







文/李少锋
阿里云瑶池旗下的云原生数据仓库AnalyticDB MySQL版是基于湖仓一体架构打造的实时湖仓。本文将分享AnalyticDB MySQL Spark助力构建低成本数据湖分析的最佳实践。
全文目录:
- AnalyticDB MySQL介绍
- AnalyticDB MySQL Serverless Spark核心优化
- 基于AnalyticDB MySQL湖仓版的最佳实践
*文章转载自DataFunTalk
AnalyticDB MySQL介绍
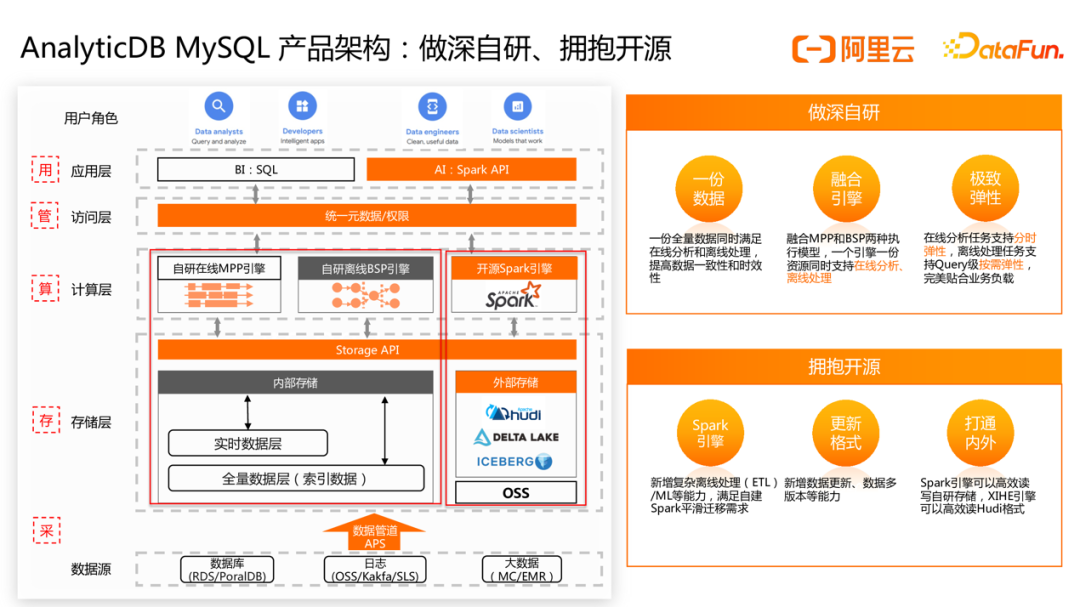
首先介绍下AnalyticDB产品架构, AnalyticDB湖仓版产品架构包含自研和开源两部分。AnalyticDB湖仓版在数据全链路的「采存算管用」5 大方面都进行了全面升级和建设。
在「采集」方面,我们推出了数据管道 APS 功能,可以一键低成本接入数据库、日志、大数据中的数据,解决数据入湖仓的问题。
在「存储」方面,我们除了内置Hudi/Delta格式的外表数据湖格式能力,也对内部存储进行了升级改造。通过只存一份数据,同时满足离线、在线 2 类场景。
在「计算」方面,我们对自研的 XIHE BSP SQL 引擎进行容错性、运维能力等方面的提升,同时引入开源 Spark 引擎满足更复杂的离线处理场景和机器学习场景。
在「管理」方面,我们推出了统一的元数据管理服务,统一湖仓元数据及权限,让湖仓数据的流通更顺畅。
在「应用」方面,除了通过SQL方式的BI分析应用外,还支持基于Spark的 AI 应用。
我们希望通过在做深自研的同时,也充分拥抱开源技术,来满足不同客户的不同业务场景,帮助客户实现降本增效。
拥抱开源不仅仅只是简单集成Spark/Hudi/Delta等开源引擎,还包括湖仓库表元数据管理,以便多引擎共享,为此AnalyticDB提供了统一元数据服务管理湖仓库表元数据,湖仓中的元数据/权限可互通,不同引擎可自由访问湖仓数据而无需重复创建元数据。对于湖仓数据,为屏蔽底层数据存储格式的差异,便于第三方引擎集成,AnalyticDB提供了面向内存列存格式Arrow的Lakehouse API服务,提供统一的读写能力,满足业务对仓存储有大吞吐的诉求,对于仓存储已经通过Arrow格式完成Spark引擎对接。
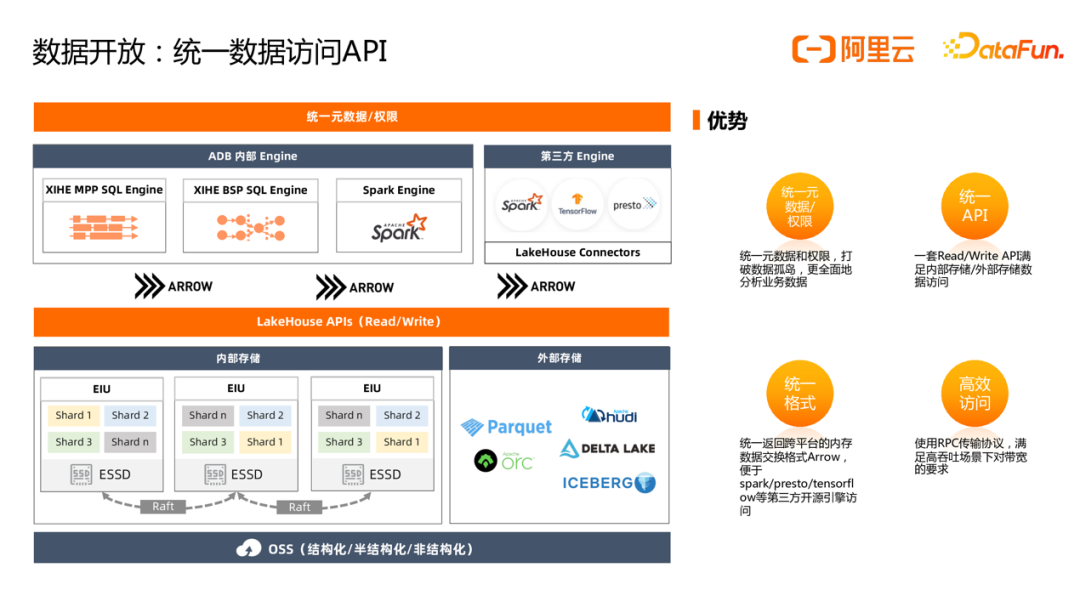
可以看到在AnalyticDB拥抱开源技术方面,Spark扮演着非常重要的角色,而在引入Spark引擎后AnalyticDB团队基于Spark引擎也做了非常多的优化,让其更符合云原生的场景。
AnalyticDB MySQL Serverless Spark核心优化
接下来分享AnalyticDB Spark的核心优化,下图是AnalyticDB Spark整体架构。
- 最上层是面向用户的使用入口,包括AnalyticDB SQL/Jar控制台、AnalyticDB作业调度控制台,以及阿里云DMS、Dataworks调度系统,以及贴合开源Spark用户使用习惯的SparkSubmit脚本方式。
- 支持控制台和调度系统提交Spark作业的是OpenAPI模块,该模块提供了规范的API能力,对下对接管控服务,对上支持各类系统集成AnalyticDB Spark服务。
- Spark管控服务负责管理Spark作业,该服务以多租形态部署,负责Spark作业资源校验,元数据管理,状态管理,安全校验等方面。
- 下一层由Driver和多个Executor组成的Spark集群,该集群归属于AnalyticDB实例的资源组,不同资源组之间的资源相互隔离,互不影响,Driver、Executor都会通过统一元数据服务请求库表元信息,通过统一管控底座申请弹性资源。
- 最底层是AnalyticDB Spark支持的各类数据源,大体分为两类,一类是OSS/MaxCompute等通过AnyTunnel/STS Token进行授权访问的数据源,另一类是用户VPC下如AnalyticDB/RDS/HBase等需要通过ENI弹性网卡技术打通不同VPC网络才能访问的数据源。
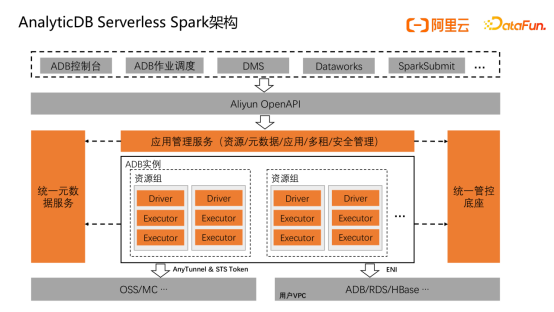
为让客户更便捷使用AnalyticDB Spark,享受云上Serverless Spark带来的弹性、性价比优势,低门槛被集成能力是关键的一环,因此AnalyticDB Spark基于阿里云OpenAPI规范开发了30个API来管理Spark作业,覆盖全生命周期管理,包括提交作业、停止作业、获取作业状态、获取作业日志等。
基于OpenAPI能力支持了阿里云DMS、Dataworks调度系统,同时为了满足客户自建调度系统如自建Airflow场景,AnalyticDB Spark也支持Airflow调度并且将此特性贡献到了Airflow官方开源仓库,便于社区用户更方便使用AnalyticDB Spark。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









