






在当今的深度学习领域,TensorFlow无疑是最受欢迎和广泛使用的开源框架之一。它提供了强大的计算能力和灵活性,使得开发者能够轻松地构建、训练和部署各种深度学习模型。本博客将带你深入了解TensorFlow的基本概念、特性以及它在实一些案例。 
一、TensorFlow概述
TensorFlow是由Google Brain团队开发的开源机器学习框架,用于进行高性能的数值计算。其名称来源于它的核心数据结构——张量(Tensor),以及计算流程图(Flow)的概念。TensorFlow支持分布式计算,可以运行在各种硬件平台上,包括CPU、GPU和TPU(Tensor Processing Unit)。
TensorFlow的主要特点包括:
- 灵活性:TensorFlow支持动态计算图,允许在运行时改变计算流程。
- 高效性:通过底层的XLA(Accelerated Linear Algebra)优化,TensorFlow能够高效地执行复杂的数学运算。
- 可移植性:TensorFlow支持多种操作系统和硬件平台,使得模型可以在不同的环境中无缝迁移。
- 丰富的API:TensorFlow提供了Python、C++、Java等多种语言的API,方便开发者使用。
二、TensorFlow框架的基础架构和用途
2.1 基础架构
计算图:TensorFlow使用计算图来表示计算过程。图中的节点表示操作(如矩阵乘法),而边则表示在这些操作之间流动的数据(称为张量,Tensor)。
会话:会话是TensorFlow运行计算图的环境。你可以通过会话来启动图中的操作,并获取结果。
操作(Operations):TensorFlow提供了大量的操作(Ops)来处理数据,如矩阵乘法、卷积等。这些操作可以组合起来构建复杂的模型。
设备:TensorFlow支持在多种设备上运行计算,包括CPU、GPU和TPU(Tensor Processing Units)。这允许开发者根据计算需求选择最合适的设备。
分布式计算:TensorFlow支持分布式计算,允许在多个设备上并行处理计算任务,以加速训练过程。
2.2 主要用途
机器学习模型构建:TensorFlow允许开发者定义和训练各种类型的机器学习模型,包括神经网络、深度学习模型等。
模型训练:通过TensorFlow的优化算法和自动微分功能,开发者可以训练模型以适应数据,并优化模型参数。
模型部署:训练好的模型可以部署到各种环境中,如移动设备、服务器或嵌入式系统,以进行实时预测或分析。
可视化与调试:TensorFlow提供了TensorBoard等工具,帮助开发者可视化训练过程、模型结构以及性能指标,从而进行调试和优化。
三、优势
在深度学习框架的海洋中,TensorFlow、PyTorch和MXNet各自有着独特的特点和优势。然而,TensorFlow在某些方面相对于PyTorch和MXNet表现出了更为突出的优势。
接下来我们先解析PyTorch和MXNet的优缺点,适用于哪些情况,有哪些特殊限制条件。
3.1 PyTorch优缺点:
优点
动态图:使得模型构建和调试更加灵活。
易于使用:API直观,上手快。
GPU加速:支持GPU训练,加速模型训练过程。
社区支持:拥有活跃的社区和丰富的资源。
广泛应用:适用于多种深度学习应用场景。
缺点
性能:与某些静态图框架相比,性能可能稍逊一筹。
部署:将模型部署到生产环境可能较为复杂。
内存占用:处理大规模数据时可能占用较多内存。
适用情况
研究和开发:PyTorch的灵活性使其成为研究和开发阶段的理想选择。
原型设计:快速构建和测试新的神经网络架构。
限制条件
内存限制:使用PyTorch时需要注意内存使用情况,特别是在处理大规模数据集时。
性能优化:为获得最佳性能,可能需要优化PyTorch代码。
模型部署:将PyTorch模型部署到生产环境可能需要额外的步骤和资源。
3.2 MXNet的优缺点
优点:
跨平台支持:MXNet支持多种操作系统和编程语言,方便开发者使用。
高性能:底层优化使得MXNet在计算上非常高效,特别适用于大规模数据集的训练和推理。
分布式训练:支持多机多卡训练,提升训练速度。
缺点:
学习曲线较陡:对于初学者来说,可能需要更多的时间去熟悉和掌握MXNet。
社区规模较小:相比TensorFlow和PyTorch,MXNet的社区和生态系统相对较小。
适用情况:
MXNet适用于需要高效计算、跨平台支持和分布式训练的机器学习和深度学习项目。无论是图像识别、自然语言处理还是其他任务,MXNet都能提供强大的支持。
特殊限制条件:
MXNet本身并没有明显的特殊限制条件,但由于社区规模较小,可能会在某些高级功能或特定应用场景下缺乏足够的支持和文档。
我们通过上面观察PyTorch和MXNet的优缺点,已经了解了PyTorch和MXNe适用于哪些情况,有哪些特殊限制条件。然后将说明TensorFlow的优势。
3.3TensorFlow的优势:
-
丰富的生态系统:TensorFlow提供了从数据预处理到模型部署的完整工具和库,包括TensorBoard等强大的可视化工具。
-
广泛的应用:TensorFlow在计算机视觉、自然语言处理等多个领域都有广泛的应用和大量的案例。
-
强大的分布式计算能力:TensorFlow支持多种分布式计算策略,能够高效处理大规模数据和模型。
-
社区和企业支持:TensorFlow由Google支持,拥有庞大的社区和丰富的资源,包括文档、教程和代码示例。
要注意的是,以上优势并非绝对,每个框架都有其独特的特点和适用场景。在选择深度学习框架时,应根据具体需求和项目特点进行综合考虑。
3.4 结论:
TensorFlow相对于PyTorch和MXNet在生态系统、应用、分布式计算能力和社区支持等方面表现出了更为突出的优势。然而,每个框架都有其独特的特点和适用场景,在选择深度学习框架时,还需要根据具体需求和项目特点进行综合考虑。无论是TensorFlow、PyTorch还是MXNet,都是优秀的深度学习框架,选择哪个框架取决于你的具体需求和偏好。
四、TensorFlow应用案例
在本博客项目中,我们将使用TensorFlow来构建一个神经网络模型,用于预测银行客户是否会购买特定的银行产品。首先,我们需要从train.csv和test.csv数据集文件中读取训练和测试数据集。
train.csv和test.csv是两个用于泰坦尼克号生存预测竞赛的公开数据集,分别包含891条和418条数据记录,以CSV格式存储,并包含多个与乘客相关的属性。这两个数据集被广泛用于数据分析,以评估模型在预测乘客生存情况方面的性能。
train.csv和test.csv数据集下载链接:
https://tianchi.aliyun.com/competition/entrance/531993/information
4.1 查看目标变量(是否购买银行产品)的类别分布
import pandas as pd
import numpy as np
# 读取训练数据
df = pd.read_csv("/train.csv")
test = pd.read_csv("/test.csv")
# 查看目标变量“subscribe”的类别分布
print("目标变量'subscribe'的类别分布:")
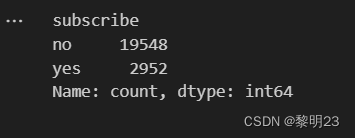
print(df['subscribe'].value_counts())上述代码片段执行后,将输出“subscribe”列中不同类别的数量,通常这是一个二元分类问题,比如'yes'(表示购买了银行产品)和'no'(表示未购买)。
4.2 数据预处理与探索性分析
1.分离数值变量与分类变量
在构建机器学习模型之前,通常需要将数据集中的特征分为数值变量和分类变量。数值变量可以直接用于模型训练,而分类变量则需要经过编码转换为数值形式。
在数据处理和准备阶段,一个常见的步骤是检查目标变量的分布,以了解我们即将解决的问题的不平衡程度。下面我们将使用pandas库来读取数据,并查看目标变量“subscribe”的类别分布。
from sklearn.preprocessing import LabelEncoder
import seaborn as sns
import matplotlib.pyplot as plt
# 分离数值变量与分类变量(不包括目标变量subscribe)
Nu_feature = list(df.select_dtypes(exclude=['object']).columns)
Ca_feature = list(df.select_dtypes(include=['object']).columns)
# 如果subscribe是目标变量且是一个分类变量,确保它不包括在Ca_feature中
if 'subscribe' in Ca_feature:
Ca_feature.remove('subscribe')2对分类变量进行编码
由于神经网络模型不能直接处理字符串类型的分类变量,我们需要使用LabelEncoder对它们进行编码。
# 对分类变量进行编码(不包括目标变量subscribe)
lb = LabelEncoder()
for m in Ca_feature:
df[m] = lb.fit_transform(df[m])
test[m] = lb.transform(test[m]) # 使用transform而不是fit_transform3.处理目标变量
如果目标变量“subscribe”在数据集中是字符串类型的'no'和'yes',我们可以将其转换为数值形式。
# 由于subscribe是目标变量,在训练模型时不需要对其进行编码
# 但如果它在df中是字符串类型的'no'和'yes',可以将其转换为数值类型
df['subscribe'] = df['subscribe'].replace(['no', 'yes'], [0, 1]) # 假设subscribe是字符串类型的'no'和'yes'
# 注意:test集中的subscribe不需要替换,因为测试时不需要目标变量的真实值4.数值变量相关性分析
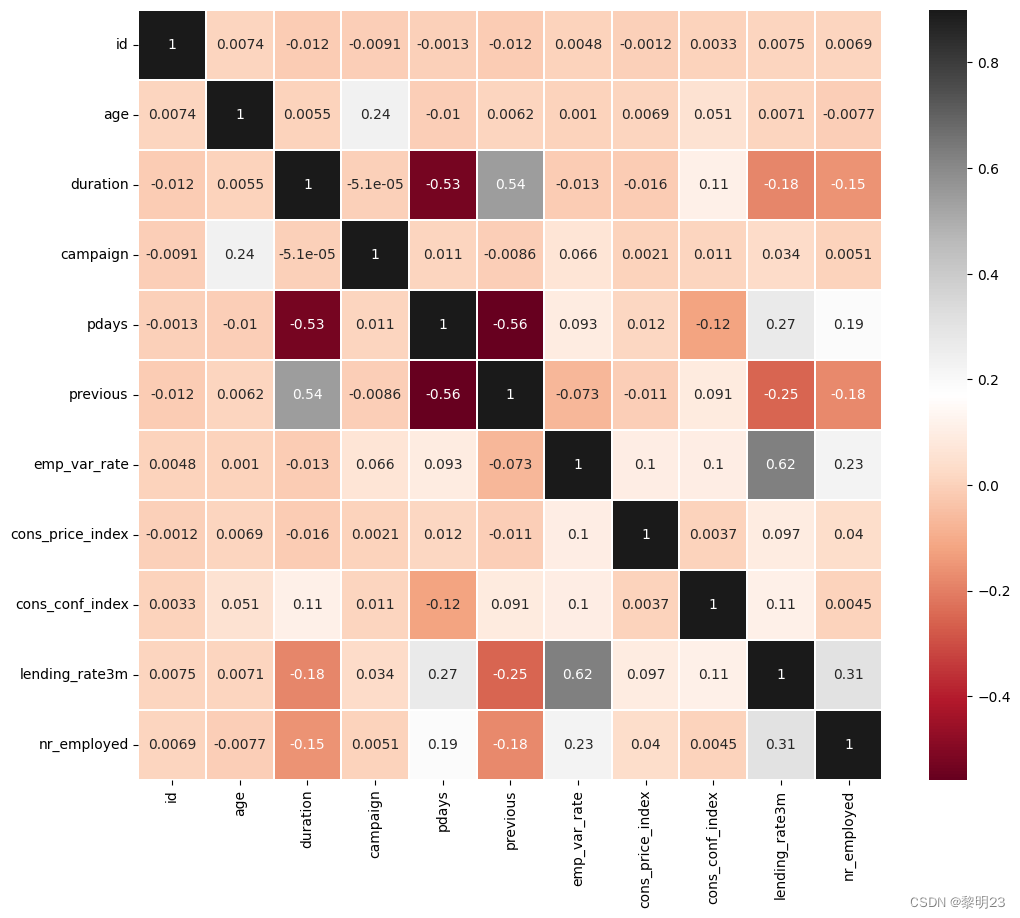
通过计算数值变量之间的相关性矩阵,我们可以了解哪些特征与目标变量具有较强的相关性。
# 计算数值变量之间的相关性矩阵(不包括目标变量subscribe)
correlation_matrix = df[Nu_feature].corr()
# 绘制相关性热力图
plt.figure(figsize=(12, 10))
sns.heatmap(correlation_matrix, vmax=0.9, linewidths=0.05, cmap="RdGy", annot=True)
plt.show()通过相关性矩阵热力图,我们可以观察到一些与目标变量相关性较高的特征,这些特征在后续的模型构建中可能会占据重要的位置。
4.3 模型构建与编译
首先,我们需要导入必要的库,并准备好数据。然后,我们将使用TensorFlow的Keras API来构建和编译模型。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
# 假设 df 已经是加载好的 pandas DataFrame
X = df.drop(columns=['id', 'subscribe']) # 移除ID列和目标变量列
Y = df['subscribe'] # 目标变量
# 划分训练集和独立的测试集
x_train_full, x_test_full, y_train_full, y_test_full = train_test_split(X, Y, test_size=0.2, random_state=1)
# 转换为TensorFlow的Dataset格式
train_ds = tf.data.Dataset.from_tensor_slices((x_train_full.values, y_train_full.values))
test_ds = tf.data.Dataset.from_tensor_slices((x_test_full.values, y_test_full.values))
# 注意:在实际应用中,可能还需要对特征进行标准化或归一化,但这里为了简化,我们省略了这一步骤
# 建立模型
model = Sequential([
Dense(64, activation='relu', input_shape=(X.shape[1],)), # 输入层,设输入特征数量为X.shape[1]
Dense(64, activation='relu'), # 隐藏层
Dense(1, activation='sigmoid') # 输出层,二分类问题使用sigmoid激活函数
])
# 编译模型
model.compile(optimizer='adam', # 使用Adam优化器
loss='binary_crossentropy', # 二分类问题的损失函数
metrics=['accuracy']) # 监控准确率
# 至此,模型构建和编译完成,接下来我们将展示如何训练模型并评估其性能在上面的代码中,我们定义了一个简单的三层神经网络模型,其中两个隐藏层各有64个神经元,并使用ReLU作为激活函数。输出层有一个神经元,使用sigmoid激活函数来输出预测概率,适合二分类问题。我们使用Adam优化器和二元交叉熵损失函数来编译模型,并监控训练过程中的准确率。
1. 交叉验证与模型评估
为了评估模型的性能,我们采用了5折交叉验证。这种方法通过将数据集分为5个子集,并在每个子集上轮流作为验证集来评估模型。
# 交叉验证
result1 = []
mean_score1 = 0
n_folds = 5
kf = KFold(n_splits=n_folds, shuffle=True, random_state=2022)
for train_index, val_index in kf.split(x_train_full):
x_train, x_val = x_train_full.iloc[train_index], x_train_full.iloc[val_index]
y_train, y_val = y_train_full.iloc[train_index], y_train_full.iloc[val_index]
# 拟合模型
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
# 评估模型
val_loss, val_acc = model.evaluate(x_val, y_val)
y_pred1 = model.predict(x_val)
auc_score = roc_auc_score(y_val, y_pred1)
print('验证集AUC: {}'.format(auc_score))
result1.append(auc_score)
mean_score1 += auc_score / n_folds
# 计算平均AUC分数
print('平均验证集AUC: {}'.format(mean_score1))
# 评估测试集
test_loss, test_acc = model.evaluate(x_test_full, y_test_full)
y_pred_final = model.predict(x_test_full)
test_auc_score = roc_auc_score(y_test_full, y_pred_final)
print('测试集AUC: {}'.format(test_auc_score))总的来说,这段结果代码显示了一个深度学习模型在训练和验证过程中的性能改进,以及最终在测试集上的良好性能。AUC值的提高表明模型在分类任务上的性能得到了提升。
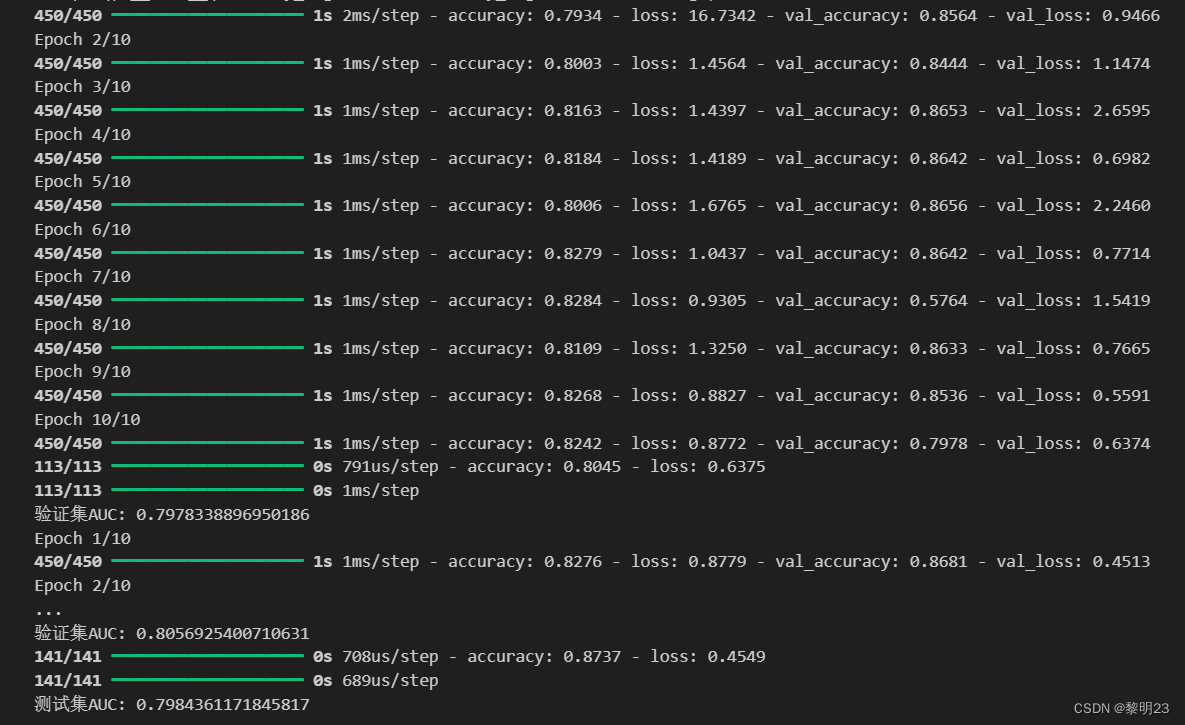
2. 保存预测结果
评估完模型后,我们将预测结果保存为CSV文件,以便后续分析或实际应用。
import pandas as pd
# 保存预测结果(转换为二分类结果)
ret1 = pd.DataFrame(y_pred_final, columns=['subscribe_prob'])
ret1['subscribe'] = np.where(ret1['subscribe_prob'] > 0.5, 'yes', 'no').astype('str')
ret1.to_csv('银行客户预测结果.csv', index=False)4.4 结论
通过交叉验证和模型评估,我们得到了模型在验证集和测试集上的性能表现。这些分析结果有助于我们优化模型,完成项目任务。
五,总结
TensorFlow是一个功能强大、灵活高效的深度学习框架,广泛应用于图像识别、自然语言处理、强化学习等领域。通过深入了解TensorFlow的基本概念、特性和应用案例,我们可以更好地掌握这一工具,并在实际项目中发挥其优势。















 4729
4729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









