






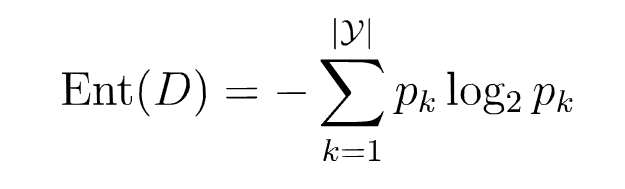
import numpy as np
def calcGini(y):
"""计算GINI系数"""
label_counts = {}
for label in y:
if label not in label_counts:
label_counts[label] = 0
label_counts[label] += 1
gini = 1.0
total_count = len(y)
for label in label_counts:
probability = float(label_counts[label]) / total_count
gini -= probability ** 2
return gini
def splitDataSet(data_X, data_Y, index, value):
"""根据某个特征的值将数据集划分为两部分"""
left_X, left_Y, right_X, right_Y = [], [], [], []
for i in range(len(data_X)):
if data_X[i][index] < value:
left_X.append(data_X[i])
left_Y.append(data_Y[i])
else:
right_X.append(data_X[i])
right_Y.append(data_Y[i])
return np.array(left_X), np.array(left_Y), np.array(right_X), np.array(right_Y)
def chooseBestFeature(data_X, data_Y):
m, n = data_X.shape
bestFeature = -1
bestFeaVal = -1
minFeaGini = np.inf
for i in range(n): # 遍历所有特征
fea_cls = np.unique(data_X[:, i]) # 获取该特征下的所有特征值
for j in fea_cls: # 遍历所有特征值
newEqDataX, newEqDataY, newNeqDataX, newNeqDataY = splitDataSet(data_X, data_Y, i, j) # 进行数据集切分
feaGini = 0 # 计算基尼指数
if len(newEqDataY) > 0:
feaGini += newEqDataY.size / m * calcGini(newEqDataY)
if len(newNeqDataY) > 0:
feaGini += newNeqDataY.size / m * calcGini(newNeqDataY)
if feaGini < minFeaGini:
bestFeature = i
bestFeaVal = j
minFeaGini = feaGini
return bestFeature, bestFeaVal
# 示例数据集
data_X = np.array([
[5.1, 3.5],
[4.9, 3.0],
[6.7, 3.1],
[6.0, 3.0],
[5.5, 2.5]
])
data_Y = np.array([0, 0, 1, 1, 1])
bestFeature, bestFeaVal = chooseBestFeature(data_X, data_Y)
print(f"Best Feature Index: {bestFeature}, Best Feature Value: {bestFeaVal}")
//todo
预剪枝
提前停止树的构建而对树剪
后剪枝
目的
避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟合。
代码
基尼系数
树的构建
决策树的分类函数
预剪枝
后剪枝
```
import scala.collection.immutable.ListMap
import scala.math.*
import scala.jdk.CollectionConverters.*
import scala.util.chaining.*
enum Node:
case Leaf(value: Any)
case Branch(label: String, children: ListMap[Any, Node])
object C45DecisionTree:
def createTree(dataSet: List[List[Any]], labels: List[String]]): Node =
val classList = dataSet.map(_.last)
if classList.forall(_ == classList.head) then
Node.Leaf(classList.head)
else if dataSet.head.size == 1 then
Node.Leaf(majorityCnt(classList))
else
chooseBestFeatureToSplit(dataSet, labels) match
case -1 => Node.Leaf(majorityCnt(classList))
case bestFeat =>
val bestFeatLabel = labels(bestFeat)
val subLabels = labels.patch(bestFeat, Nil, 1)
val children = dataSet
.map(_(bestFeat))
.distinct
.map: value =>
value -> createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
.to(ListMap)
.tap: m =>
if m.size > 1 then m.view.mapValues(_.toString.take(20)).foreach(println)
Node.Branch(bestFeatLabel, children)
private def majorityCnt(classList: List[Any]]): Any =
classList.groupMapReduce(identity)(_ => 1)(_ + _)
.maxBy(_._2)
._1
private def chooseBestFeatureToSplit(dataSet: List[List[Any]], labels: List[String]]): Int =
if dataSet.isEmpty || dataSet.head.size <= 1 then -1
else
val baseEntropy = calculateEntropy(dataSet)
(0 until (dataSet.head.size - 1))
.map: i =>
i -> (baseEntropy - calculateWeightedEntropy(dataSet, i))
.maxByOption(_._2)
.map(_._1)
.getOrElse(-1)
private def calculateEntropy(dataSet: List[List[Any]]]): Double =
if dataSet.isEmpty then 0.0
else
val classList = dataSet.map(_.last)
val total = classList.size.toDouble
classList
.groupMapReduce(identity)(_ => 1.0/total)(_ + _)
.values
.map: p =>
-p * log2(p)
.sum
private def calculateWeightedEntropy(dataSet: List[List[Any]], featureIndex: Int): Double =
if dataSet.isEmpty then 0.0
else
val total = dataSet.size.toDouble
dataSet
.groupBy(_(featureIndex))
.view
.mapValues: subset =>
val p = subset.size.toDouble / total
p * calculateEntropy(subset.map(_.patch(featureIndex, Nil, 1)))
.values
.sum
private def splitDataSet(dataSet: List[List[Any]], featureIndex: Int, value: Any): List[List[Any]] =
dataSet
.filter(_(featureIndex) == value)
.map(_.patch(featureIndex, Nil, 1))
```

















 2562
2562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









