







前言
本人作为一名新手,已经学习了一个多月的yolov1,打算通过自己讲解yolo图像处理过程的方式来巩固学习成果,并且发现自己在学习中的不足。希望大家可以给我些学习上的建议,感谢大家的指点。
YOLOV1是2015目标检测算法领域的一项重大突破,这是由以Joseph Redmon为首的大佬们提出的一种新的目标检测算法。在yolov1之前,普遍使用的是RCNN,相较于RCNN的两阶段算法,yolov1是一种单阶段的端到端的算法,它将目标检测问题看作回归问题,他将图片输入网络,获得了获得了图片中包含物体的边界框和分类概率等的信息。
Github源码地址:mirrors / alexeyab / darknet · GitCode
数据集介绍
VOC2012(Visual Object Classes 2012)是PASCAL VOC挑战赛的一部分,是一个广泛使用的计算机视觉数据集。
-
发布年份: 2012年
-
数据类型: 图像数据集
-
主要任务: 图像分类、目标检测、语义分割、实例分割
数据集包含约11,530张图像。这些图像涵盖了20个不同的对象类别,包括人、动物、交通工具等。每张图像都被标注为包含或不包含某个类别的对象。每个对象实例都被标注了边界框(bounding box)。每个像素都被标注为属于某个对象类别或背景。 每个对象实例的像素都被单独标注。
SegmentationObject和SegmentationClass主要包含的是用于图像分割的数据
JPEGImages存储的是数据集的图片数据(.img),每一张图片所对应的名称如图

Imagesets存储了Action、Layout、Main、Segmentation四个文件夹,分别对应部分的相关信息,在我们目标检测的任务中,只需关注一下Main文件夹下的内容即可。

如图为Main文件夹下的部分内容,主要包含我们所需要检测的物体的在每一张的图片中是否存在。1表示存在,-1表不存在。
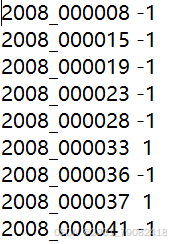
如图,为aeroplane_train文档的部份内容,表示在训练数据集内的2008_000008的图片中不存在飞机,在2008_000033中存在飞机。
如图,在Annotation文件夹中主要包含了图片的注释文件(.xml),该文件主要介绍了每张图片的信息,包括尺寸、人工标注的边界框的信息、数据的来源等等。

name:目标名称
pose:面对摄像头的部位。Unspecified表示未识别
truncated:表示该物体是否被图像的边缘所截断,0表示未被截断,1表示被截断
difficult:表示识别该物体的难度
bndbox:表示人工所标注的外接矩形的坐标信息
网络的介绍
原论文所使用的网络为Googlenet网络,本文所使用的网络为Resnet34网络,其有缺点如下:
-
GoogleNet:
-
GoogleNet通过Inception模块实现了深而宽的结构,能够捕捉多尺度的特征。
-
在YOLOv1中使用GoogleNet作为特征提取器,可能会提高网络的表达能力,尤其是在处理多尺度目标时。
-
然而,GoogleNet的计算量较大,可能会影响实时性能。
-
-
ResNet:
-
ResNet通过残差块的设计,可以构建非常深的网络,同时保持较高的训练效率和性能。
-
在YOLOv1中使用ResNet作为特征提取器,可能会提高网络的深度和精度,同时减少梯度消失的问题。
-
ResNet的计算量相对较小,可能会更适合实时目标检测任务。
-
def __init__(self):
super(MyNet, self).__init__()
resnet = tvmodel.resnet34(pretrained=True)
resnet_out_channel = resnet.fc.in_features
self.resnet = nn.Sequential(*list(resnet.children())[:-2])
self.Conv_layers = nn.Sequential(
nn.Conv2d(resnet_out_channel, 1024, 3, padding=1),
# 通道数为 resnet_out_channel 的特征图转换为输出通道数为 1024 的特征图,卷积核 大小为 3x3,填充(padding)为 1。
nn.BatchNorm2d(1024), # 为了加快训练,这里增加了BN层,原论文里YOLOv1是没有的
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, stride=2, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(inplace=True),
)
self.Conn_layers = nn.Sequential(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









