






指针:
CPU(即中央处理器,是用来计算的,数据从内存中取出,结果再存入内存中,取出和存入的内存地址可能不一样)
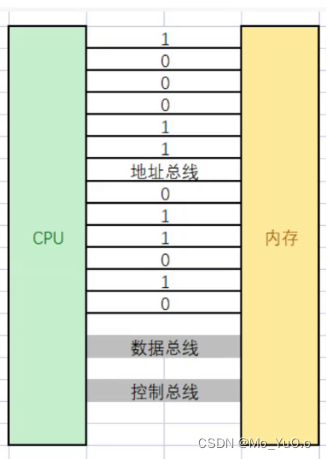
内存和地址:我们电脑会把内存划分为一个个的字节(一个内存单元为一个字节) 每个内存单元会有一个编号(以此来减少CPU查找所需的时间) ,而这个内存单元的编号 可以称为地址 , , , 地址在C语言中又称为 “指针” [2.22进行补看,理解编址]
编址: (CPU和内存间会有物理的电线连起来)当CPU取值进行计算时,CPU将要读取“数据的地址的信息传递给地址线”,地址线通过地址在“内存”中寻找该地址的数据(地址线通过高电频为1,低电频为0,32根地址线传递的数据共同组成地址),然后通过数据总线传递给CPU进行计算。 【每个内存单元都存在地址且地址都不同,但这些地址并没有存储起来,不过可以被CPU调用,然后通过地址线去内存中读取该地址的数据】
【每根地址线上都可能是0/1,因此32根地址线可能产生2的32次方种不同的信息,即2的32次方个不同的地址】{64位机器同理}
读一个数据的流程:提供地址,然后控制总线发出“Read”指令,然后通过将该地址存放的数据传入CPU,进行数据的读取
存放数据的流程:CPU产生数据,然后控制总线发出“write”指令,地址总线提供一个地址,最后数据中线将产生的数据传入到该地址处
取地址操作符——“&” &变量名 (由于每个内存单元(即一个字节)都有自己的地址,实质上,&变量名 取出的是开辟的第一个字节的地址(也是地址最小的地址))
Eg: int a = 10; printf(“%p”,&a); 注意 int 类型是4个字节,而每个内存单元都有自己的地址,因此&a 取出的是int 开辟的4个内存单元的第一个内存单元的地址(即4个地址中最低的地址)
创建指针变量: 指针指向的变量的类型* 自定义指针名 = 地址; 此处的 * 是声明该变量为指针 此处 指针指向的变量类型* 就是创建的指针变量的类型 (即int* pa =&n; 此处 指针pa 的类型为int* n的类型为int)
Eg: int n = 10; int* m = &n; 此处的int* 是由于 n的类型为int类 所以此处为
Int 而 * 是声明 m 为指针类型 故此处创建指针变量m 的 的格式是 int* m = &n;(注:int* m = &n; int * m = &n; int *m = &n; 这些写法是等同的 指针变量都为 m)
解引用操作符—— * *指针变量名 表示通过指针(即地址)来使用该地址;对应上文 *m就相当于 n; 我们使 *m = 20; 则n变化为20; *指针变量名 就是来调用该指针变量存放的地址 *m 表示指m中存放的地址位置 , 即此处 *m 就是指向 n 所在的地址(因为m中此时存放的n的地址)
指针的大小: 指针是专门来存放地址的,因此地址的大小就是指针的大小 (在X86的环境下(即32位环境下),有32根地址线,即32个比特位,也就是4个字节; 对X64的环境下(即64位环境下),有64根地址线,即64个比特位,也就是8个字节)
【由于指针的大小与地址的大小有关,在同一环境下,无论是char* 还是int* 等等,其大小都是相同的,在X86下都为4个字节,在X64下都为8个字节】
指针 -- 地址 指针变量 -- 存放地址的变量 (口头上说的指针一般是说指针变量)
指针变量的类型的意义:
指针变量的类型决定了指针解引用后访问权限的大小
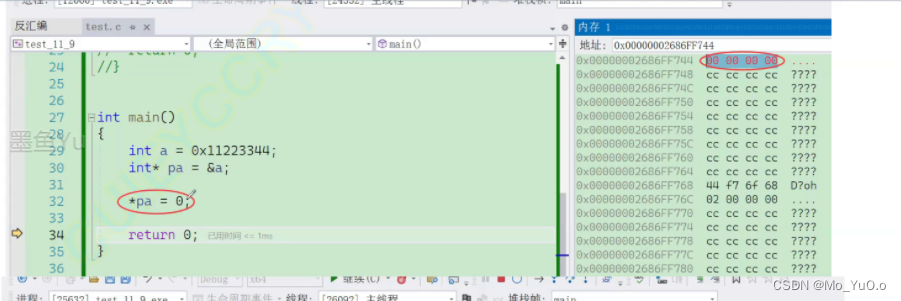
改变int类型的变量的字节中的数字,其变量的值的计算方法:

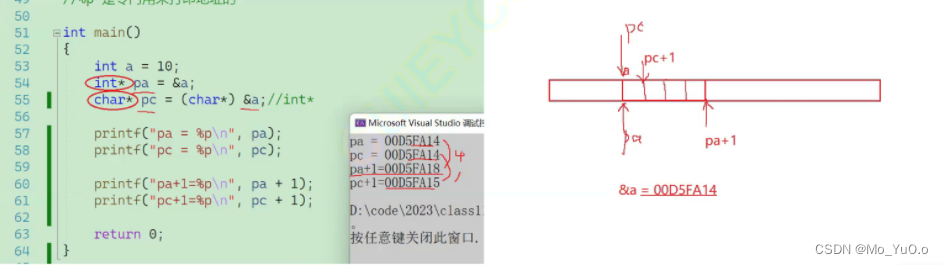
指针变量 -或者+ 整数时:指针类型决定了指针向前和向后走了几个字节。
void*类型的指针: void*类型的指针变量 可以接受任意类型变量的地址(不会报警告,经过int m = 10; char* n = &m;可以进行,但编译器的编译表格会有警告(尽管可以运行程序),但void* n = &m; 就不会报警告),【这种指针也称为泛指针】。
void* 类型的指针不能直接进行解引用操作 和 -或者+ 整数。【如果我们通过类型为void* 的指针我们可以进行强转化 , eg: int m = 10; void* n = &m; *(int*) n = 20; 则m的值最终为20】
Const 修饰变量的时候,会使变量具有常属性,无法被修改,但该变量的本质仍然是变量,只是无法被修改而已 (称这种被const 修饰的变量 为常变量)
Eg: const int m = 10; m =20; 这种情况就会报错
虽然const修饰的变量,无法直接对变量进行修改(如上面所呈现的情况),,,但我们可以通过创建指针变量获取 const修饰的变量的地址 ,,, 再对指针变量进行解引用 来修改该变量的值 (如const 修饰变量 是将 变量的正门锁住 但我们通过 上面的操作,相当于打开了变量的后门 ,从而修改变量)
Eg: const int m = 10; int* pc = &m; *pc =20; 此处的m最后值为20
Const修饰指针时:
Const放置在 * 左侧时 ,限制的是 *p(即限制指针变量p的解引用操作,但是此时p是不受限制的,即p仍可以 - 或者 + ,只是无再解引用) Eg:const int* m = &n; 或者 int const * m = &n; 而此时 通过 *m = 20;来改变n的值的这种操作是错误的,但m++;等,对m的值进行改变的操作是可以进行的
Const放置到 * 右侧时 ,限制的是 p (即指针变量p 不能再进行 – 或者+ 并且不能修改p的值的操作, 但 *p 不受限制,还是可以通过p 来修改 p所指向的对象的内容)
Eg: 写法 int * const m = &n; 此时 *m = 20; 的操作是可以的, 但 像 m++;等修改m的值的操作是错误的
同理,如果在 * 的左侧和右侧 都放置const 那么 指针变量的值将无法修改 , 通过 指针变量的解引用 来改变 指针变量指向的值 的操作也是错误的)
Eg:const int* const m =& n; 此时 m++;和*m = 20 ;的操作都是错误的
指针运算:三种 :
1. 指针变量 -或者+ 整数 : 指针变量 -或者+ 整数*sizeof(指针变量类型的去掉*号的)
Eg: int* m = &n; m++; m 每次加 4 因为sizeof(int) 为4 且m++ 与 m=m+1相同 而 1*4=4 所以结果每次 m+4
2.指针变量 – 指针变量(进行相减的前提是这两个指针变量指向的是同一块空间(同一快空间不是指同一个地址,指向同一个数组的不同元素,也是属于指向同一块空间)) : 其结果的绝对值为两个指针变量之间的元素个数的
字符串向自定义函数 传入的是第一个字符的地址(字符串的字符之间的地址也是连续的,且是从低到高(和数组中的元素地址一样)):
Eg:
Void my_stlren(char* m)
{
…
}
Int main()
{
My_strlen(“abc”);
Return 0;
}
- 指针变量间的大小关系: 指针变量之间 可以 进行 > , < ,== , <= , >= ,进行比较的是指针变量中存的地址的大小(即比较地址的高和低)
野指针:野指针就是指针的指向是不可知的(随机的,不确定的,不受限制的)
野指针的成因: 局部变量的指针变量没有初始化会产生野指针(但全局指针变量和静态指针变量会为0); 指针的越界访问 会产生野指针; 指针变量指向的空间释放了(指针变量存放了变量的地址,而该变量被销毁),该指针变量就成为了野指针;
如何规避野指针:
一.对创建的指针进行初始化:两种方法1.明确知道应该指向哪里,就使指针初始化为该变量(eg:int* m = &n) 2.如果不知道指向哪里,就先初始化为NULL(eg:int* m = NULL;) 【(NULL的本质为0,是0转化为指针类型的结果)】
二.小心指针越界
三.指针变量不再使用时,要及时将指针置为NULL,同时使用指针前,确定指针是否有效
Eg:
四.避免放回局部变量的地址
assert断言(assert是一个宏,尽管它可以想函数一样被调用,但它本质是宏而不是指针):宏assert需要引用头文件<assert.h> ; 用法: assert( p == NULL); 如果指针变量p为NULL,则无事发生,但如果p不为NULL(即条件语句返回为假)则会报错。 (assert()接受的表达式为参数,如果表达式的返回值为1,则assert()不会有任何作用,如果返回值为0,则 会报错) [assert() 可以进行关闭 , 引用头文件的代码上面添加#define NDEBUG]
assert()在debug版本才会发挥作用,而release版本会自动关闭assert()
函数中传值调用和传址调用:
传值调用函数时:函数的实参的值传递给形参时,形参是实参的一个临时拷贝(形参有自己的空间,因此形参的改变不会引起实参的改变)
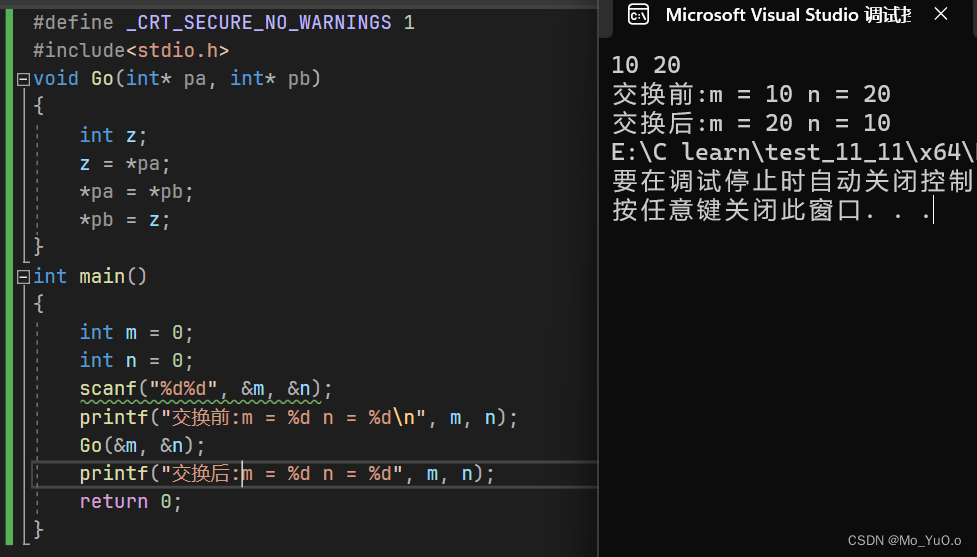
向函数的形参传递地址时,为传址调用 形参要用对应的指针类型 只传地址而不希望解引用该地址来修改这个位置的值时(即能使用 p,而不能使用*p)则形参 应为: 类似于const int* m;的形式参数; 传值调用不需要指针
当调用一个函数,然后需要改变函数外面的变量的值的时候,应选择传址调用。当函数中只需要函数外变量的值的时候,我们选择传值调用
Eg:对于写一个自定义函数,交换a,b的值:
这种写法明显是错误的,因为形参和实参是不同的地址,此处交换的形式参数x,y的值,
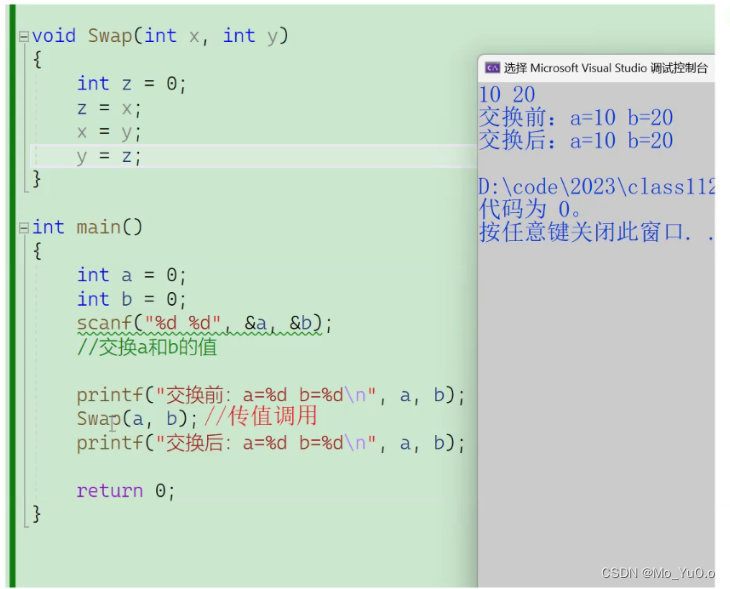
因此我们想交换a,b的值,那么我们应该在a,b的地址上进行操作(即进行传址调用)
数组名是首元素的地址,但有特殊情况(1.当sizeof()的()中单独放一个数组名的时候{即如果不是单独放数组名,则表示首元素的地址,即sizeof(arr)与sizeof(arr+0)是不同的,前者计算的是整个数组arr的大小,而后者计算的则是arr[0]的地址的大小,即在X64下为8,在X86下为4},数组名表示整个数组,计算的是整个数组的大小,单位是字节。 2.当&数组名,此处的数组名表示的是整个数组,取出的是整个数组的地址(整个数组的地址与数组首元素的地址)),除特殊情况外,遇到的所有数组名都是数组首元素的地址
对于第2种特殊情况,&arr[0] 与 &arr 的数值相同,但两者存在区别
Eg:

Eg:
此处 上文中有 int arr[10];

即&arr 此处arr为数组名, 因此+1是跳过 1*数组类型的长度 即 1* int[10] , 而int[10] 的大小为 4*10
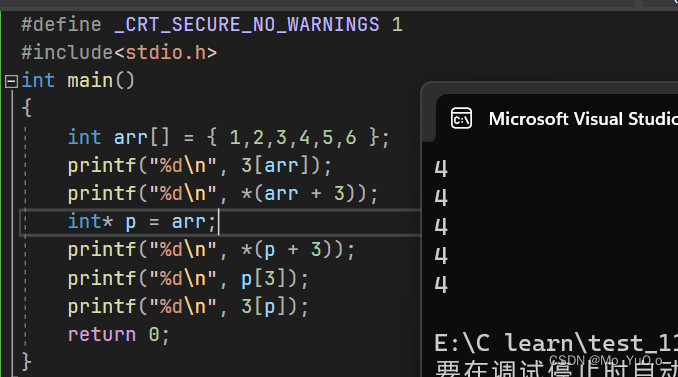
对于数组:int arr[3] = {1,2,3}; 若 int* p =arr; 则 *(p + i) 就相当于 p[i] 相当于 arr[i],,,此处的 [ ] 只是一个操作符 arr[3] 为 *(arr+3) 为 *(3+arr) 为 3[arr]
实质上在内存读取arr数组的时候 , 就是从arr[0]的地址,然后对该地址进行加法运算,读取arr的元素
Eg:

一维数组传参的本质:
形参接收数组名的时候不会创建一个数组,而是接受数组首元素的地址。 本质上就是传了一个指针变量,因此在函数里面用 sizeof(arr)/sizeof(arr[0]) 求的会是1,相当于指针变量的长度/指针变量的长度 int arr[ ] 相当于 int* arr两种写法都可以

有了arr首元素的地址后,我们就可以通过地址来访问arr数组的元素
当数组传参为首元素的地址 的这个过程叫做数组降级 上面这种将arr传入形参就发生了数组降级
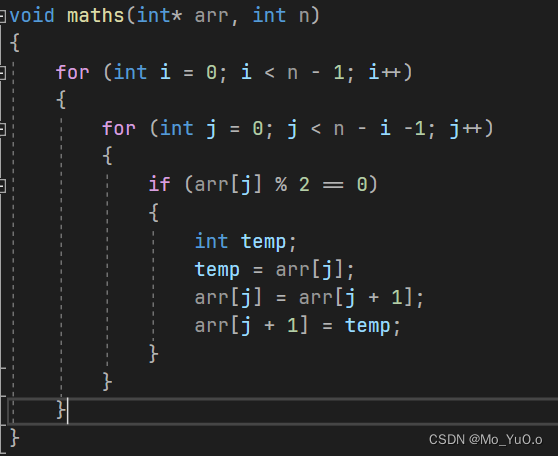
冒泡排序:本质是紧挨着的两个数进行连续比较,然后满足则交换
Eg:int arr[5] = {5,4,3,2,1}; 5>4 则交换 4 5 3 2 1 又5>3 所以 4 3 5 2 1 以此类推,最后结果为 4 3 2 1 5 ,然后我们让 4 3 2 1 进行同理比较 结果为 3 2 1 4后续同理 3 2 1进行比较 结果为: 2 1 3 然后 2 1同理 结果为 1 2 ,,,观察可得我们让 左大于右进行比较,让大的在右边,经过一趟冒泡排序的话,最右边则为最大值,然后除去此时最大的,再进行同理比较,那么4又到最右侧 ,,,然后同理 3又到最右侧 。。。每趟冒泡排序进行完后,下一次的会少一个元素参与,但只省一个的时候就无序再次进行了 【因此对n个元素进行冒泡排序,需要n-1趟】
第一个for循环是冒泡的趟数,第二个for循环的j<n-i-1; 此处的n-i 是每趟冒泡后的元素个数,而最后一个元素不用再和它后面的比较所以此处对n-i 进行 -1
二级指针:格式: 类似于:int** pc = &p;(注意此处为**)[此处的int* 是说&p的类型为int* ,第二个 * 是表示pc为指针变量] 【三级指针(类似于int*** pcc = &pc;此处pc类型为int**)等同理】
存放一级指针变量的地址的指针为二级指针
Eg:int n =20 ; int* p = &n; int** pc = &p; 此处的p为一级指针,pc为二级指针
通过二级指针改变原地址存放的值
Eg: int n =20 ; int* p = &n; int** pc = &p; *(*pc) = 10; printf(“%d”,n); 打印结果为10
指针数组:存放同一类型的指针变量的数组(所以指针数组的每个元素都是指针)
Eg:浮点型指针数组: double* m;
指针数组模拟二维数组: 核心是将其他数组的首元素地址存放进去,然后通过解引用来达到效果 【毕竟二维数组是多个数组的集合】
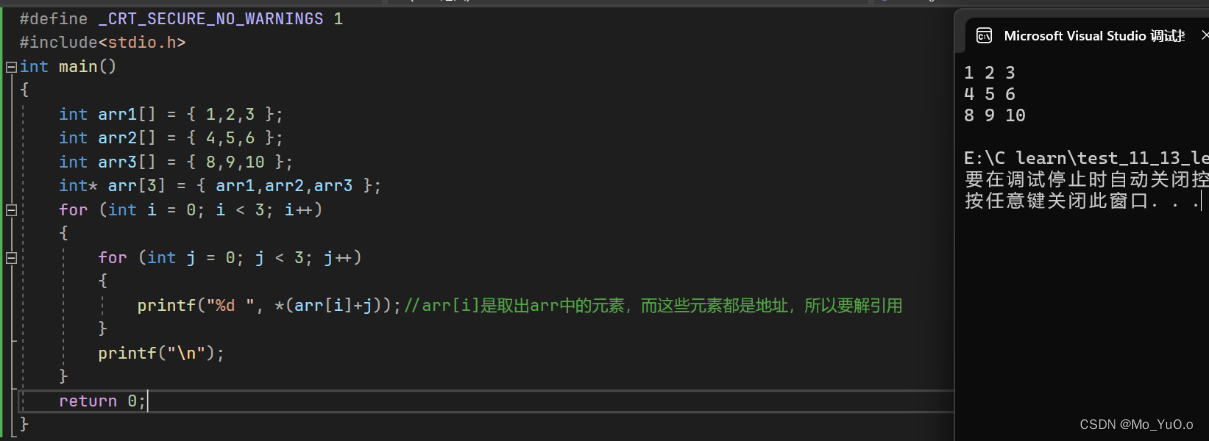
此处的int* 表示 数组arr的元素类型为int* 对于int* arr[3]; arr 先与[3]结合,表示一个数组
字符指针变量:
字符串(常量字符串是不可以修改的,也不能用指针变量解引用来修改):(可以把字符串想象为一个字符数组,,,实际上我们就可以理解为数组,eg: printf(“%c”,”abcdef”[3]) 打印出的就是d) 当常量字符串出现在 表达式中的时候 表达的就是 第一个首字母的地址
【即 “abcde” + 3; 是按照指针+整型的计算法则进行计算,即得数为d的地址 】
Eg: 此处+3,正好是加的数值3的原因是 char类型的长度为 1个字节,所以 3*1 = 3,因此数值上 呈现的效果是加的3
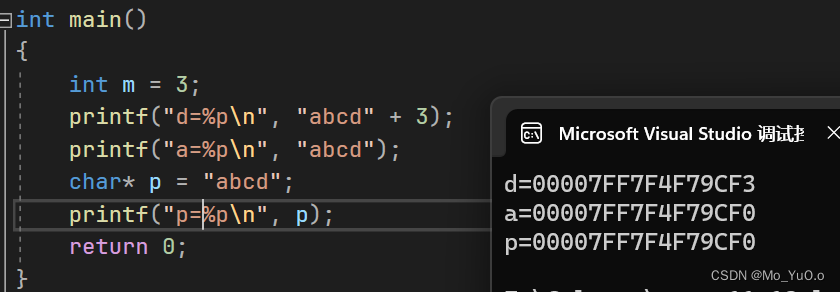
【内容相同的常量字符串只会创建一份空间】
Eg: 除了sizeof() 中单独使用的数值名和&数值名外,其他情况数组名都为数值首元素地址, 因此此处str1 != str2;

对于 char* pc = “abcdef”; 存放的是a地址 , 不是将 abcdef\0 赋值给pc ,[但由于字符串常量无法被修改,因此我们只能通过解引用使用该数组(根据指针变量的使用原则进行),但不能进行修改
数组指针:指向数组的指针 数组指针变量存放的应该是数组的地址
格式为: 指向的数组的元素的类型(*自定义指针变量名)[指向的数组的元素个数] = &数组名; eg: int (*pc) [10] = &arr;(此处的arr为数组) 该数组指针的类型为 int (*) [10] 同时&arr的类型也是int (*) [10] 前后类型一样
对于 int* p1[10]; 是p1先和[10]结合,变为一个数组; 而 int (*p1)[10];是p1先和 * 结合变为 指针变量 p1 , 该指针指向的是长度为10,类型为int的数组

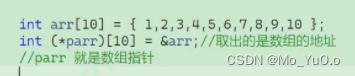
对于此处 解引用 parr的本质是: 因为parr = &arr; 所以 *parr = *(&arr); 即*parr = arr ;
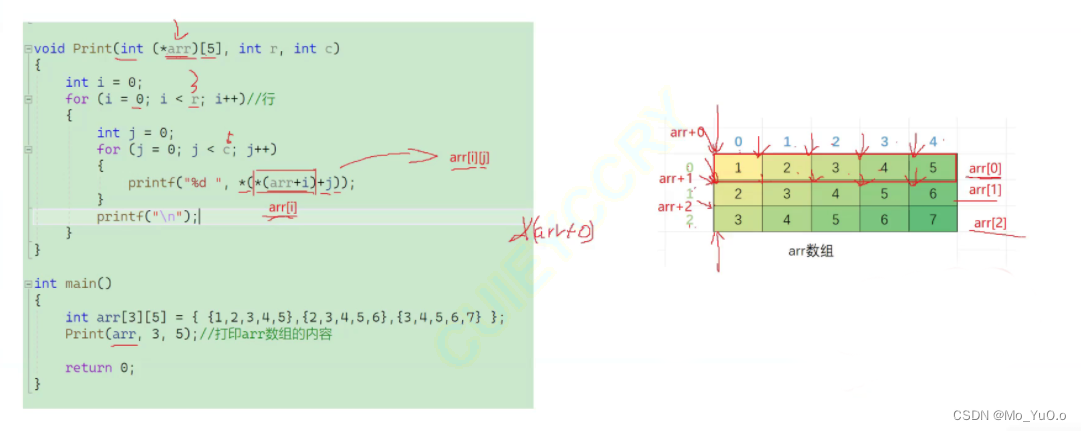
二维数组传参的本质:
二维数组的实参是二维数组。
数组名为首元素的地址。【而二维数组是多个一维数组的集合,每个一维数组是二维数组的元素,因此二维数组的首元素的地址就是该二维数组中第一个一维数组的地址】
因此对二维数组传参,传入的是该二维数组中整个的第一个一维数组。
Eg: 此处为 (*arr)[5] 的 原因是:二维数组传入的整个第一个数组的地址 而数组指针的格式为:指向的数组的元素的类型(*自定义指针变量名)[指向的数组的元素个数] = &数组名; 而此处整个第一个数组的类型为 int (*) [5] 所以此处形参为 int (*arr) [5];
(在上文对于此处 解引用 parr的本质是: 因为parr = &arr; 所以 *parr = *(&arr); 即*parr = arr ;,在此处也是同理,*(arr+i) 是第i个一维数组的首元素的地址 *(*(arr+i)+j) 是第i个一维数组的首元素的地址+j然后解引用【即第i个数组的第j个元素】)
函数指针【函数名为函数的地址,&函数名 也是函数的地址 ,这两者无区别】: 用来存放函数的地址的
格式: 函数的返回类型 (*自定义指针变量名) (形参类型,形参类型) = 函数名 或者 &函数名 例如下图的 int (*pf) (int , int ) = &Add;
Eg:
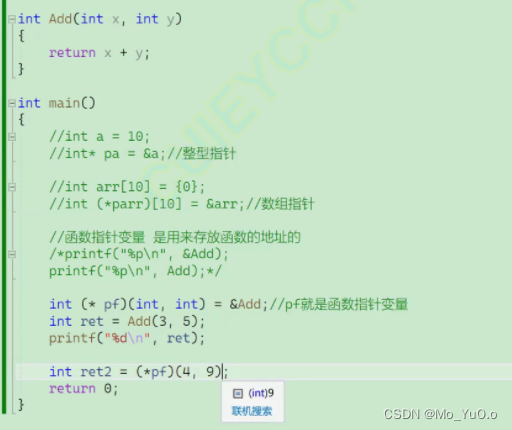
本质上函数调用,就是在函数的地址后面进行传参(然后达到调用的效果),【因此,上图的(*pf)(4,9) 可以不解引用 直接写为 pf(4,9) 也可以,因为指针变量pf中存放的就是函数Add的地址】
如果函数的放回类型为函数指针时,写法应为:int ( * Arr(int , int (*) (int , int ) ) ) ( char* )
这种是 返回类型为 int (*) (char*) 的函数Arr的正确写法
【 当然,我们想写为 int (*) (char*) Arr(int , int(*) ( int , int) ) 但是这种写法在语法上是错误的】
不过我们可以借助Typedef 对类型进行重命名 , 即可实现 将返回值为函数指针类型的函数写的 更容易懂 【要注意重定义 函数指针类型的要求】

Typedef关键字: 对类型的重命名 ,,, 下面代码使 uint 与unsigned int 定义的类型一样
【[数组指针的重命名 是将要重命名的名字放置在*旁边 typedef 数组元素类型 (*重命名)[数组元素个数] (函数指针的重命名同理)】

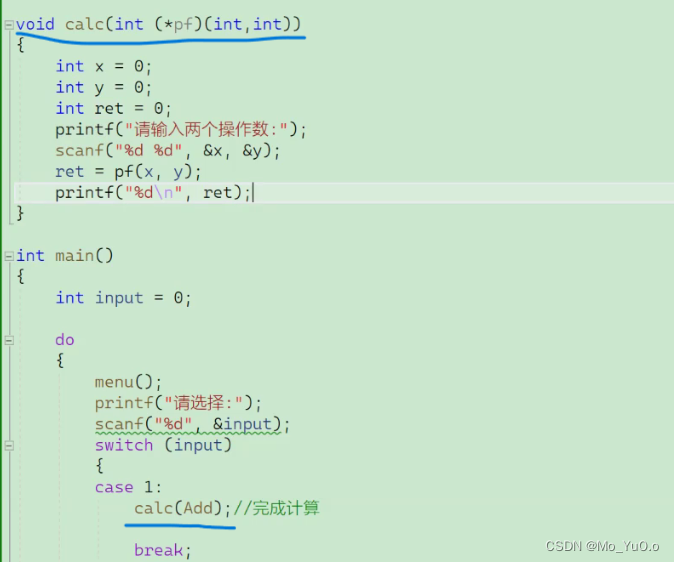
函数指针的用途: 回调函数的概念: 回调函数是通过函数指针进行调用的函数, 我们通过函数指针(即地址)将函数传入另一个函数中,然后在另一个函数里,通过函数指针来调用这个函数,这个被调的函数叫做 回调函数
回调函数 【此处calc 传入的是Add函数的地址,然后在clac 进行传入的函数的运算, 当让因为我们calc 传入的是地址,因此我们也可以传 Sub等函数的地址,然后进行相应的运算(因为我们在calc 中传入的函数指针来调用相应的函数,因此我们传入的函数的地址,会进行相应的运算)】 【注意:我们并没有通过calc 函数来直接调用对应函数,而是通过传入的地址进行 间接调用 相应的函数 ,而此时被调用的函数叫做回调函数】
Typedef关键字: 对类型的重命名 ,,, 下面代码使 uint 与unsigned int 定义的类型一样
【[数组指针的重命名 是将要重命名的名字放置在*旁边 typedef 数组元素类型 (*重命名)[数组元素个数] (函数指针的重命名同理)】

函数指针数组: 格式: 函数返回类型 (* 数组名[ ] ) (形参类型,形参类型) = { 函数名 ,函数名……};
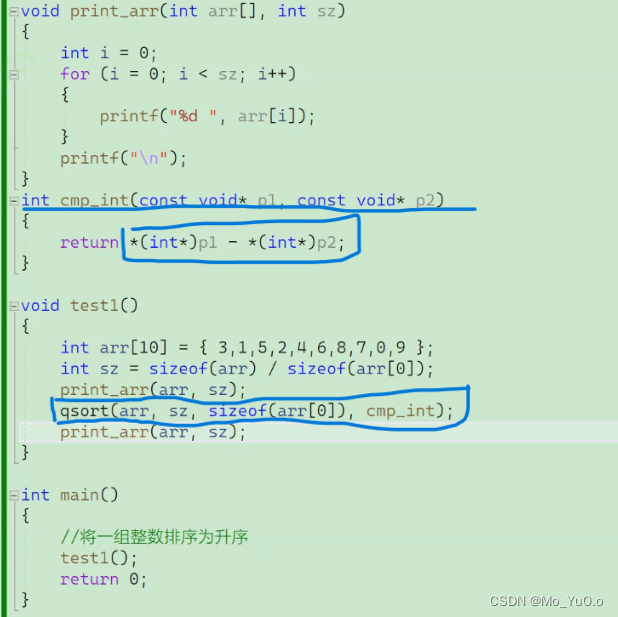
qsort函数:可以对任意数组进行排序 [该函数在头文件 <stdlib.h>]
格式 qsort ( 首元素地址,元素个数 , 首元素大小 , 用来比较的函数的函数指针[即地址](指向的函数为用来比较两个元素(记为m , n)的函数,该函数的形参类型为 const void* , const* void 类型,,,且该函数的返回类型是 当m < n 时返回int 整型负数 , m== n 时返回 int 整型0 , m> n 时返回int 整型正数) )
Eg: 此处的*(int*)p1 - *(int*)p2; 达到了p1>p2时返回 0 , p1 = p2 时返回 正数, p1 < p2 时返回 负数 【此处的cmp_int 内部并没有进行比较,但是我们可以通过调节cmp_int 的返回值来控制是升序还是降序,因为qsort函数会根据此处的cmp_int 的返回值进行比较和交换数值】(默认若p1<p2返回值为 int类型负数 则 qsort函数进行的是升序排序,同理如果我们想让 qsort函数进行降序排序,只需要让p1<p2的返回值为正数即可{即返回 return p2 – p1 ; 即可}) 【qsort的底层是使用快速排序的算法进行排序的】
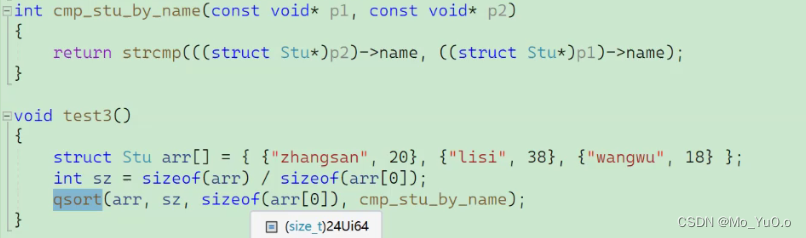
用qsort比较结构体的过程: 第一种:比较年龄(即比较数字)

第二种: 比较名字 (即字符串)
字符串比较大小,是比较的内容,而不是长度,eg: “abcde” 比 “abg” 小,因为c的ASCII码值小于 g的ASCII码值, 当两个字符不同时,则进行比较,结束,不会进行向下比较
Strcmp函数: 用来对两个字符串对应的位置的字符的ASCII码值进行比较的,如果第一个字符串小于第二个字符串则返回int整型负数,如果大于则返回int类型正数 , 如果相等则返回 0 语法: strcmp(const void* p1 , const void* p2); 且函数strcmp函数的返回值为int类型
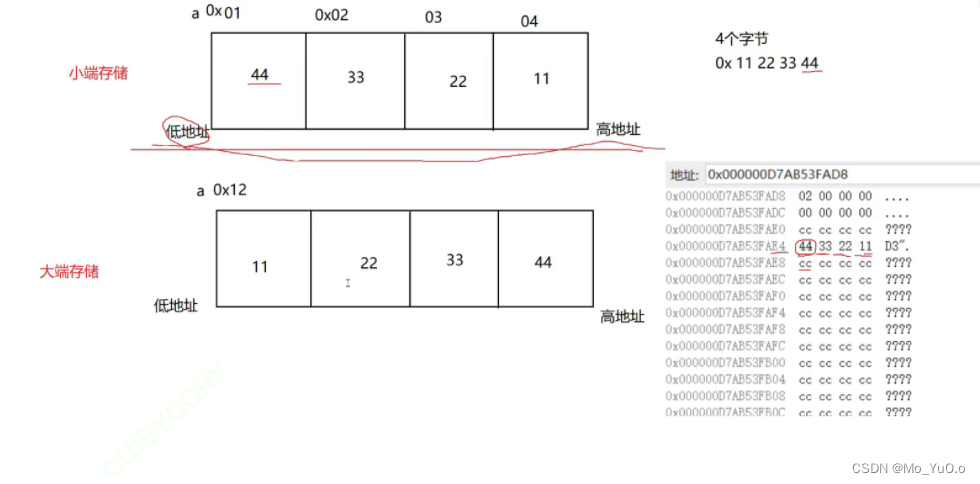
小端存储:从低地址处进行数据存储
大端存储:从高地址处进行数据存储
下图都是表示十六进制 0X 11 23 33 44















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









