






将google drive 和 google colab相关联的代码
在原来的书上和网上的代码是
#原先的代码
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
这个代码看着很长并且在运行时在第二步验证时,我的谷歌账号就无法登录
所以我找了另一个代码
#实用且简单的将两个东西连接在一起
from google.colab import drive
drive.mount('/content/gdrive')
这个可以说的上短小精悍,非常有用
连接之后可以用下面代码查看是否连接成功
!ls /content/gdrive/MyDrive
在进行数据增强时,会出现报错说数据不够,我们就能用下面代码加上shuffle=True来进行打乱,用来保证每个epoch有足够的数据使用
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'path/to/train_data', # 请替换为实际路径
target_size=(150, 150),
batch_size=20,
class_mode='binary',
shuffle=True # 打乱数据,确保每个 epoch 都有不同的数据
)
history = model.fit(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50
)
降低 steps_per_epoch 的值: 尝试将 steps_per_epoch 设置为更小的值,确保不超过数据生成器提供的批次数。可以根据训练集中的样本数量和批次大小来动态计算。
# 获取训练集的样本数量
train_samples = len(train_generator.filenames)
# 设置 steps_per_epoch 为样本数量除以批次大小的结果
steps_per_epoch = train_samples // 32 # 假设批次大小为32optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
这行代码有一个问题就是现在版本的lr已经被learning_rate取代,所以我们在写代码时记得要更改
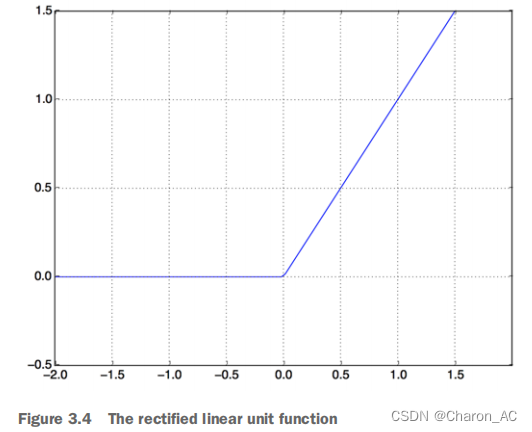
relu:修正线性单元,是一个旨在使负值为零的函数
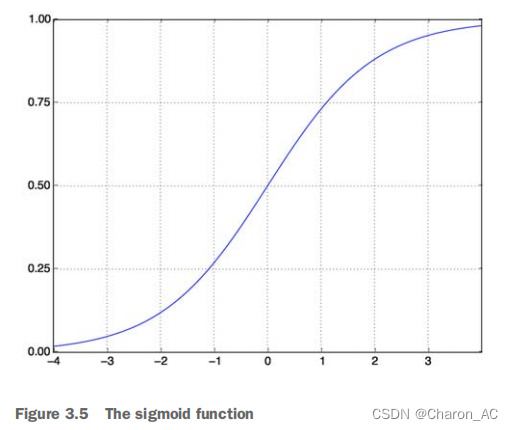
squashes:任意值到[0,1]区间(见图3.5),输出一些可以被解释为概率的东西。
常见损失函数及适用范围
Binary Cross-Entropy (二元交叉熵,也称为对数损失,Log Loss):
- 适用范围:主要用于二元分类问题,其中目标是将输入数据分为两个类别。例如,垃圾邮件分类、图像中的物体检测等。
- 工作原理:二元交叉熵是一种用于测量两个概率分布之间的差异的损失函数。它对于二元分类问题非常有效,可以衡量模型的输出与真实标签之间的差异。
Mean Squared Error (均方误差):
- 适用范围:通常用于回归问题,其中目标是预测连续数值,如房价预测、股票价格预测、身高预测等。
- 工作原理:均方误差测量模型的预测值与真实值之间的平方差。它倾向于惩罚与真实值的差异较大的预测,因此对于回归问题非常有用。
Categorical Cross-Entropy (分类交叉熵):
- 适用范围:主要用于多类别分类问题,其中目标是将输入数据分为多个类别。例如,手写数字识别、自然语言处理中的情感分类等。
- 工作原理:分类交叉熵是一种用于测量模型输出与真实标签之间的差异的损失函数。它适用于多类别分类问题,并能够评估模型对每个类别的概率分布。

在训练模型的框架更新后,并且版本不能兼容,所以需要重新对某些代码进行查找修改
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









