






YOLO(you only look once,能耐的宣言🙃)对象检测开创性方法之一
动机:
处理复杂图像信息,人的视觉系统足够快准,例如驾驶,但如今系统采取
1。重复用分类器的方式,DPM,detect目标的不同位置,可缩放,滑行
2。R-CNN:①generate potential bounding boxes② classification③后处理修正边框,消重复,依据其它目标重新定位(Pipe|ine得分开训练,难优化,)不够“优雅”,Y0L0应运而生
特点:
1快:single stage
一一实时系统应用,如自动驾驶,机器人系统响应
2迁移性好:
简单易用,训练方便:
3准确性:图像整体特征把握较准确
不足:较小目标对象难精准定位
原理:
视之为单回归问题,输入X,找F(X)使之输出一连续的结果,这里是boundbox的坐标
灵感来源:人类视觉系统够快、准,且能同时定位与识别对象
Input:
5 basic parameters
①分格:SXS分割
②进行预测,参数确定:1(x,y)指图片中心相对于整张图的坐标(≈绝对位置)此图中心所在的grid cell 近O坐标(a,b),则偏移值.为(x*S/w-a,y*S/h-b),使之∈(0,I)
同时怎IOU:共同处(预测的与实际之交集/并集,表征预测准确性),定义confidence?:块分得准不准
串连多个参数的公式方法:Pr(class | object) * Pr(object) * IOU (pred, truth) = Pr(class) * IOU,用条件概率从物体最终指向class
多格对一的特殊情况取最大的iou格
怎LOSF应IOU处理:non-maximum value抑制:将上面结果取最大的
end 1 grid Be responsibie for a boundbox,cause poor detection effect on small objects and dense objects:
ay对应不准,可更细的grid,或1g应多个boundbox,再取每个box结果均值
output:Tensor
网络搭建实现:
参考GoogleNet,特点为设计灵活的网络结构分层次处理大量输入数据以及层层降低参数防止过拟合
⊕


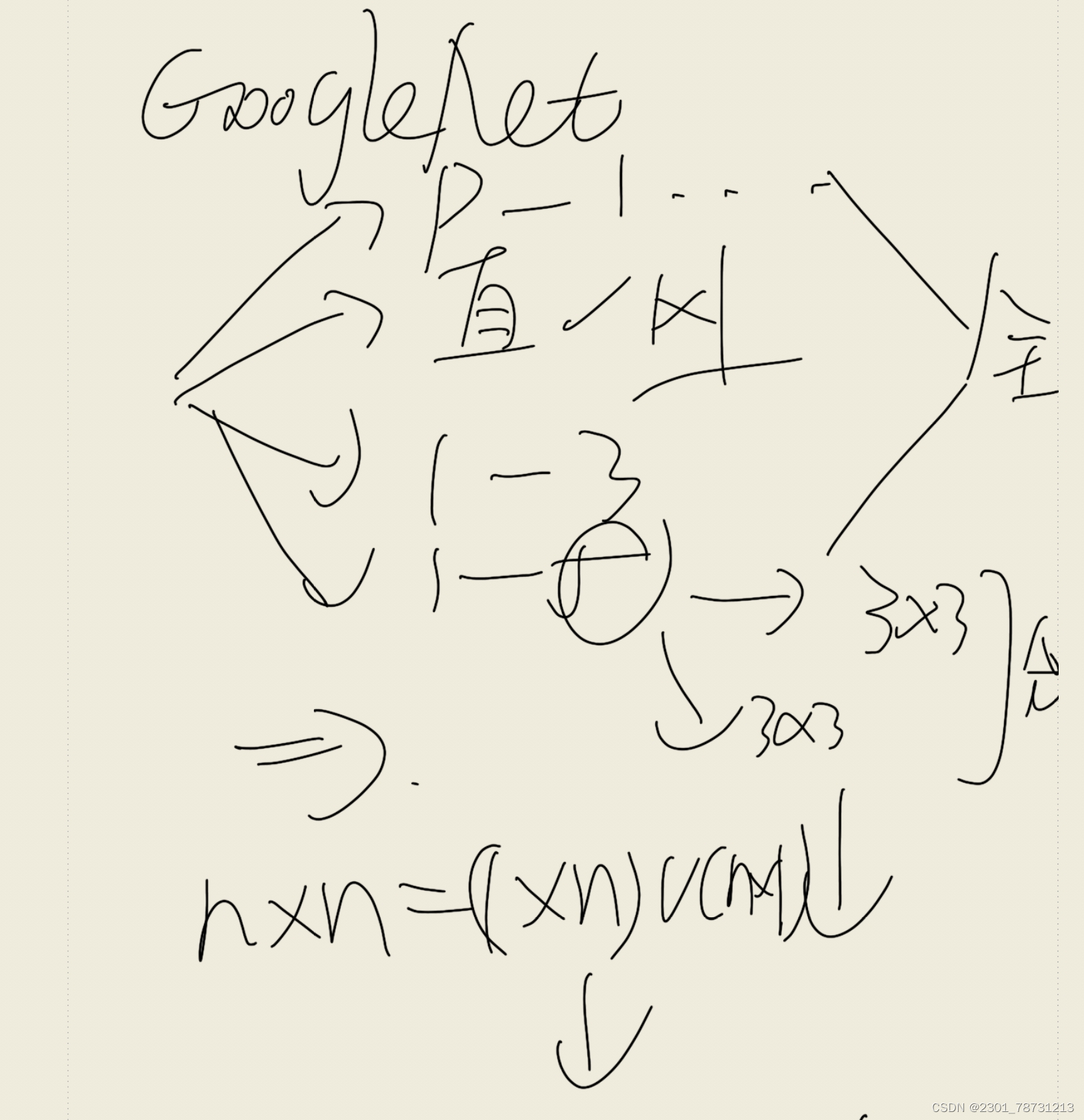


未用Inception这稀疏结构,代以1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合⊕)+3x3卷积层

公式:1^Obj ij(C-C^)^2 预测Objbox,Confidence,及非测物体box的~都要考虑
(p-p^)^2,分类误差
为下采样屏?:压缩图,[x,y,z,w],对矩阵:,特征粒度↑:
LOSS计算:
公式解析⊕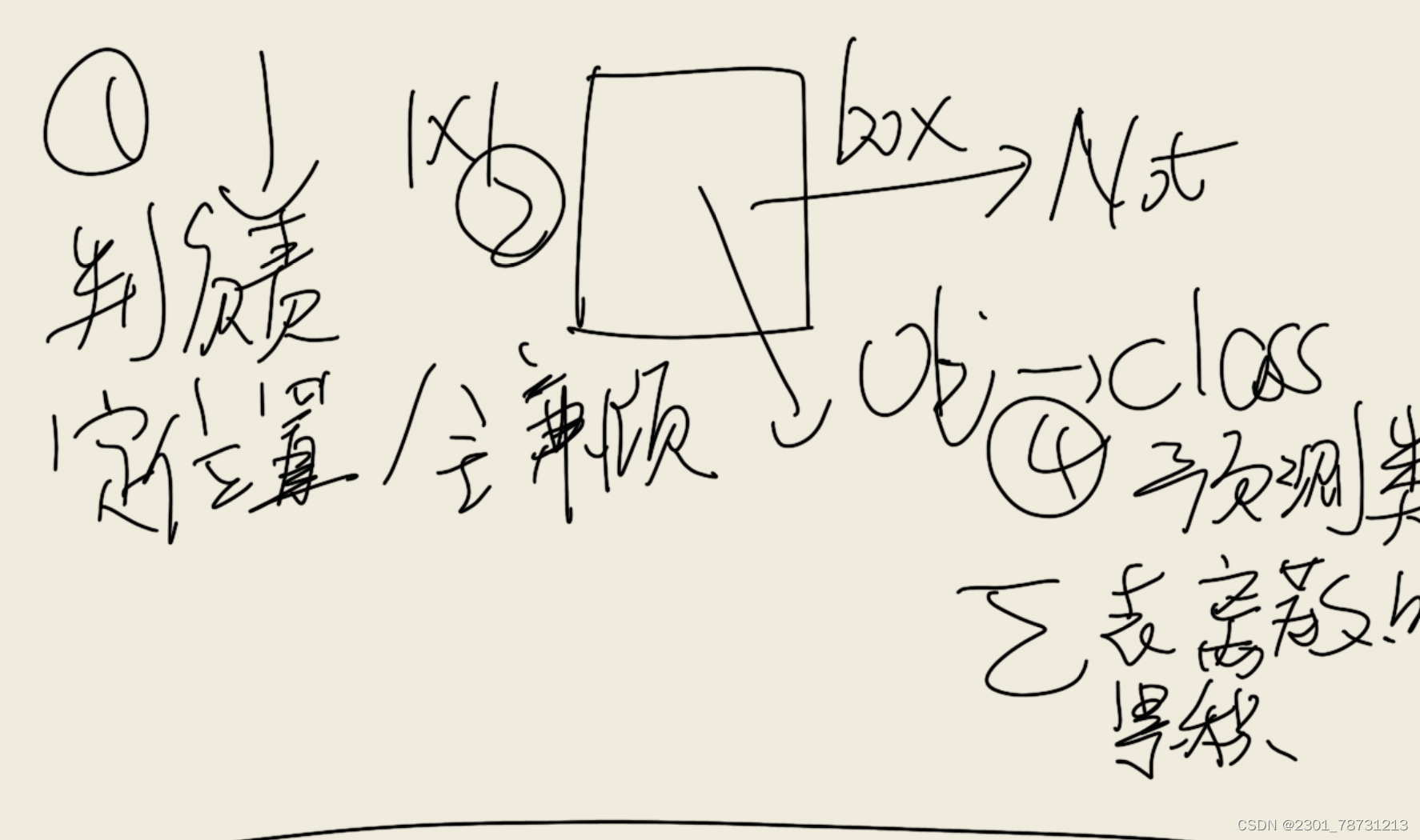
注:IOU大的计算①,有物体的得④
进一步思考:
Y0L0方法敏捷性好,但如果需要对图像信息进行有逻辑层次的深度加工学习似乎不当,能否先由整体到局部刬分图片信息并优先学习整体特征,再在学习的过程中依据需要不断填充细节特征,完成对目标不同层次的理解
对自主搭建网络的启发:
1数据:1抓住重点,适当放弃(关联较小数据项),省资提效(另见CNN卷积核的局部处理特性)
2结构上:将CNN视为提升训练效果的原子构件
3整体:1借鉴人的视觉活动优势,从功能应用整体入手构建理想模型,再思考作为“部分“的结构职能(自上而下)
2不仅考量训练效果(质量)还要考量训练的时间成本与资源消耗(效率,“性价比”),以及性能提升,迁移应用的便利性(灵活)















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









