






一、准备数据:
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成自定义数据集
np.random.seed(0)
data1 = np.random.normal(0, 1, 100)
data2 = np.random.normal(2, 1.5, 100)
data = np.concatenate([data1, data2])
df = pd.DataFrame(data, columns=['数据'])二、直方图
特点
-
数据分组:将数据分成若干个区间(称为“桶”或“bin”),统计每个区间内数据的频数或频率。
-
直观展示分布:通过柱状图的形式直观地展示数据的分布情况,包括集中趋势、分散程度和偏态等。
-
易于理解:是最常见的分布可视化方式之一,容易被大多数人理解。
应用场景
-
用于展示单变量数据的分布情况,例如学生的考试成绩分布、商品的价格分布等。
-
可以帮助识别数据中的异常值或离群点。
使用Python实现
# 绘制直方图
plt.figure(figsize=(10, 6))
plt.hist(df['数据'], bins=30, color='skyblue', edgecolor='black')
plt.title('直方图')
plt.xlabel('数据值')
plt.ylabel('频率')
plt.show()实验结果:
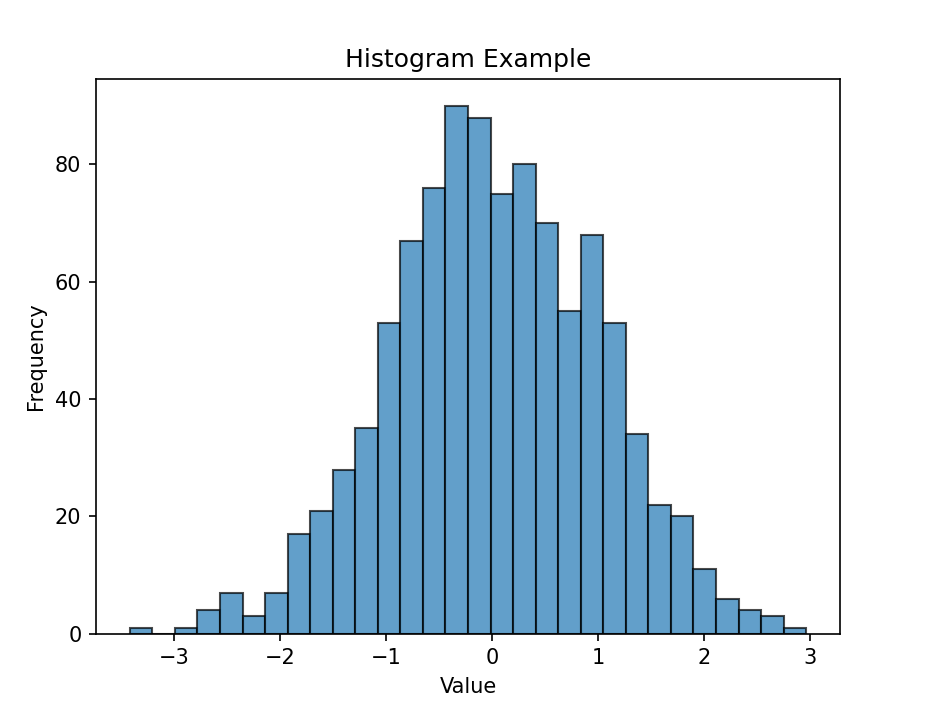
三、密度图
特点
-
平滑曲线:通过核密度估计(KDE)将数据的分布转化为一条平滑的曲线,避免了直方图中由于分组而产生的不连续性。
-
更精确地展示分布形状:能够更精确地反映数据的分布形状,包括多峰分布等复杂情况。
-
美观:曲线形式更加美观,适合用于展示连续数据的分布。
应用场景
-
用于展示连续变量的分布情况,尤其是当数据量较大时,密度图可以更清晰地展示分布的细节。
-
适合用于比较多个变量的分布形状。
使用Python实现
# 绘制密度图
plt.figure(figsize=(10, 6))
sns.kdeplot(df['数据'], bw_adjust=0.5, color='red')
plt.title('密度图')
plt.xlabel('数据值')
plt.ylabel('密度')
plt.show()结果展示:
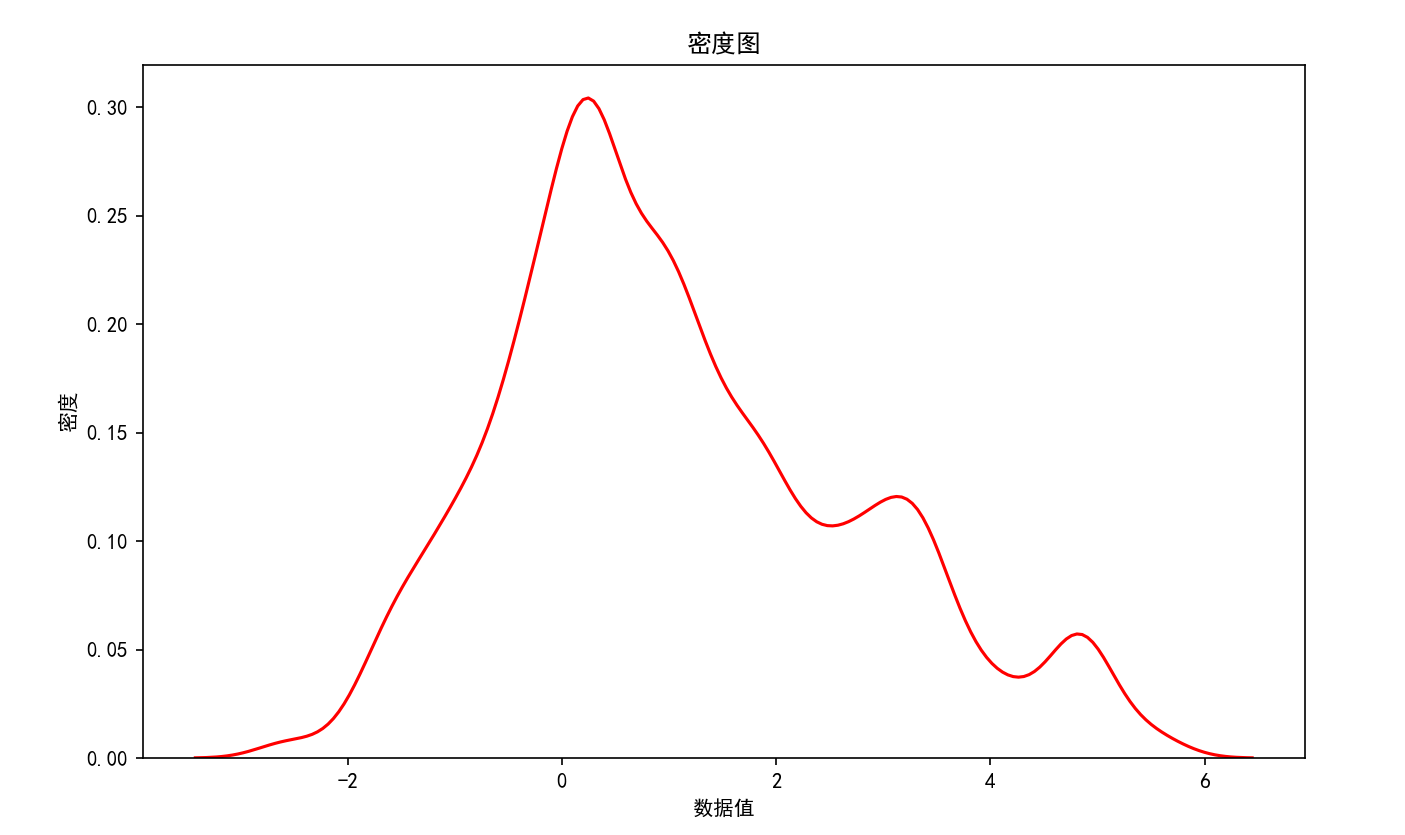
结果描述:生成一条平滑的曲线,表示数据的密度分布。曲线的高度表示数据在该位置的密度,通过密度图可以更清晰地看到数据的分布形状,例如是否存在双峰分布等。
四、箱线图
特点
-
五数概括:通过箱体和须线展示数据的五数概括(最小值、第一四分位数、中位数、第三四分位数和最大值)。
-
直观展示数据分布:能够直观地展示数据的集中趋势、分散程度和异常值。
-
适用于比较多个数据集:可以同时展示多个数据集的箱线图,方便比较它们的分布差异。
应用场景
-
用于展示单变量数据的分布情况,尤其是当需要同时比较多个数据集时。
-
用于识别数据中的异常值。
使用Python实现
# 绘制箱线图
plt.boxplot(data)
plt.title('Boxplot Example')
plt.ylabel('Value')
plt.show()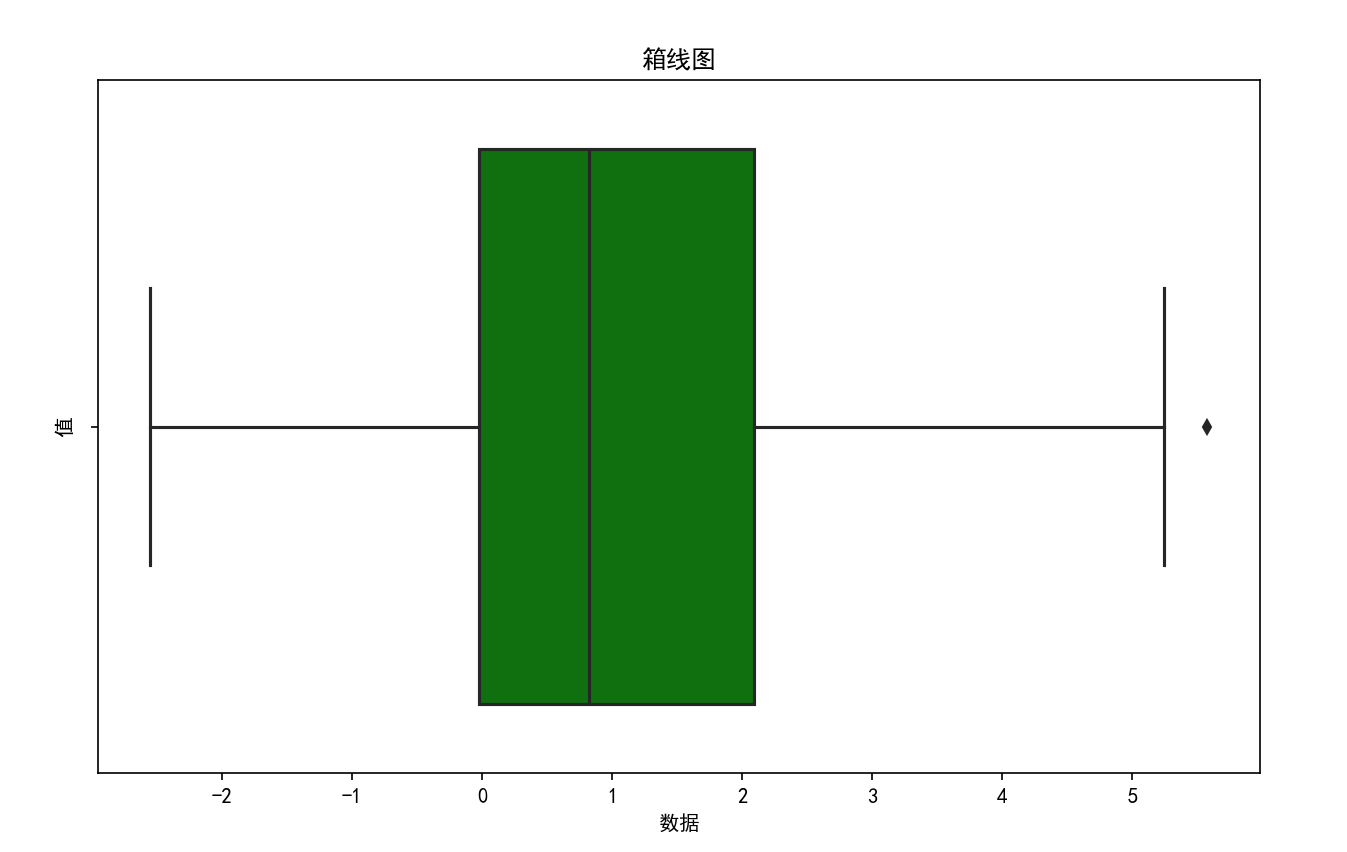
结果描述:生成一个箱线图,箱体表示数据的中间50%范围(从第一四分位数到第三四分位数),中位数用一条线表示,须线表示数据的范围(通常是1.5倍四分位距之外的值被认为是异常值)。通过箱线图可以直观地看到数据的集中趋势、分散程度和异常值。
四、小提琴图
特点
-
结合箱线图和密度图:在箱线图的基础上,两侧添加了密度图的形状,既能展示数据的五数概括,又能展示数据的分布形状。
-
更丰富的信息展示:比箱线图提供了更多的信息,能够更直观地反映数据的分布情况。
-
美观且信息量大:是一种美观且信息量丰富的可视化方式。
应用场景
-
用于展示单变量数据的分布情况,尤其是当需要同时展示数据的五数概括和分布形状时。
-
适合用于比较多个变量的分布情况。
使用Python实现
# 绘制小提琴图
plt.figure(figsize=(10, 6))
sns.violinplot(x=df['数据'], color='purple')
plt.title('小提琴图')
plt.xlabel('数据')
plt.ylabel('值')
plt.show()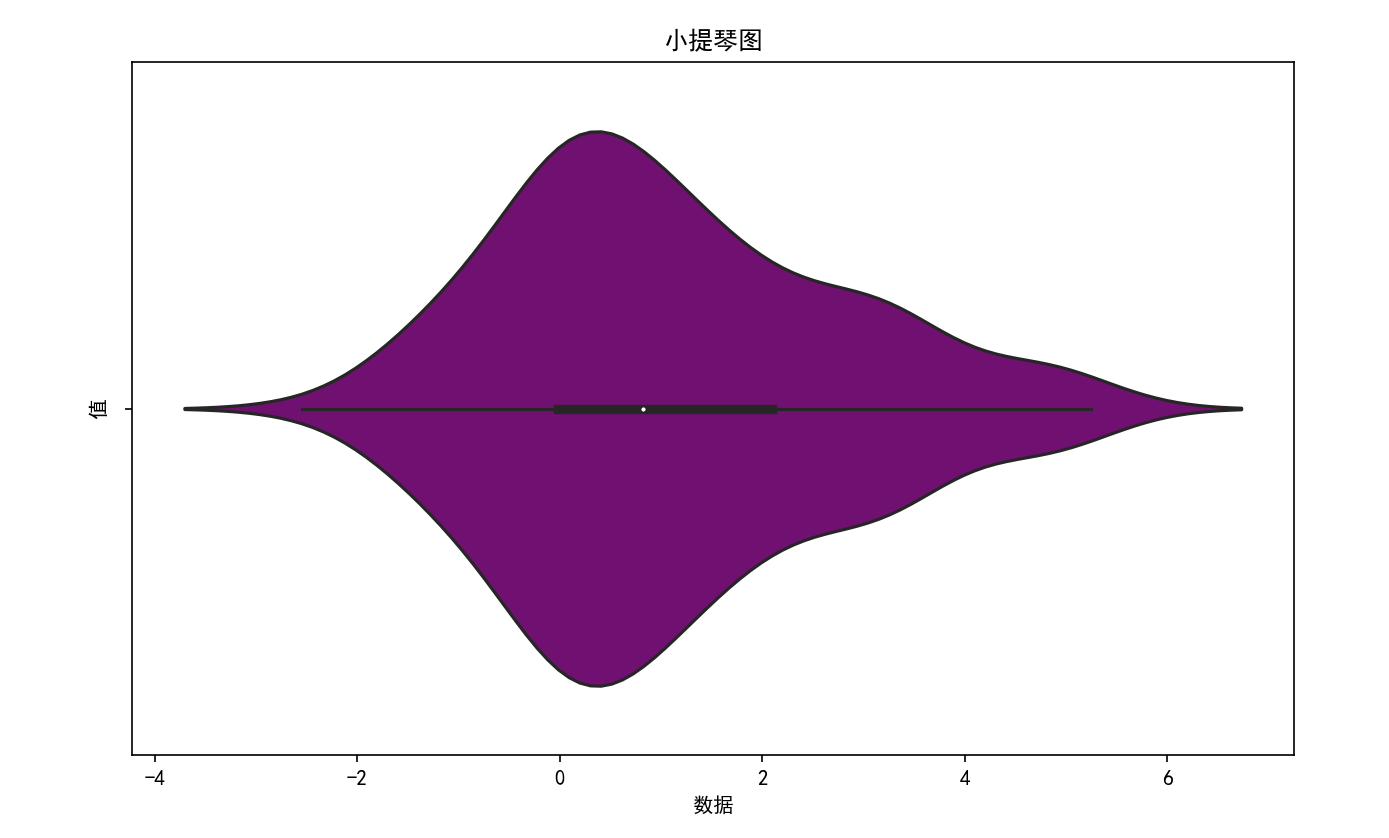
结果描述:生成一个小提琴图,中间部分是箱线图,两侧是密度图的形状。通过小提琴图可以同时看到数据的五数概括和分布形状,例如数据是否对称、是否存在多峰分布等。

















 8998
8998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









