






实验目的
1.掌握关系数据在大数据中的应用
2.掌握关系数据可视化方法
3. python 程序实现图表
实验原理
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠或者是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?
就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集程度,是数据分布范围的描述,与茎叶图类似,但是不会具体到某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点
图将序列显示为一组点。值由点在图表中的位置表示。散点图通常用于比较跨类别的聚合数据
实验环境
12th Gen Intel® Core™ i7-12700H 2.30 GHz
PyCharm Community Edition 2023.2.1
实验步骤
1、 数据源

2、安装Python所需要的第三方模块
Seaborn 是基于 Python 的一个数据可视化库,它建立在 Matplotlib 之上,并且与 Pandas 的数据结构紧密结合,为统计图形绘制提供了一个高级的接口,能让你轻松地创建各种具有吸引力的统计图表。下面从几个方面详细介绍 Seaborn 库:
pip install seaborn

3、实验
1、联合图
将散点图、回归直线以及边缘直方图结合在一起,能够直观地展示两个变量之间的关系,同时呈现每个变量自身的分布情况。
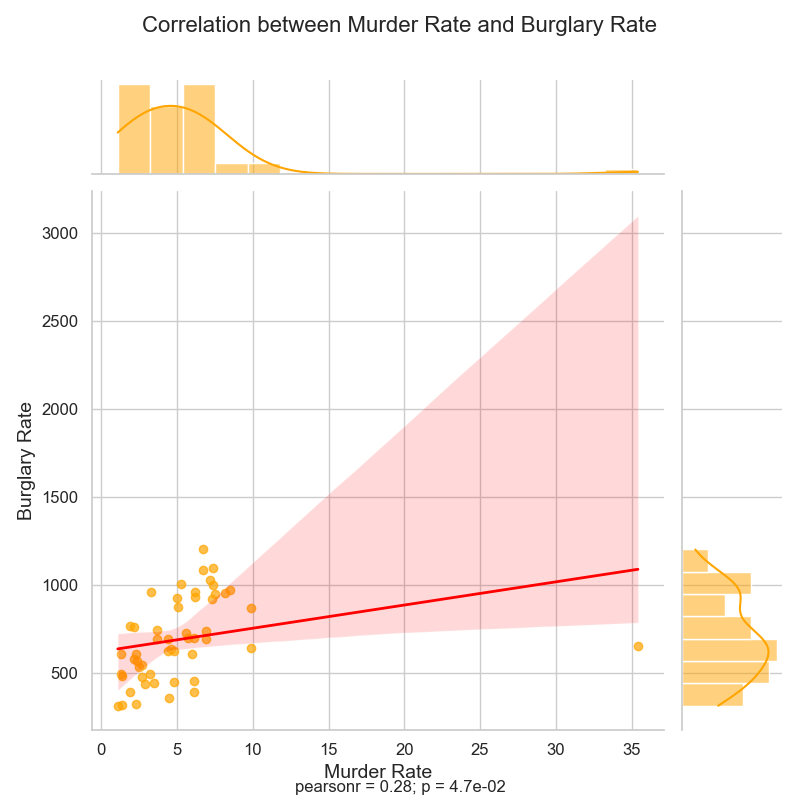
代码如下
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import pearsonr
import os
try:
# 设置画图风格
sns.set(style="whitegrid") # 使用whitegrid风格,增加网格线便于观察
# 检查文件是否存在
if not os.path.exists("E:\\桌面\\crimeRatesByState2005.csv"):
raise FileNotFoundError("数据文件不存在,请检查文件路径。")
# 读取数据
df = pd.read_csv("E:\\桌面\\crimeRatesByState2005.csv")
# 打印数据的基本描述性统计信息
print("数据的基本描述性统计信息:")
print(df[['murder', 'burglary']].describe())
# 计算谋杀率和入室盗窃率之间的皮尔逊相关系数
corr, p_value = pearsonr(df['murder'], df['burglary'])
# 创建联合图 (joint plot)
g = sns.jointplot(
x='murder',
y='burglary',
data=df,
kind='reg', # 添加回归线
color='orange', # 更改为橙色
height=8, # 调整图形大小
ratio=5, # 调整主图与边缘直方图的比例
space=0.1, # 调整主图与边缘直方图之间的间距
scatter_kws={'alpha': 0.7}, # 设置散点的透明度
line_kws={'color': 'red', 'lw': 2} # 设置回归线的颜色和线宽
)
# 设置轴标签和字体大小
g.ax_joint.set_xlabel('Murder Rate', fontsize=14)
g.ax_joint.set_ylabel('Burglary Rate', fontsize=14)
# 设置轴刻度标签的字体大小
g.ax_joint.tick_params(axis='both', which='major', labelsize=12)
g.ax_marg_x.tick_params(axis='x', which='major', labelsize=12)
g.ax_marg_y.tick_params(axis='y', which='major', labelsize=12)
# 添加相关系数和p值信息
plt.figtext(0.5, 0.01, f'pearsonr = {corr:.2f}; p = {p_value:.1e}',
ha='center', fontsize=12)
# 设置图形标题
plt.suptitle('Correlation between Murder Rate and Burglary Rate', fontsize=16)
# 调整布局
plt.tight_layout()
plt.subplots_adjust(top=0.9)
# 显示图形
plt.show()
# 如果需要保存图像
# plt.savefig('murder_burglary_correlation.png', dpi=300, bbox_inches='tight')
except FileNotFoundError as e:
print(f"错误: {e}")
except Exception as e:
print(f"发生未知错误: {e}")
2、动态散点图
为了分析犯罪数据中谋杀率和入室盗窃率之间的相关性,通过pyecharts库创建一个动态散点图来直观展示两者的关系。
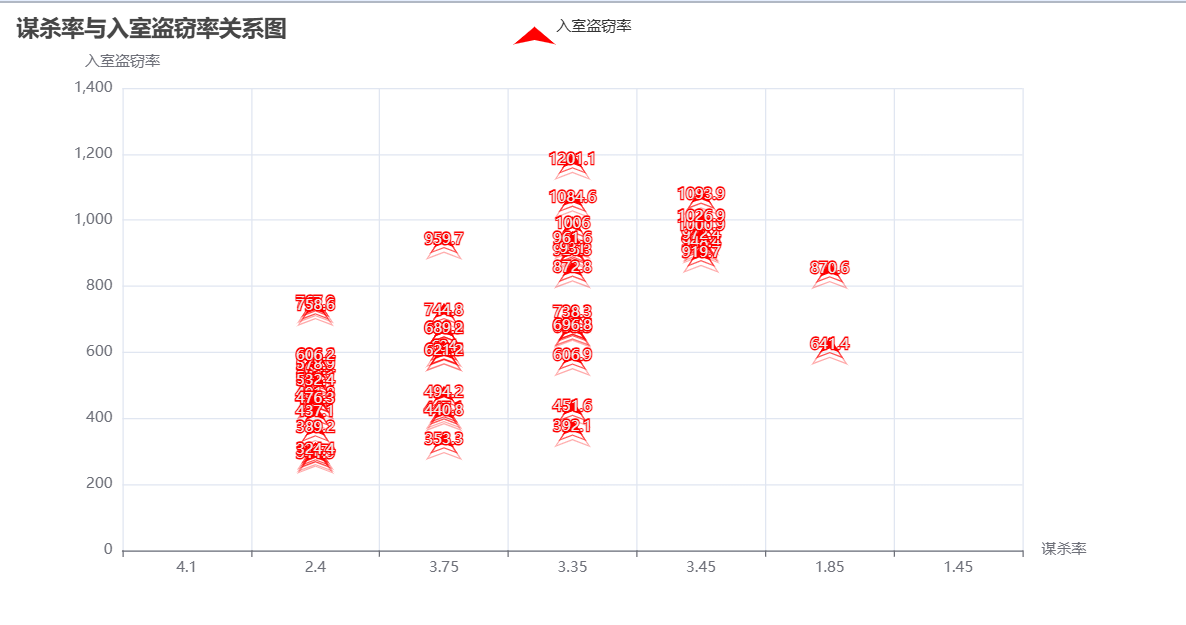
代码如下
import numpy as np
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import EffectScatter
# 加载CSV数据
crime = pd.read_csv("E:\\桌面\\crimeRatesByState2005.csv")
# 使用NumPy筛选数据
condition = np.logical_and(crime.state != 'United States', crime.state != 'District of Columbia')
crime2 = crime[condition]
# 计算相关系数
correlation = np.corrcoef(crime2['murder'], crime2['burglary'])[0, 1]
print(f"谋杀率与入室盗窃率的相关系数:{correlation:.4f}")
# 创建动态散点图
es = (
EffectScatter()
.add_xaxis(crime2['murder'].tolist())
.add_yaxis(
series_name="入室盗窃率",
y_axis=crime2['burglary'].tolist(),
symbol="arrow",
symbol_size=10,
itemstyle_opts=opts.ItemStyleOpts(color="red") # 设置散点颜色为红色
)
.set_global_opts(
title_opts=opts.TitleOpts(title="谋杀率与入室盗窃率关系图"),
xaxis_opts=opts.AxisOpts(name="谋杀率"),
yaxis_opts=opts.AxisOpts(name="入室盗窃率"),
)
)
# 渲染图表到HTML文件
es.render("crime_rates_effect_scatter.html")
3、散点图矩阵
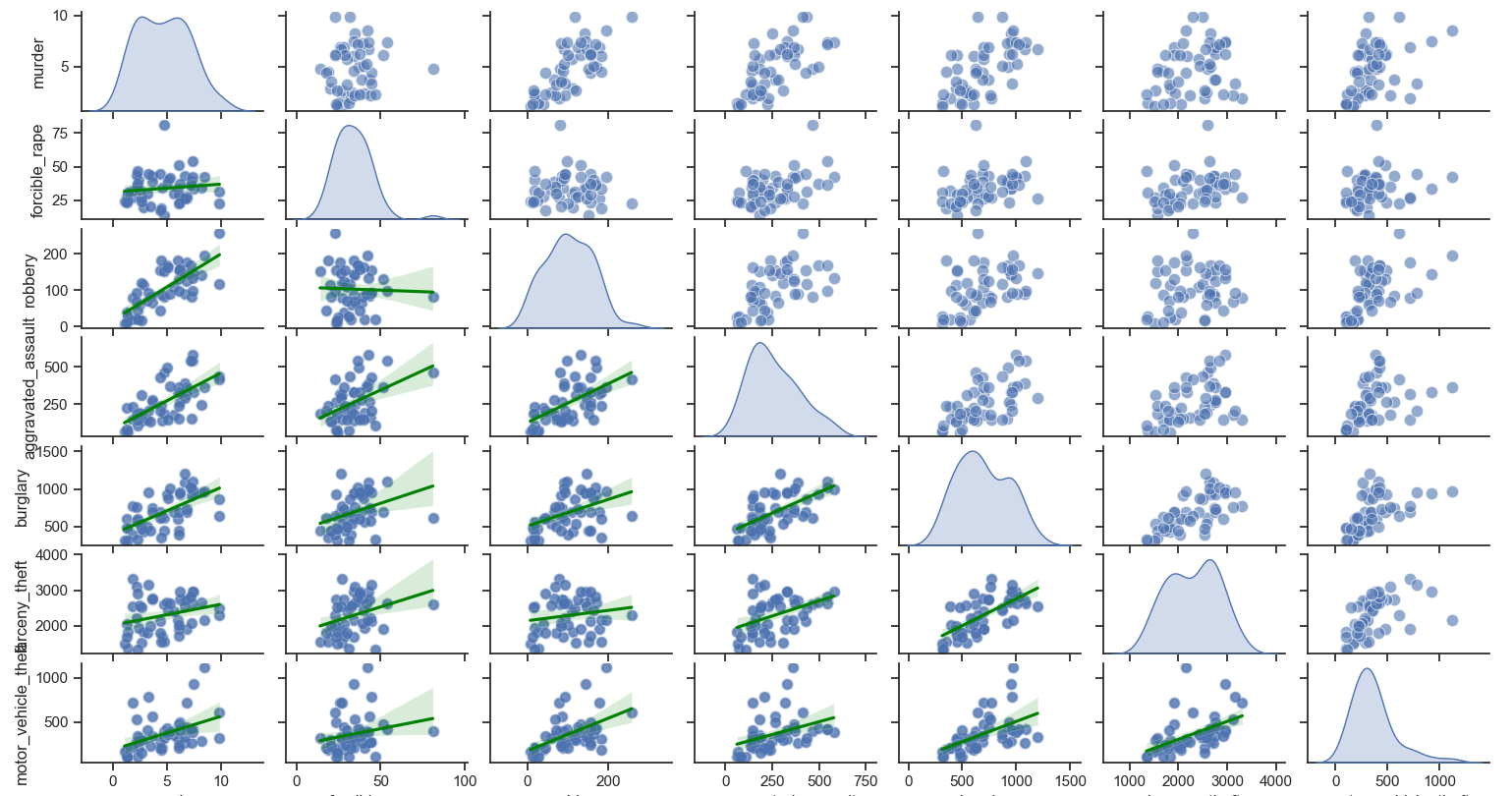
代码如下
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据集
crime = pd.read_csv("E:\\桌面\\crimeRatesByState2005.csv")
# 剔除 United States 和 District of Columbia 数据
crime_filtered = crime[(crime.state != 'United States') & (crime.state != 'District of Columbia')]
# 选择七种犯罪类型的数据
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault',
'burglary', 'larceny_theft', 'motor_vehicle_theft']
# 设置绘图风格和大小
sns.set(style="ticks")
plt.figure(figsize=(20, 20))
# 创建散点图矩阵
scatter_matrix = sns.pairplot(crime_filtered[crime_types],
diag_kind='kde', # 对角线上显示核密度估计
markers='o', # 使用圆形标记
plot_kws={'alpha': 0.6, 's': 80}) # 设置点的透明度和大小
# 在每个子图上添加回归线,将颜色设置为绿色
scatter_matrix.map_lower(sns.regplot, scatter_kws={"alpha": 0.5}, line_kws={"color": "green"})
# 为整个图添加标题
plt.suptitle('七种犯罪类型之间的散点图矩阵', fontsize=16, y=1.02)
# 保存图表
plt.savefig('crime_scatter_matrix.png', dpi=300, bbox_inches='tight')
# 显示图表
plt.show()
4、热力图
我将使用热力图来探究数据集中七种犯罪类型之间的相关关系,因为热力图能够清晰地展示变量之间的相关性数值。
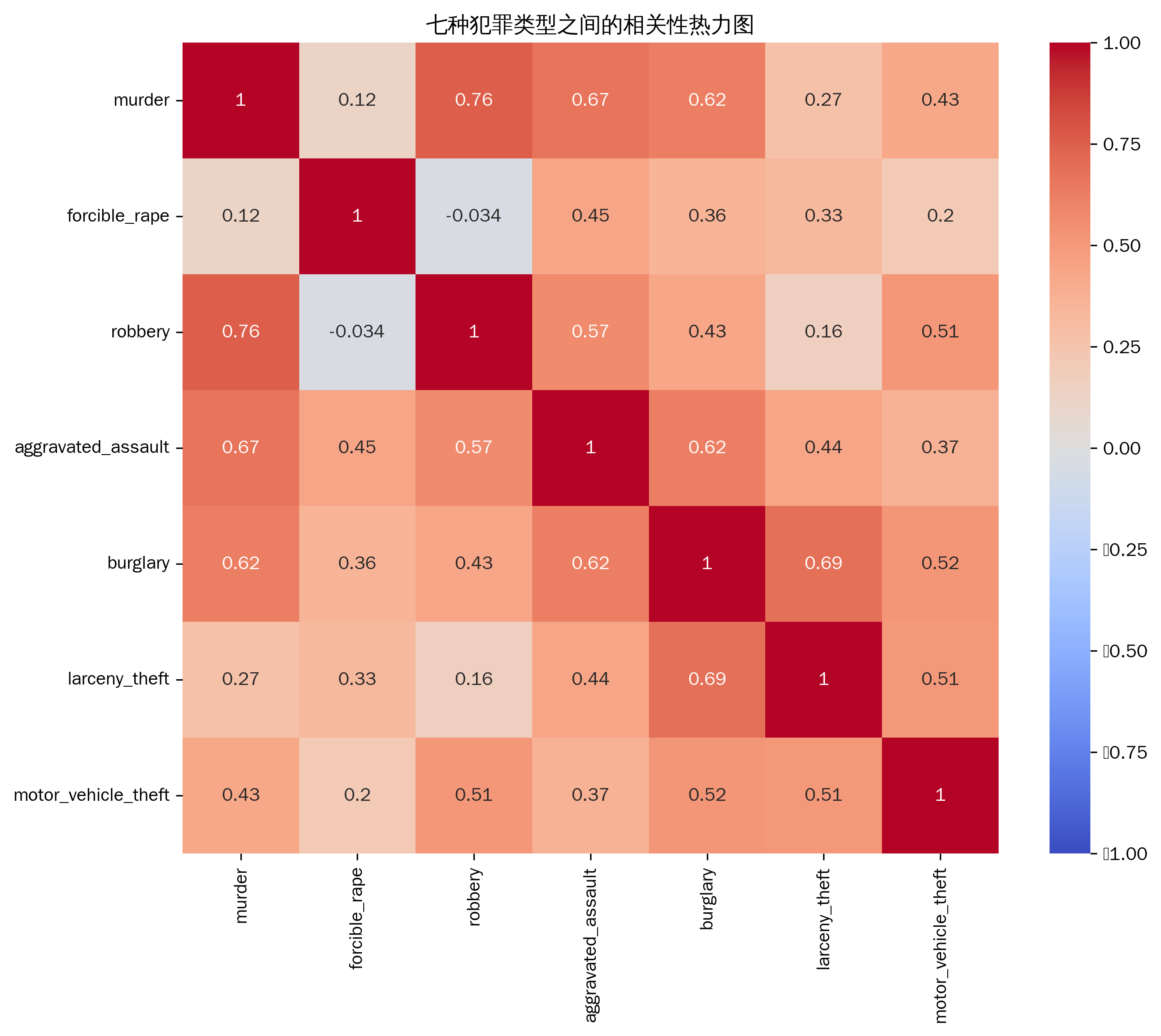
从热力图中可以直观地看到不同犯罪类型两两之间的相关性系数,颜色越接近暖色(如红色)表示正相关性越强,越接近冷色(如蓝色)表示负相关性越强。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据集
crime = pd.read_csv("D:\crimeRatesByState2005.csv")
# 剔除 United States 和 District of Columbia 数据
crime_filtered = crime[(crime.state != 'United States') & (crime.state != 'District of Columbia')]
# 选择七种犯罪类型的数据
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault',
'burglary', 'larceny_theft', 'motor_vehicle_theft']
# 设置绘图风格和大小
sns.set(style="ticks")
plt.figure(figsize=(20, 20))
# 创建散点图矩阵
scatter_matrix = sns.pairplot(crime_filtered[crime_types],
diag_kind='kde', # 对角线上显示核密度估计
markers='o', # 使用圆形标记
plot_kws={'alpha': 0.6, 's': 80}) # 设置点的透明度和大小
# 在每个子图上添加回归线,将颜色设置为绿色
scatter_matrix.map_lower(sns.regplot, scatter_kws={"alpha": 0.5}, line_kws={"color": "green"})
# 为整个图添加标题
plt.suptitle('七种犯罪类型之间的散点图矩阵', fontsize=16, y=1.02)
# 保存图表
plt.savefig('crime_scatter_matrix.png', dpi=300, bbox_inches='tight')
# 显示图表
plt.show()
5、圆形网络关系图
圆形网络关系图能够直观地展示变量之间的相关关系,节点表示变量,边的颜色和粗细表示相关性的强弱。
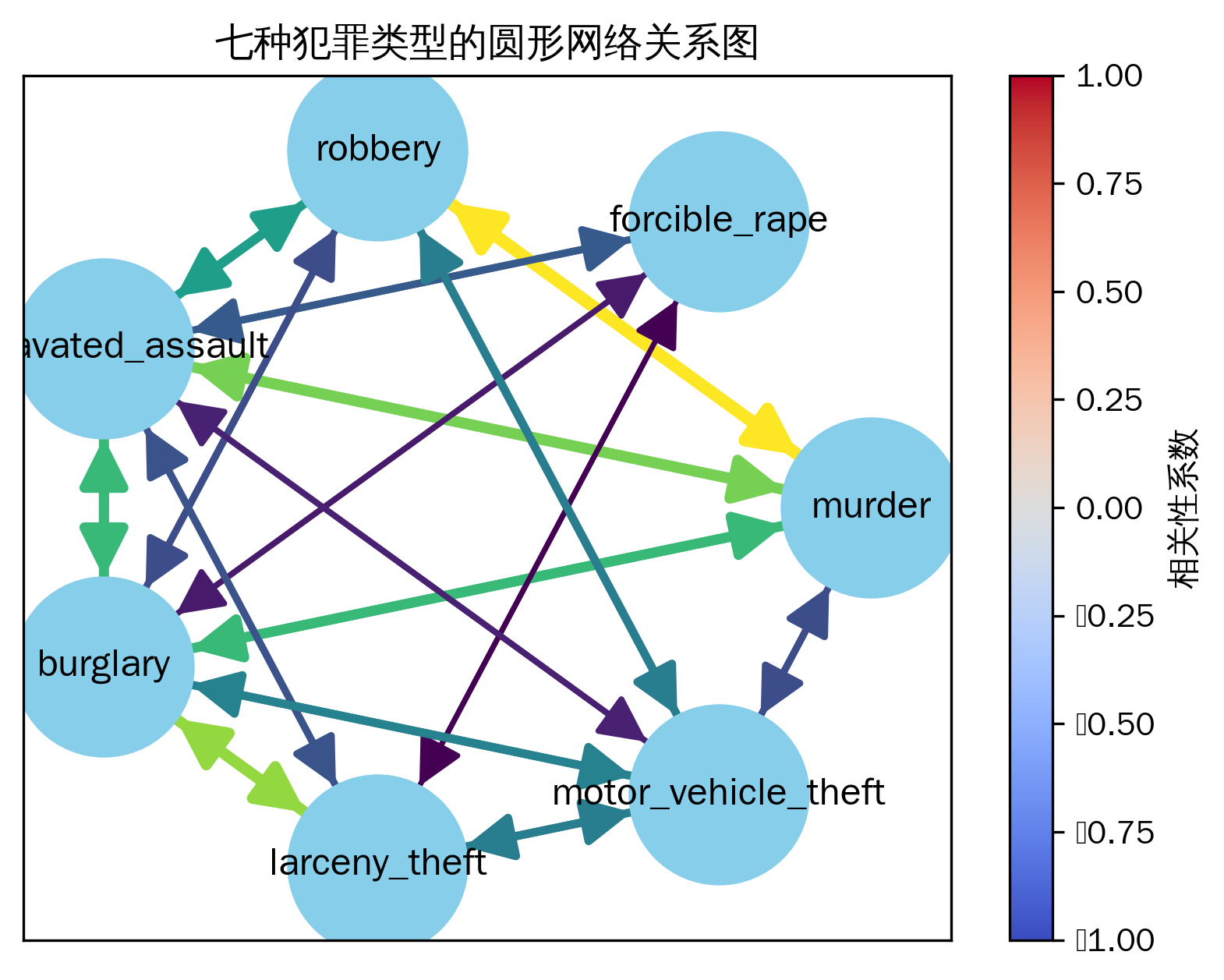
通过节点间边的连接情况、颜色和粗细,直观地判断不同犯罪类型之间相关性的强弱和方向。边越粗、颜色越偏向红色(正相关)或蓝色(负相关),表示相关性越强。
代码如下
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('/mnt/crimeRatesByState2005.csv')
# 剔除 United States 和 District of Columbia 数据
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]
# 选择七种犯罪类型的数据
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault',
'burglary', 'larceny_theft','motor_vehicle_theft']
df_selected = df[crime_types]
# 计算相关系数矩阵
corr_matrix = df_selected.corr().round(2)
# 创建有向图
G = nx.DiGraph()
# 添加节点
for crime_type in crime_types:
G.add_node(crime_type)
# 添加边,根据相关性设置边的属性
for i in range(len(crime_types)):
for j in range(len(crime_types)):
if i != j:
corr = corr_matrix.iloc[i, j]
if abs(corr) > 0.3: # 设定相关性阈值
G.add_edge(crime_types[i], crime_types[j], weight=corr)
# 绘制圆形布局的图
pos = nx.circular_layout(G)
edge_widths = [abs(G[u][v]['weight']) * 5 for u, v in G.edges()]
edge_colors = [G[u][v]['weight'] for u, v in G.edges()]
fig, ax = plt.subplots()
nx.draw_networkx(G, pos, ax=ax, with_labels=True, node_size=3000, node_color='skyblue',
font_size=12, font_weight='bold', arrowsize=30,
width=edge_widths, edge_color=edge_colors, cmap=plt.cm.coolwarm)
# 添加颜色条说明相关性
sm = plt.cm.ScalarMappable(cmap=plt.cm.coolwarm, norm=plt.Normalize(vmin=-1, vmax=1))
sm.set_array([])
plt.colorbar(sm, label='相关性系数', ax=ax)
plt.title('七种犯罪类型的圆形网络关系图')
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei']
plt.show()
实验总结
| 图的类型 | 优点 | 缺点 | 要素 | 适用场景 |
|---|---|---|---|---|
| 联合图 | 将散点图、回归直线和边缘直方图结合,能直观展示两个变量间关系,呈现每个变量自身分布情况;通过相关系数和p值,量化变量间关联程度,判断相关性显著性 | 难以展示多个变量关系;对数据量和分布有要求,数据量少或分布极端时,展示效果和结论可靠性受影响 | 散点图、回归直线、边缘直方图、相关系数、p值 | 探索两个变量间关系和分布;分析变量相关性,判断是否存在线性关系及关系强度;初步筛选可能相关变量,为后续深入分析提供方向 |
| 动态散点图 | 动态展示数据,直观呈现变量关系;交互性强,方便用户从不同角度观察数据,探索规律 | 依赖特定绘图库和环境,兼容性有问题;数据更新不及时;不适合展示复杂关系 | 散点、坐标轴、动态效果 | 展示两个变量的关系;实时监测数据变化,观察变量关系动态变化;探索性数据分析,发现潜在规律 |
| 散点图矩阵 | 可同时展示多个变量两两之间关系,全面呈现数据特征;对角线上的核密度估计图展示变量分布,了解数据分布形态;通过添加回归线,分析变量间线性关系 | 图形复杂,变量多时有视觉干扰;对数据量有要求,数据量少无法准确展示关系和分布;只能初步分析,难以进行精确量化分析 | 散点图、核密度估计图、回归线 | 探索多个变量间关系;分析变量间相关性和分布特征;筛选关键变量,为后续建模和分析做准备 |
| 热力图 | 清晰展示变量间相关性数值,颜色直观反映相关性强弱和正负;能同时展示多个变量相关性,呈现整体关系格局 | 只能展示相关性,无法确定因果关系;对数据标准化有要求,否则影响结果解读;颜色映射需合理选择,否则产生误导 | 颜色映射、相关性系数矩阵 | 分析多个变量间相关性;寻找变量间潜在关系;展示数据矩阵特征,如协方差矩阵、相关系数矩阵 |
| 圆形网络关系图 | 直观展示变量间相关关系,节点和边的设计使关系清晰;边的颜色和粗细反映相关性强弱,便于观察和比较 | 难以展示复杂关系细节;对节点和边布局有要求,布局不合理影响可读性;无法精确量化相关性数值 | 节点、边、颜色、边的粗细 | 展示变量间相关关系;分析复杂系统中各因素联系;发现关键变量和紧密关联变量组 |

















 3024
3024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









