







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文

上表中,最后一列是parquet文件来源,表示字段对应的parquet文件。 这里使用了官方的3处parquet文件,数据预览、下载链接如下:
1. 初始Laion5B
- https://huggingface.co/datasets/laion/laion2B-en
- https://huggingface.co/datasets/laion/laion2B-multi
- https://huggingface.co/datasets/laion/laion1B-nolang
2. Joined: with punsafe and pwatermark
- https://huggingface.co/datasets/laion/laion2B-en-joined
- https://huggingface.co/datasets/laion/laion2B-multi-joined
- https://huggingface.co/datasets/laion/laion1B-nolang-joined
3. Laion-aesthetic
Laion aesthetic is a laion5B subset with aesthetic > 7 pwatermark < 0.8 punsafe < 0.5 See
- https://huggingface.co/datasets/laion/laion1B-nolang-aesthetic
- https://huggingface.co/datasets/laion/laion2B-en-aesthetic
- https://huggingface.co/datasets/laion/laion2B-multi-aesthetic
四、 处理流程及步骤
下面聊聊“宽表”的加工处理过程,有需求的同事可参考对官方的原始parquet进行处理。嫌麻烦的同学,可以交给opendatalab,在网站下载处理好的parquet文件。(https://opendatalab.com/LAION-5B)
因为parquet文件数据量较大,有几个TB,这里我们使用了大数据集群进行了分布式处理。
● 使用的技术栈有:
Spark/Hadooop/Hive/HDFS/Impala
● 集群硬件配置:
服务器3台,48core Cpu, 750GB Memory, 4TB Hard disk
● 数据处理过程和流程图如下:
数据输入:
-
下载官网parquet文件,并load到Hive表
-
解析下载的图片,判断图片类型,形成id, image_path, image_suffix的映射文件
数据处理:
- 读取Hive表数据,通过PySpark对Hive表的数据进行分布式join关联操作
数据输出:
- Hive结果表导出为parquet格式文件,并上传至OSS/Ceph存储

为了方便数据处理,这里对数据表进行简单的分层:
**- ODS层:**原始parquet文件load Hive后的结构化数据表,其中表2是对表1字段进行了裁减,表3是下载图片相关的信息。因为官方parquet文件只提供了下载url链接,我们并不知道图片类型和后缀,所以对下载的图片文件进行程序判定,识别出图片类型,对应image_suffix字段,image_path是图片的存储路径。
**- DMD层:**通过对表2、3、4进行join关联操作,生成中间表6
**- DMS层:**将中间表6与含有punsafe、pwatermark信息的表5进行关联,得到最后的结果表7
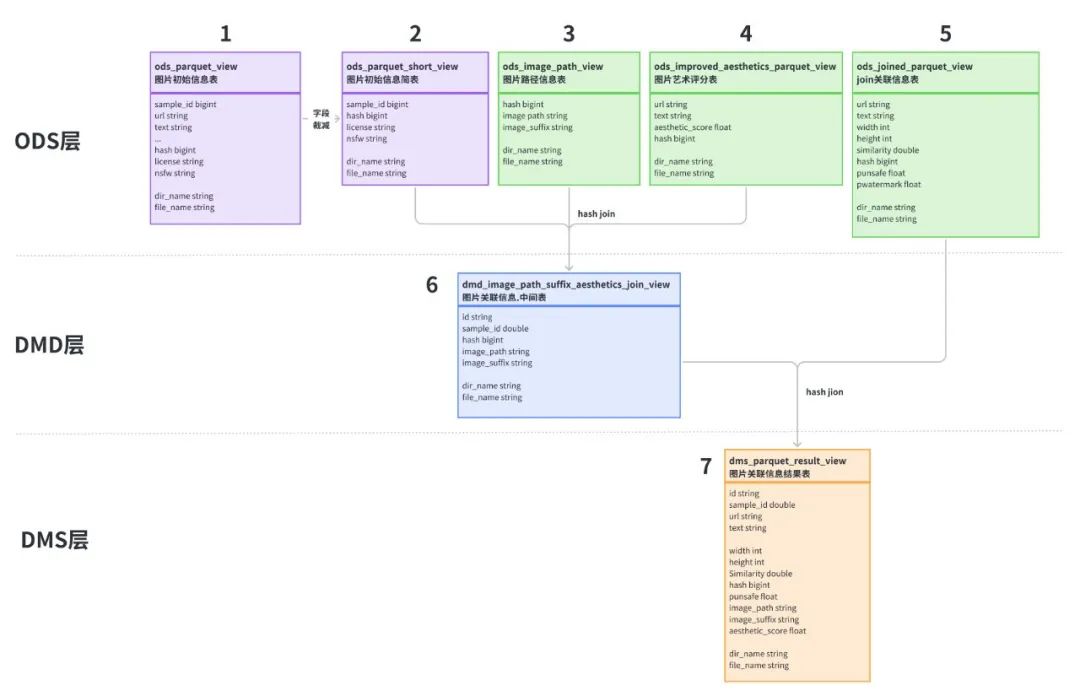
数据处理操作和代码示例如下:
4-1. Data load
主要操作是将parquet文件load到Hive表,load操作完成后,得到图中的1、3、4、5四张Hive表。
以初始parquet文件load为例,示例代码如下。
import os
from pyspark.sql import HiveContext, SQLContext
from pyspark.sql.functions import lit, input_file_name
from pyspark.sql.functions import col, udf
from pyspark.sql.types import StringType, LongType
import mmh3
sc = spark.sparkContext
sql_context = SQLContext(sc)
# 通过url/text计算hash值
def compute_hash(url, text):
if url is None:
url = ''
if text is None:
text = ''
total = (url + text).encode("utf-8")
return mmh3.hash64(total)[0]
# 注册spark udf
udf_compute_hash = udf(compute_hash, LongType())
# 提取input_file_name路径中的文件名称
def path_proc(file_path):
return str(file_path).split("/")[-1]
udf_path_proc = udf(path_proc)
# 因数据总量较大,这里按子集分批读取
parquet_path = "/nvme/datasets/laion5b/parquet/laion2B-en"
# parquet_path = "/nvme/datasets/laion5b/parquet/laion2B-multi"
# parquet_path = "/nvme/datasets/laion5b/parquet/laion2B-nolang"
# Hive一级分区名称
head_tail = os.path.split(parquet_path)
partition_name = head_tail[1]
parquet_df = spark.read.parquet(f"file://{parquet_path}/*.parquet")
parquet_df = parquet_df.withColumn("file_name", input_file_name())
parquet_df = parquet_df.withColumn("hash", udf_compute_hash(parquet_df["URL"], parquet_df["TEXT"]))
parquet_df = parquet_df.withColumn("dir_name", lit(f"{partition_name}"))
parquet_df = parquet_df.withColumn("file_name", udf_path_proc(parquet_df["file_name"]))
# 自定义视图名称,并注册视图
view_name = 'parquet_view'
parquet_df.createOrReplaceTempView(f"{view_name}")
# 数据写入Hive分区表,一级分区名称dir_name,二级分区名称file_name
sql_context.sql(f"insert overwrite table laion5b.parquet_view partition(dir_name='{partition_name}', file_name) select SAMPLE_ID,URL,TEXT,HEIGHT,WIDTH, LICENSE,NSFW,similarity,`hash`, file_name from {view_name}")
4-2. Data processing
数据处理过程主要包括数据表裁减、hash join操作。
因为表1的数据量较大,存在字段冗余,这里对表1的部分字段进行裁减得到表2。 表2、3、4的join代码如下,先将图片的sample_id、licenese、nsfw、image_suffix、aesthetic_score字段,按hash值进行关联,合并成一张表。 因为需要使用file_name作为Hive表二级动态分区,也避免大量数据join导致OOM,这里按dir_name分别进行join操作,不同的分区修改对应的dir_name即可。
join_sql = """
insert overwrite table laion5b.dmd_image_path_suffix_aesthetics_join_view PARTITION (dir_name = 'laion2B-en', file_name)
select A.sample_id,
A.`hash`,
B.image_path,
B.image_suffix,
A.license,
A.nsfw,
C.aesthetic_score,
A.file_name
from laion5b.ods_parquet_short_view A
left join laion5b.ods_image_path_view B on A.`hash` = B.`hash`
and B.dir_name = 'laion2B-en'
left join laion5b.ods_improved_aesthetics_parquet_view C on A.`hash` = C.`hash`
where A.dir_name = 'laion2B-en'
"""
join_df = sqlContext.sql(join_sql)
表5与表6通过hash字段进行join,得到result结果表7。
sc = spark.sparkContext
sqlContext = SQLContext(sc)
join_sql = """
insert overwrite table laion5b.dms_parquet_result_view PARTITION (dir_name = 'laion2B-en', file_name)
select B.id, B.sample_id, A.url, A.text, A.width, A.height,
A.similarity, A.`hash`, A.punsafe, A.pwatermark,
if(B.image_suffix is null or B.image_suffix = 'jpg', B.image_path,
regexp_replace(B.image_path, right(B.image_path, 3), B.image_suffix)) as image_path,
B.image_suffix, B.LICENSE, B.NSFW, B.aesthetic_score, A.language, B.file_name
from laion5b.ods_joined_parquet_view A
left join (
select id, sample_id, image_path, image_suffix, LICENSE,
NSFW, aesthetic_score, `hash`, dir_name, file_name,
ROW_NUMBER() OVER (PARTITION BY `hash` order by `hash`) as rn
from laion5b.dmd_image_path_suffix_aesthetics_join_view
where dir_name = 'laion2B-en'
) B on A.dir_name = B.dir_name
and A.`hash` = B.`hash`
and B.rn = 1
where A.dir_name = 'laion2B-en'
"""
join_df = sqlContext.sql(join_sql)
4-3.Data write
最后将Hive结果表导出为snappy压缩格式的parquet文件,再上传到对象存储就可以使用了。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-ShiMC4Lt-1713386929736)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1266
1266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









