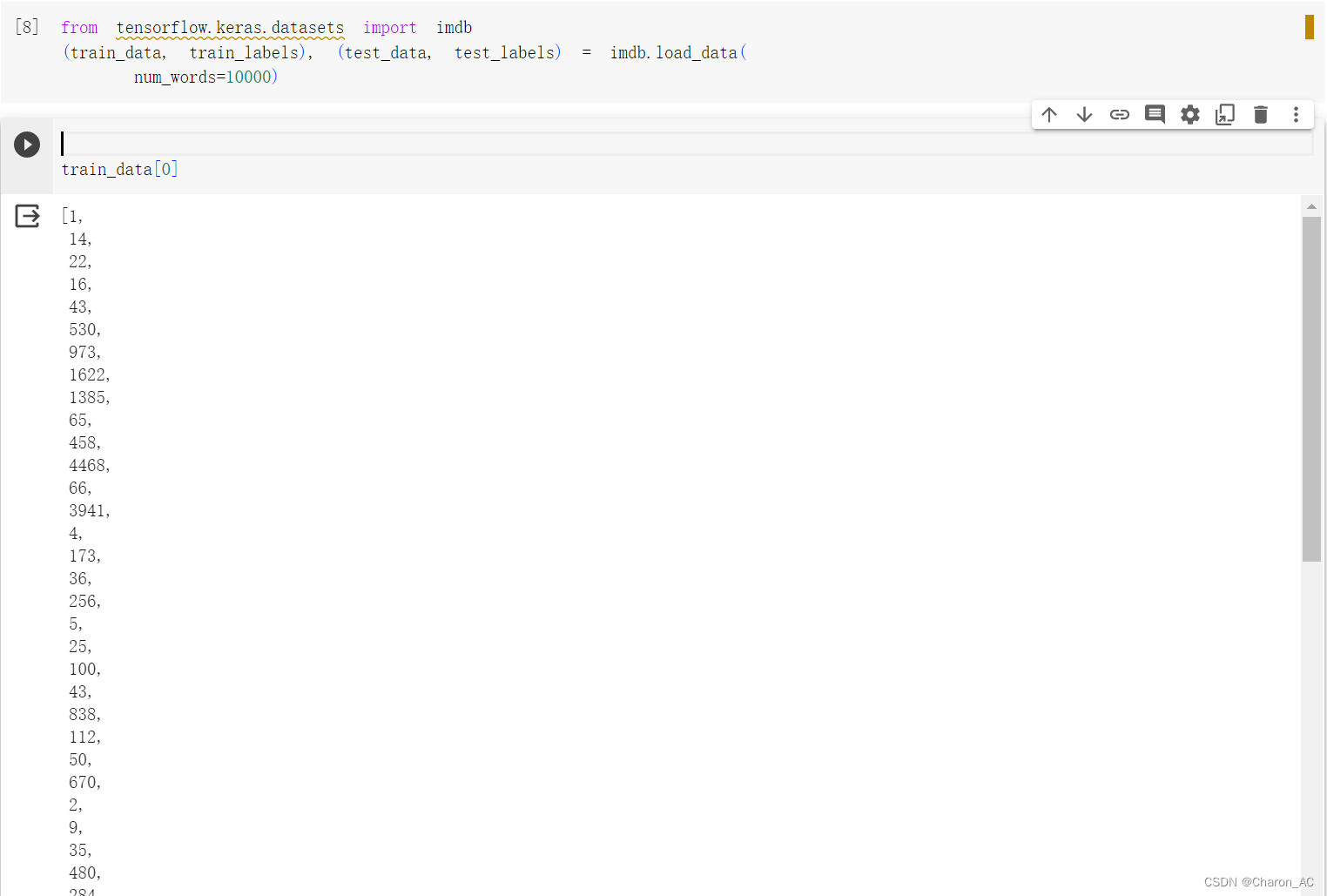
train_data[0]准备数据
运行结果部分截图如下,可以看到结果中有部分出现2,表示编号超过了10000,用2来代替
#小技巧:在colab看代码时 ,如果遇到不理解的函数或 代码块时,可以在代码前面加一个?,再运行,就可以显示出该函数的具体参数用法
?imdb.load_data代码运行部分如下
在上面我们将单词转化为了10000以内的数字,word_index是一种将单词映射到整数索引的字典。
那我们如何显示出对应数字的单词呢,我们可以将其进行字典反转,即将键和值进行互换,代码实现如下
word_index = imdb.get_word_index()
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
decoded_review = " ".join(
[reverse_word_index.get(i - 3, "?") for i in train_data[0]])在第一部分中,将字典存储
第二部分进行了字典反转
第三部分先定义一个空字符串,再将每个数字对应的单词放入这个字符串
可能会对.get(i-3,"?") 这有疑问 :
在刚开始编号时,其实是将排序都加了3的,因为0、1和2是“填充”、“序列的开始”和“未知”的保留索引。所以在转化时将其i-3 ,如果i-3的低于0,即对于 0,1,2三个数,在进行转化时就将其写为“?”
 上面则为转化后的实际文章,可以看到文章的开头和中间都有"?",此时我们就知道开头的问号代表文章的开头即原来的1, 后面的问号则是编号超过规定的数值的,此时无法寻找到则输出"?"
上面则为转化后的实际文章,可以看到文章的开头和中间都有"?",此时我们就知道开头的问号代表文章的开头即原来的1, 后面的问号则是编号超过规定的数值的,此时无法寻找到则输出"?"
这可以看到我们原来的字典实际是什么样子的
word_index["this"]
此行代码输出为11,但在实际编号的位置是14,所以可以看出多加了3,即0,1,2,占位
reverse_word_index[1]
此行代码输出为the,可以看出,the为使用最多的单词
在输入数据给神经网络时,不能将一个整数列表输入,必须将其列表转化为张量,转化方式有两种
1.垫你的列表,这样他们都有相同的长度,把它们变成一个整数张量的形状,然后使用作为网络的第一层层能够处理这样的整数张量(嵌入层,后面会详细讲解)
2.将它们转换为0和1的向量。这意味着,例如,将序列[3,5]变成一个10000维的向量,除了索引3,索引5,都是1。然后,您可以使用密集层作为网络的第一层,能够处理浮点向量数据。
接下来实际使用一下第二个方法
将整数序列编码成二进制矩阵
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
#创建一个全为0的矩阵 of shape (len(sequences), dimension)
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. #将结果的特定索引设置为1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#Vectorized training data
#Vectorized test dataenumerate() 是一个常用于Python中的内置函数,它用于遍历可迭代对象(如列表、元组、字符串等)的同时跟踪元素的索引。这可以方便地获取元素的值和它们在可迭代对象中的位置。enumerate 函数的常用语法如下:
enumerate(iterable, start=0)
iterable:要枚举的可迭代对象,如列表、元组、字符串等。
start:可选参数,表示索引的起始值,默认为0。
enumerate函数返回一个枚举对象,其中每个元素都是一个包含两个值的元组:索引和元素值。
矢量化标签
y_train = np.asarray(train_labels).astype('float32')y_test = np.asarray(test_labels).astype('float32')#将其转化为浮点类型也是为了之后计算更方便
建立网络
Dense(16, activation='relu').
要传递给每个密集层(16)的参数是该层的隐藏单位的数量。隐藏单元是图层的表示空间中的一个维度。
output = relu(dot(W, input) + b)
#有16个隐藏单位意味着权重矩阵W将有形状(input_dimension,16):与W的点积将把输入数据投影到一个16维的表示空间上(然后你将添加偏差向量b并应用relu操作)。
拥有更多的隐藏单元(高维表示空间)可以让你的网络学习更复杂的表示,但它使网络的计算更加昂贵,并可能导致学习不必要的模式(这些模式将提高训练数据的性能,但不会提高测试数据的性能)。
两个Dense的关键决策
1.要使用多少个图层
2. 要为每个图层选择多少个隐藏单元
relu:修正线性单元,是一个旨在使负值为零的函数
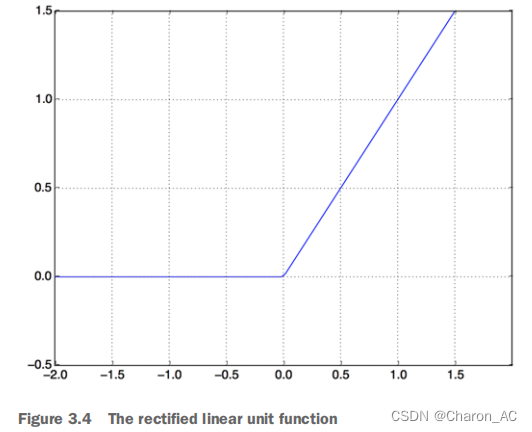
squashes:任意值到[0,1]区间(见图3.5),输出一些可以被解释为概率的东西。
该网络的外观
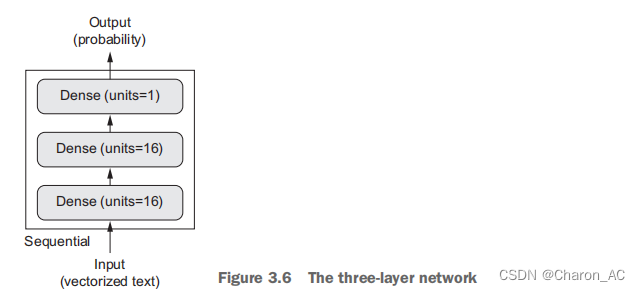
模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
"""什么是激活函数,为什么它们是必要的?没有一个激活函数像relu(也称为非线性)
,致密层将由两个线性操作,一个点积和添加:输出=点(W,输入)+b所以层只能学习
线性变换(仿射变换)的输入数据:假设空间将所有可能的线性转换的输入数据到一个
16维空间。这样的假设空间太有限,不会从多层表示中获益,因为线性层的深层堆栈
仍然会实现线性操作:添加更多的层不会扩展假设空间。为了获得一个更丰富的假设空
间,这将受益于深度表示,您需要一个非线性的,或激活函数。relu是深度学习中最流
行的激活函数,但还有许多其他的候选函数,它们都有类似的奇怪的名字: prelu,e
lu,等等"""选择一个损失函数和一个优化器
常见损失函数及适用范围
Binary Cross-Entropy (二元交叉熵,也称为对数损失,Log Loss):
- 适用范围:主要用于二元分类问题,其中目标是将输入数据分为两个类别。例如,垃圾邮件分类、图像中的物体检测等。
- 工作原理:二元交叉熵是一种用于测量两个概率分布之间的差异的损失函数。它对于二元分类问题非常有效,可以衡量模型的输出与真实标签之间的差异。
Mean Squared Error (均方误差):
- 适用范围:通常用于回归问题,其中目标是预测连续数值,如房价预测、股票价格预测、身高预测等。
- 工作原理:均方误差测量模型的预测值与真实值之间的平方差。它倾向于惩罚与真实值的差异较大的预测,因此对于回归问题非常有用。
Categorical Cross-Entropy (分类交叉熵):
- 适用范围:主要用于多类别分类问题,其中目标是将输入数据分为多个类别。例如,手写数字识别、自然语言处理中的情感分类等。
- 工作原理:分类交叉熵是一种用于测量模型输出与真实标签之间的差异的损失函数。它适用于多类别分类问题,并能够评估模型对每个类别的概率分布。
本次将使用rmsprop优化器和binary_crossentropy损失函数配置模型的步骤
编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])需要配置优化器的参数,或传递一个自定义损失函数或度量函数
配置优化程序
from keras import optimizersmodel.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['accuracy'])使用自定义损失和指标from keras import lossesfrom keras import metricsmodel.compile(optimizer=optimizers.RMSprop(lr=0.001),loss=losses.binary_crossentropy,metrics=[metrics.binary_accuracy])
验证结果
为了在训练结果中监控模型对其以前从未见过的数据的准确性,我们一般需要从原始数据中分离出一些样本来创建一个验证集,在这我们分离10000个样本创建
#留出验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]训练模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
"""对模型进行20个epoch的512个张量的训练(对x_train和y_train
张量中的所有样本进行20次迭代)"""调用model.fit()将返回一个历史记录对象。这个对象有一个成员历史记录,它是一个包含关于在训练期间发生的所有事情的数据的字典。
>>> history_dict = history.history>>> history_dict.keys()[u'acc', u'loss', u'val_acc', u'val_loss']
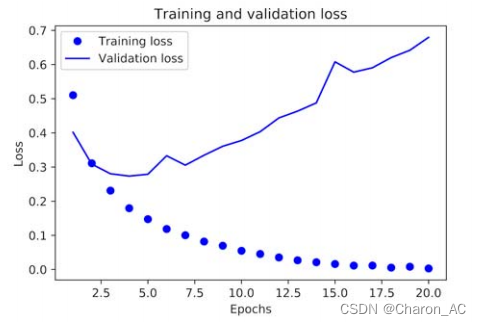
绘制训练和验证损失
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss') #“bo”是“蓝点”
plt.plot(epochs, val_loss_values, 'b', label='Validation loss') #“b”表示“实心蓝线”
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()结果如图
绘制训练和验证精度
plt.clf() #清除图形
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()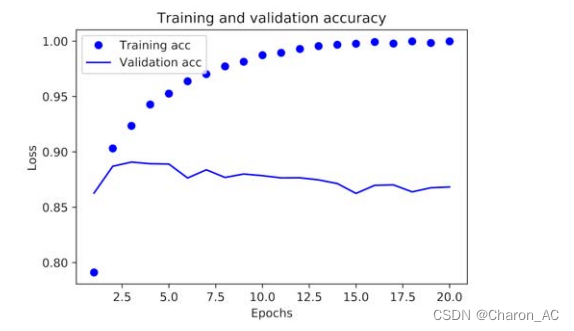
训练损失随每一个时代而减小,训练精度随每一个时代而增加。这是您在运行梯度下降优化时所期望的——每次迭代试图最小化的数量应该更少。但验证损失和准确性的情况并非如此:它们似乎在第四阶段达到顶峰。在训练数据上表现得更好的模型不一定是在以前从未见过的数据上做得更好的模型。准确地说,你所看到的是过拟合:在第二个阶段之后,你对训练数据进行了过优化,你最终学习了特定于训练数据的表示,而不会泛化到训练集之外的数据。在这种情况下,为了防止过拟合,您可以在三个时期后停止训练。一般来说,使用一系列的技术来减轻过拟合(第四章讲解)
从头开始重新培训一个模型
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)结果如下
>>> results[0.2929924130630493, 0.88327999999999995]损失值, 准确率
通过这种简单的方法我们达到了88%的准确率,用一些更高级的方法准确率能达到95%
使用一个训练有素的网络来对新数据进行预测
>>> model.predict(x_test)
array([[ 0.98006207]
[ 0.99758697]
[ 0.99975556]
...,
[ 0.82167041]
[ 0.02885115]
[ 0.65371346]], dtype=float32)
"""网络对某些样本(0.99或更多,或0.01或更少)有信心,但对其他样本(0.6,0.4)没有信心。"""总结
通常需要对原始数据进行大量的预处理,以便能够将其作为张量输入神经网络。单词序列可以被编码为二进制向量,但也有其他的编码选项。带有relu激活的
密集层堆栈可以解决广泛的问题(包括情绪分类),而且你可能会经常使用它们。
在一个二进制分类问题(两个输出类)中,你的网络应该以一个单元的密集层和一个s型激活结束:你的网络的输出应该是一个介于0到1之间的标量,编码一个概率。
在二进制分类问题上有这样的标量s型输出,您应该使用的损失函数binary_crossentropy。
rmsprop优化器通常是一个足够好的选择,无论你的问题。这是你少了一点要担心的一件事。
随着神经网络在训练数据上的改善,神经网络最终开始过拟合,最终在他们从未见过的数据上获得越来越糟糕的结果。确保始终监控训练集之外的数据的性能
分类新闻通讯社:一个多类分类的例子
路透社数据集
这是一组简短的新闻通讯社及其主题,由路透社于1986年发表。这是一个简单的,广泛使用的用于文本分类的玩具数据集。有46个不同的主题;有些主题比其他主题更有代表性,但每个主题在训练集中至少有10个例子。
加载路透社数据集
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(
num_words=10000)
"""num_words=10000将数据限制为数据中最常见的10,000个单词。你有8982个训练例子和
2246个测试例子"""解码新闻通讯社转回文本
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in
train_data[0]])准备数据
编码数据
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)建立网络
注意:输出类的数量已经从2个增加到了46个。输出空间的维数要大得多。在一直使用的密集层堆栈中,每个层只能访问前一层输出中的信息。如果其中一层删除了一些与分类问题有关的信息,这些信息永远无法被以后的层恢复:每一层都可能成为信息瓶颈。在前面的示例中,使用了16维的中间层,但是16维的空间可能过于有限,无法学习分离46个不同的类:这样小的层可能会成为信息瓶颈,永久地丢弃相关信息。
因此我们这个例子每层使用64个神经网络
模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))关于这个架构,需要注意另外两件事:
您将以大小为46的密集层结束网络。这意味着对于每个输入样本,网络将输出一个46维的向量。这个向量(每个维度)中的每个条目都将编码一个不同的输出类。
最后一层使用了一个softmax激活。您在MNIST示例中看到了这个模式。这意味着网络将在46个不同的输出类上输出一个概率分布——对于每个输入样本,网络将产生一个46维的输出向量,其中输出[i]是该样本属于第i类的概率。46分之和为1。
在这种情况下使用的最佳损失函数是categorical_crossentropy。它测量了两个概率分布之间的距离:这里,是网络输出的概率分布和标签的真实分布之间的距离。通过最小化这两个分布之间的距离,您可以训练网络输出一些尽可能接近真实标签的东西。
编译模型
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])验证方法
留出验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))损失和精度曲线
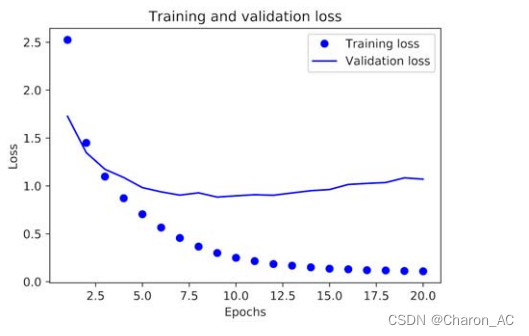
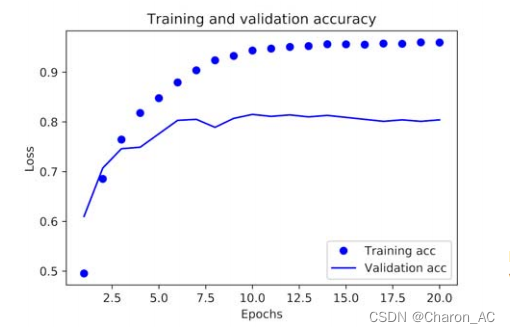
从头开始重新培训一个模型
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)>>> results[0.9565213431445807, 0.79697239536954589]
>>> import copy
>>> test_labels_copy = copy.copy(test_labels)
>>> np.random.shuffle(test_labels_copy)
>>> hits_array = np.array(test_labels) == np.array(test_labels_copy)
>>> float(np.sum(hits_array)) / len(test_labels)
0.18655387355298308对新数据生成预测
另一种处理标签和损失的不同方法
我们之前提到过,另一种编码标签的方法是将它们转换为一个整数张量,就像这样:
y_train = np.array(train_labels)
y_test = np.array(test_labels)这种方法唯一会改变的是损失函数的选择。清单3.21中使用的损失函数categorical_crossentropy期望标签遵循分类编码。对于整数标签,您应该使用稀疏的_类别的交叉熵
model.compile(optimizer='rmsprop',
loss='sparse_categorical_crossentropy',
metrics=['acc'])这个新的损失函数在数学上仍然与categorical_crossentropy相同;它只是有一个不同的接口。
拥有足够大的中间层的重要性
我们前面提到过,因为最终的输出是46维的,所以您应该避免使用许多少于46个隐藏单元的中间层。现在,让我们来看看,当您通过使用明显小于46维的中间层来引入信息瓶颈时,会发生什么:例如,4维的。
该网络现在的峰值是~为71%的验证精度,绝对下降了8%。这种下降主要是由于您试图将大量信息(足够的信息来恢复46个类的分离超平面)压缩到一个过低维的中间空间中。该网络能够将大部分必要的信息塞进这些八维表示中,但并不是全部。
总结
如果你试图分类N类之间的数据点,你的网络应该结束一个密集的层大小N.
在一个单标签,多类分类问题,你的网络应该结束softmax激活,这样它将输出一个概率分布在N输出类。
分类交叉熵几乎总是您应该用于处理此类问题的损失函数。它使网络输出的概率分布与目标的真实分布之间的距离最小化。
有两种方法来处理标签在多类分类:-编码标签通过分类编码(也称为一热编码)和使用categorical_crossentropy损失函数——编码标签为整数和使用sparse_categorical_crossentropy损失函数
如果你需要分类数据分成大量的类别,你应该避免创建信息瓶颈在你的网络由于中间层太小。
预测房价:一个回归的例子
前面的两个例子被认为是分类问题,其目标是预测一个输入数据点的单个离散标签。另一种常见的机器学习问题是回归,它包括预测一个连续的值,而不是一个离散的标签:例如,给定气象数据,预测明天的温度;或者预测一个软件项目需要完成的时间,给定它的规格。
注意:不要混淆回归和算法的逻辑回归。令人困惑的是,逻辑回归并不是一种回归算法,而是一种分类算法。
波士顿房价数据集
预测20世纪70年代中期波士顿郊区的房价中值,给出当时关于郊区的数据点,比如犯罪率,当地的财产税率,等等。您将使用的数据集与前面的两个示例有一个有趣的不同。它的数据点相对较少:只有506个,分为404个训练样本和102个测试样本。而输入数据中的每个特征(例如,犯罪率)都有不同的规模。例如,有些值是比例,取值在0到1之间;其他值在1到12之间,其他值在0到100之间,以此类推。
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) =
boston_housing.load_data()数据规模
>>> train_data.shape
(404, 13)
>>> test_data.shape
(102, 13)准备数据
输入一个具有完全不同范围的神经网络值是有问题的。该网络可能能够自动适应这种异构数据,但这肯定会让学习变得更加困难。一个广泛的最佳实践来处理这样的数据是做特征级规范化:对于每个特性的输入数据(输入数据矩阵中的一列),你减去功能的平均值和除以标准差,所以这个特性是集中在0和有一个单位标准差。这在Numpy中很容易做到
将数据规范化
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
"""规范化规模
mean = train_data.mean(axis=0): 这行代码计算训练数据集 train_data 中每个特征列的均值。
axis=0 表示对每列进行计算,即计算每个特征的均值。结果存储在名为 mean 的变量中。
train_data -= mean: 这行代码将训练数据集 train_data 中的每个特征列减去相应特征的均值。
这将使每个特征的均值变为零。
std = train_data.std(axis=0): 这行代码计算训练数据集 train_data 中每个特征列的标准差。
标准差度量了数据的离散程度,axis=0 表示对每列进行计算。结果存储在名为 std 的变量中。
train_data /= std: 这行代码将训练数据集 train_data 中的每个特征列除以相应特征的标准差。
这将使每个特征的标准差变为1,从而实现了规范化。
test_data -= mean 和 test_data /= std: 这两行代码对测试数据集 test_data 执行相同的
规范化操作,使用训练数据集中计算得到的均值和标准差。这是为了确保训练数据和测试数据都经过
相同的规范化处理,以便模型在测试数据上的表现能够与训练数据上的表现相一致。
规范化有助于提高机器学习模型的性能,因为它可以减少不同特征之间的尺度差异,防止某些特征对
模型的影响过大。这有助于模型更好地泛化到不同的数据集。"""
"""
请注意,用于归一化测试数据的数量是使用训练数据计算的。您不应该在工作流中使用根据测试数据
计算的数量,即使是像数据规范化这样简单的事情。
"""建立网络
因为可用的样本太少,所以您将使用一个非常小的网络,其中有两个隐藏层,每个层有64个单元。一般来说,你所拥有的训练数据越少,过拟合就会越差,而使用一个小的网络是缓解过拟合的一种方法
模型定义
from keras import models
from keras import layers
def build_model(): #因为需要多次实例化同一模型,所以需要使用函数来构造它。
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model该网络以一个单个单元结束,没有激活(它将是一个线性层)。这是标量回归(试图预测单个连续值的回归)。应用激活函数将限制输出可以采取的范围;例如,如果你在最后一层应用一个s型激活函数,网络只能学习预测0到1之间的值。在这里,因为最后一层是纯线性的,所以网络可以自由地学习预测任何范围内的值。
请注意,您可以使用mse损失函数来编译网络——均方误差,即预测和目标之间的差值的平方。这是一个广泛用于回归问题的损失函数。你还在训练期间监视一个新的指标:平均绝对误差(MAE)。它是预测和目标之间差的绝对值。例如,这个问题的MAE为0.5意味着你的预测平均相差500美元
使用k倍验证来验证您的方法
要在不断调整网络参数(例如用于训练的epoch的数量)时评估网络,您可以将数据分成训练集和验证集,就像您在前面的示例中所做的那样。但是因为您拥有的数据点太少,所以验证集最终会非常小(例如,大约有100个示例)。因此,验证分数可能会有很大的变化,这取决于您选择用于验证和训练:验证分数可能与验证分割有很大的差异。这将阻止您可靠地评估您的模型。在这种情况下,最佳的做法是使用k折叠交叉验证(见图3.11)。它包括将可用数据分割成K个分区(通常是K = 4或5),实例化K个相同的模型,并在评估剩余分区上对每个分区进行训练。那么所使用的模型的验证分数是所获得的K个验证分数的平均值。就代码而言,这一点很简单。
示意图如下
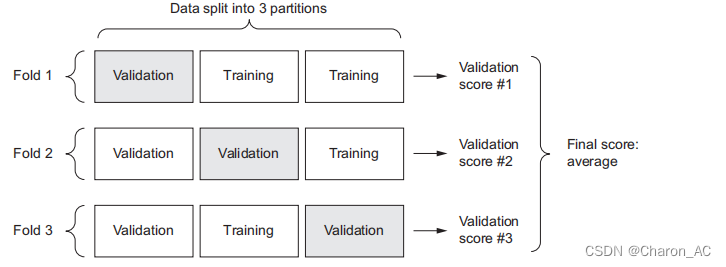
k倍验证
import numpy as np
k=4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
'''准备验证数据:来自分区的数据 #k'''
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate( '''准备训练数据:来自所有其他分区的数据'''
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model() #构建Keras模型(已编译)
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=1, verbose=0)
'''训练模型 (in silent mode, verbose = 0)'''
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
'''根据验证数据评估模型'''使用num_epochs = 100运行它将得到以下结果:
>>> all_scores[2.588258957792037, 3.1289568449719116, 3.1856116051248984, 3.0763342615401386]>>> np.mean(all_scores)2.9947904173572462
不同的运行确实显示了相当不同的验证分数,从2.6到3.2。平均值(3.0)是一个比任何单一分数更可靠的度量指标——这是k倍交叉验证的全部点。在这种情况下,你平均减少了3000美元,考虑到价格从1万美元到5万美元之间,这是很重要的。让我们试着再训练一点时间的网络: 500次。要记录模型在每个历元中的表现,您将修改训练循环以保存点戳的验证分数日志。
在每次折叠时保存验证日志
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
'''准备验证数据:来自分区的数据#k '''
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
'''准备训练数据:来自所有其他分区的数据'''
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()'''构建Keras模型(已编译)'''
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
'''训练模型 (in silent mode, verbose = 0)'''
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)建立连续的平均k倍验证分数的历史
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()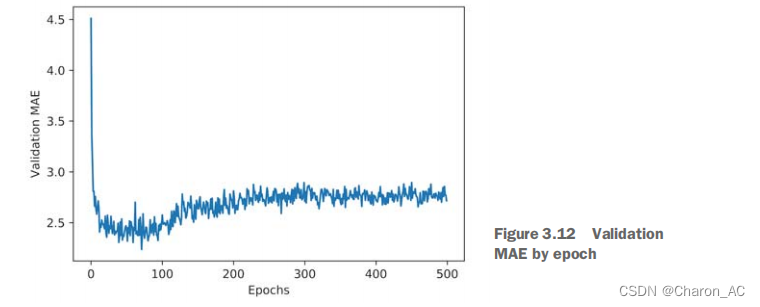
由于缩放问题和相对较高的方差,它可能有点难看到情节。让我们做以下操作:
省略前10个数据点,它们与曲线的其他部分的比例不同。
用前面各点的指数移动平均值代替每个点,得到一条平滑的曲线。
绘制验证分数,不包括前10个数据点
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show() 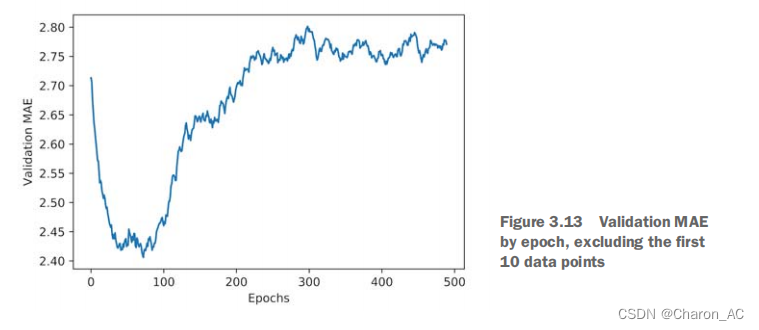
训练最终模式
model = build_model() '''获得一个新的、编译模型'''
model.fit(train_data, train_targets, '''对整个数据进行训练'''
epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)最终结果
>>> test_mae_score2.5532484335057877
总结
回归是使用不同的损失函数,而不是我们用于分类。均方误差(MSE)是一种常用于回归的损失函数。
类似地,用于回归的评价指标不同于用于分类的评价指标;自然,准确性的概念并不适用于回归。一个常见的回归度量是平均绝对误差(MAE)。
当输入数据中的特征具有不同范围内的值时,每个特征都应该作为预处理步骤进行独立缩放。当可用的数据很少时,使用K-fold验证是一种可靠地评估模型的好方法。
当可用的训练数据很少时,最好使用一个具有很少的隐藏层(通常只有一到两个)的小网络,以避免严重的过拟合。
K-fold 交叉验证(K-fold Cross-Validation)是一种用于评估机器学习模型性能的常用技术。它通过将数据集分成 K 个子集(或折叠),然后多次训练和测试模型,以便更全面地评估模型在不同数据子集上的表现。以下是 K-fold 交叉验证的基本工作原理:
数据集分割:首先,将原始数据集分成 K 个近似相等的子集。通常,这些子集是随机划分的,以确保样本的随机性。
K 次迭代:接下来,进行 K 次迭代,每次迭代使用 K-1 个子集来训练模型,然后使用剩下的一个子集来测试模型。这意味着每个子集都会被用作测试集一次,而其余子集用于训练。
性能度量:在每次迭代中,评估模型的性能指标,通常使用如准确性、均方误差、对数损失等指标,以确定模型在当前数据子集上的性能。
平均性能:计算 K 次迭代的平均性能指标,以得出模型的综合性能评估。这有助于减小因数据分布不均匀而引起的随机性误差。
K-fold 交叉验证的主要优点包括:
- 更全面的性能评估:K-fold 交叉验证可以更全面地评估模型的性能,因为它在不同子集上多次测试模型。
- 减少过拟合风险:它可以减少过拟合的风险,因为每个子集都会用于测试,从而模型不容易只适应于特定数据子集。
- 数据充分利用:它充分利用了可用的数据,因为每个数据点都被用于训练和测试。
K-fold 交叉验证在机器学习模型开发和调参中经常使用,以帮助选择合适的模型和超参数,同时对模型的性能进行客观评估。常见的 K 值为 5 和 10,但也可以根据问题的性质选择其他适当的 K 值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









