







定义:聚类分析(Cluster analysis)又叫做群集分析,通过一些属性将对象或变量分成不同的组别,在同一类下的对象或变量在这些属性上具有一些相似的特点。
无监督学习,相对来说无规划的
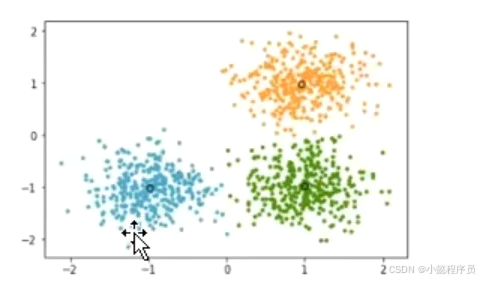
一、事件分类说明
- Q型聚类:对个案(样品、对象、被试)进行分类。
如下列对行进行分类,分不同的车型

- R型聚类:对变量进行分类。
如下列对列进行分类,哪几列可以看成是共同的特征(影响因素)合在一起
 二、聚类的分类
二、聚类的分类
SPSS聚类分类(简单到高级)
- 快速聚类(k-均值聚类):最简单的聚类方法,只能对连续数据进行聚类,只能对样品进行聚类,适合大样本聚类,缺点不能自动确定类别数量。有时也称快速聚类
- 系统聚类:可以对个案、变量进行聚类,可以对连续变量或分类变量进行聚类,适合样本容量较小的情况,缺点不能自动确定类别数量。
- 二阶聚类:最智能的聚类方法,可以对个案进行聚类,可以对连续变量+分类变量进行聚类,适合大样本聚类,能自动确定类别数量。
(一)快速聚类(k-均值聚类)
(全局最优,不会局部最优)一个族群到了另外一个可以再到另外一个,不会固定
原理讲解
分割法中的一种
思想:使得族群内的方差和最小
给定k然后进行分割
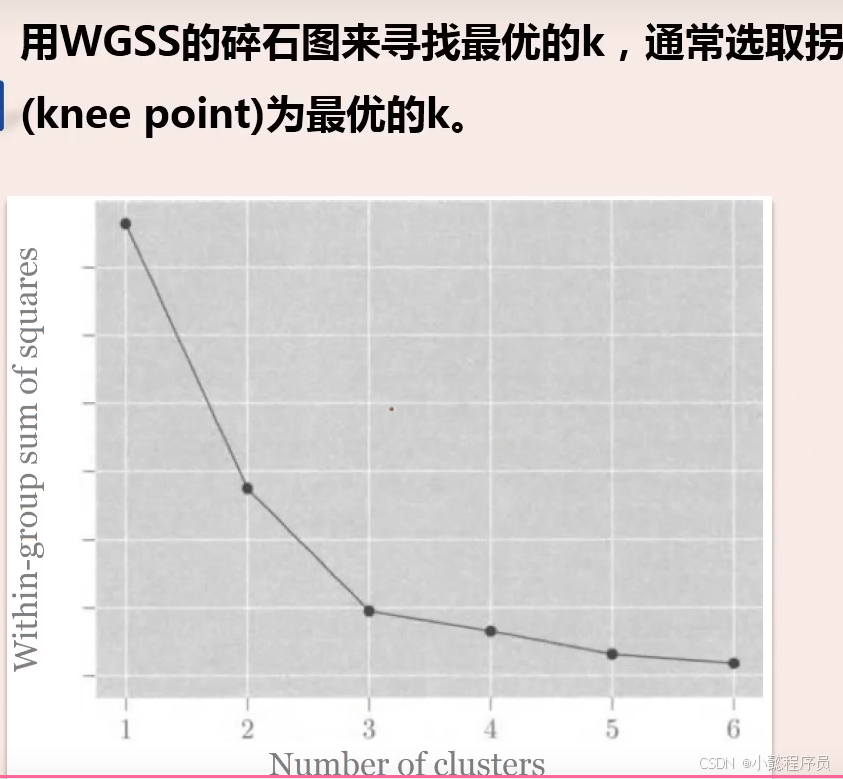
 k值选取
k值选取
 (1)操作要点
(1)操作要点
首先把数据标准化。
聚类数:根据计算结果来定。
迭代数:可以改大一些。
保存:“聚类成员和”与“聚类中心的距离
选项:“ANOVA”和“每个个案聚类信息
(2)结果解读
①读最终聚类中心能够反映分出来的这两类的特点,可以自己起名字。
②ANOVA显示两个或者多个类别的群体在聚类的各个变量上是否有差异,有差异说明聚类相对成功。
③个案数显示两个或者多个类别的群体各有多少个被试。最好比较均匀,不要有类别太少。
(3)三线表的制作
(二)系统聚类
又称层次聚类
1.原理讲解
1.1怎么进行分类:
凝聚法:由单个个体开始,逐步合并最“相似”的个体,直到所有个体都合并为一个族群。该方法为我们主要讨论的方法。(其实是给出路径的过程)
分离法:是凝聚法的一个相反的方向
1.2系统树图(谱系图)
表示路径,数据表示在哪个距离哪几个进行合并的。以及某两个族群的距离多少
在距离差大的地方分割合适(图中的横线最长的部分)借鉴
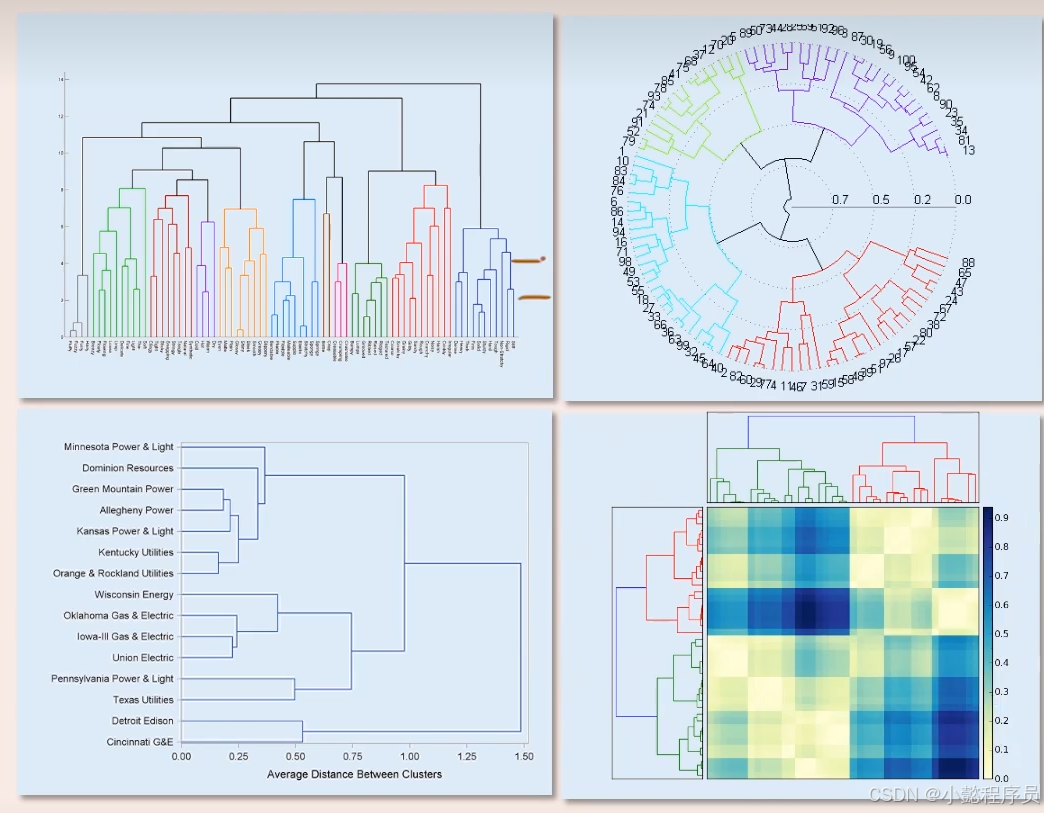 1.3聚类思想(不同的结果可能不太一样)
1.3聚类思想(不同的结果可能不太一样)
1.连接法
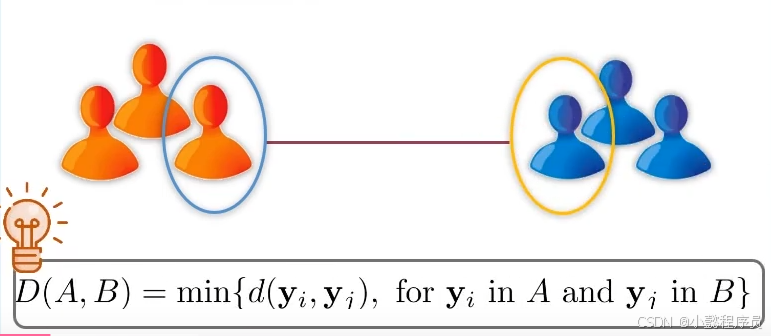
 ①简单连接/最近邻法
①简单连接/最近邻法
定义族群间的距离为两族群中相隔最近的两个体间的距离。(利用距离矩阵,不断更新)
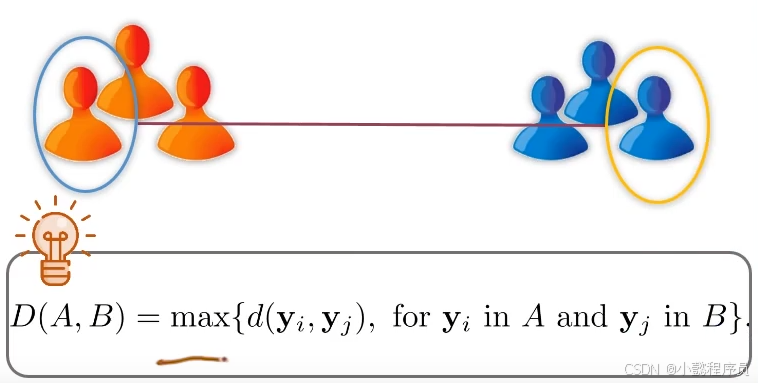
 ②完全连接法/最远邻近法
②完全连接法/最远邻近法
以两组别中最远个体之间的距离来定义族群之间的距离。(利用距离矩阵,不断更新)
③平均连接法
两族群之间的距离定义为几A个A集合点和几B个B集合点产生的所有 nA和nB个距离数值的平均值。(同质心连接法相反:先求距离再求平均)
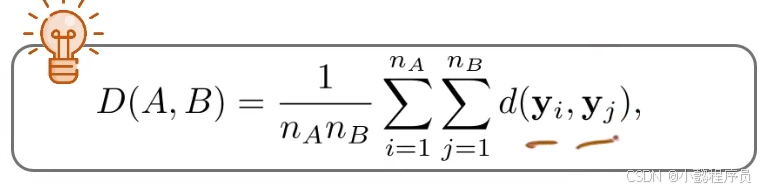
④质心法
两族群的距离定义为两族群各自的质心(Centroid )即样本均值向量,之间的欧式距离。(同平均连接法相反:先求平均再求距离)
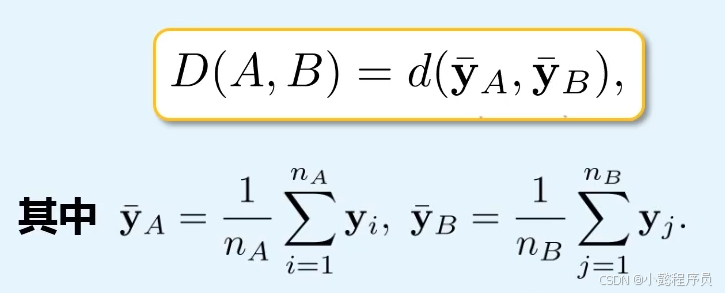
缺点:
 改进
改进

2.word法
Ward法(Ward's method)/方差平方和增量法(Incremental sum of squares )由合并前后的族群内方差平方和的差异定义距离。
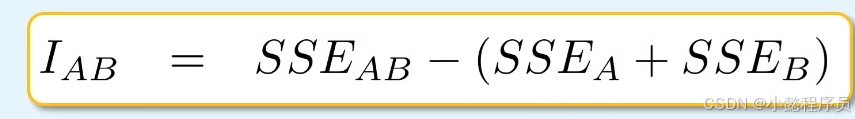
缺点:
一旦个体被分入一个族群,它将不可再被归入另一个族群(局部最优,不会全局最优)
- 一般三四十个刚好
- 会自己进行标准化
(1)操作要点
绘制:树状图(谱系图)
方法:“聚类方法”用“组间连接”。
“度量标准"根据数据类型选定:Q型聚类选“平方欧氏距离”,
R型聚类用“Pearson相关”
"标准化" 选定“Z得分.
分群:根据聚类类型选定。
(2)结果解读
画聚合系数随分类数变化图:以聚合系数为纵坐标,类别为横坐标,开始是N-1类。聚合系数图从哪里开始平缓就取那里的分类数。
(3)图表的制作
三、二阶聚类
(1)操作要点
分类变量和连续变量按要求填入。
距离测量:全连续变量选“欧氏”,否则选“对数似然
聚类数目:“自动确定”
输出:“透视表”、“创建聚类成员变量”
(2)结果解读
(3)图表的制作
四、总结
SPSS聚类分析的方法
(1)快速聚类(k-均值聚类):最简单的聚类方法,只能对连续数据进行聚类,只能对样品进行聚类,适合大样本聚类,不能自动确定类别数量。
(2)系统聚类:可以对个案、变量进行聚类可以对连续变量或分类变量进行聚类,适合样本容量较小的情况,不能自动确定类别数量。
(3)二阶聚类:最智能的聚类方法,可以对个案进行聚类,可以对连续变量+分类变量进行聚类,适合大样本聚类,能自动确定类别数量。

















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









