







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
slowlog-max-len 它决定 slowlog 最多能保存多少条日志,当发现redis性能下降的时候可以查看下是哪些命令导致的。
二、管道测试
redis的管道功能在命令行中没有,但是redis是支持管道的,在java的客户端(jedis)中是可以使用的:

示例代码:
//注:具体耗时,和自身电脑有关(博主是在虚拟机中运行的数据)
/**
-
不使用管道初始化1W条数据
-
耗时:3079毫秒
-
@throws Exception
*/
@Test
public void NOTUsePipeline() throws Exception {
Jedis jedis = JedisUtil.getJedis();
long start_time = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
jedis.set(“aa_”+i, i+“”);
}
System.out.println(System.currentTimeMillis()-start_time);
}
/**
-
使用管道初始化1W条数据
-
耗时:255毫秒
-
@throws Exception
*/
@Test
public void usePipeline() throws Exception {
Jedis jedis = JedisUtil.getJedis();
long start_time = System.currentTimeMillis();
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < 10000; i++) {
pipelined.set(“cc_”+i, i+“”);
}
pipelined.sync();//执行管道中的命令
System.out.println(System.currentTimeMillis()-start_time);
}
hash的应用
示例:我们要存储一个用户信息对象数据,包含以下信息: key为用户ID,value为用户对象(姓名,年龄,生日等)如果用普通的key/value结构来存储,主要有以下2种存储方式:
1、将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储 缺点:增加了序列化/反序列化的开销,引入复杂适应系统(Complex adaptive system)修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护。
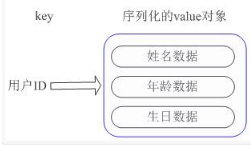
2、用户信息对象有多少成员就存成多少个key-value对 虽然省去了序列化开销和并发问题,但是用户ID为重复存储。
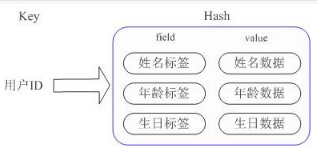
Redis提供的Hash很好的解决了这个问题,提供了直接存取这个Map成员的接口。Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值。( 内部实现:Redis Hashd的Value内部有2种不同实现,Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht )。
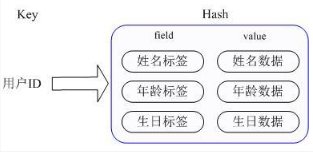
Instagram内存优化
Instagram可能大家都已熟悉,当前火热的拍照App,月活跃用户3亿。四年前Instagram所存图片3亿多时需要解决一个问题:想知道每一张照片的作者是谁(通过图片ID反查用户UID),并且要求查询速度要相当的块,如果把它放到内存中使用String结构做key-value:
HSET “mediabucket:1155” “1155315” “939”
HGET “mediabucket:1155” “1155315”
“939”
测试:1百万数据会用掉70MB内存,3亿张照片就会用掉21GB的内存。当时(四年前)最好是一台EC2的 high-memory 机型就能存储(17GB或者34GB的,68GB的太浪费了),想把它放到16G机型中还是不行的。
Instagram的开发者向Redis的开发者之一Pieter Noordhuis询问优化方案,得到的回复是使用Hash结构。具体的做法就是将数据分段,每一段使用一个Hash结构存储. 由于Hash结构会在单个Hash元素在不足一定数量时进行压缩存储,所以可以大量节约内存。这一点在上面的String结构里是不存在的。而这个一定数量是由配置文件中的hash-zipmap-max-entries参数来控制的。经过实验,将hash-zipmap-max-entries设置为1000时,性能比较好,超过1000后HSET命令就会导致CPU消耗变得非常大。
HSET “mediabucket:1155” “1155315” “939”
HGET “mediabucket:1155” “1155315”
“939”
测试:1百万消耗16MB的内存。总内存使用也降到了5GB。当然我们还可以优化,去掉mediabucket:key长度减少了12个字节。
HSET “1155” “315” “939”
HGET “1155” “315”
“939”
三、优化案例
1、修改linux中TCP监听的最大容纳数量
/proc/sys/net/core/somaxconn is set to the lower value of 128.
在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核默默地将这个值减小到/proc/sys/net/core/somaxconn的值,所以需要确认增大somaxconn和tcp_max_syn_backlog两个值来达到想要的效果。 echo 511 > /proc/sys/net/core/somaxconn 注意:这个参数并不是限制redis的最大链接数。如果想限制redis的最大连接数需要修改maxclients,默认最大连接数为10000
2、修改linux内核内存分配策略
错误日志:WARNING overcommit_memory is set to 0! Background save may fail under low memory condition.
To fix this issue add ‘vm.overcommit_memory = 1’ to /etc/sysctl.conf and then reboot or
run the command 'sysctl vm.overcommit_memory=1
redis在备份数据的时候,会fork出一个子进程,理论上child进程所占用的内存和parent是一样的,比如parent占用的内存为8G,这个时候也要同样分配8G的内存给child,如果内存无法负担,往往会造成redis服务器的down机或者IO负载过高,效率下降。所以内存分配策略应该设置为 1(表示内核允许分配所有的物理内存,而不管当前的内存状态如何)。 内存分配策略有三种 可选值:0、1、2。 0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。 1, 不管需要多少内存,都允许申请。 2, 只允许分配物理内存和交换内存的大小(交换内存一般是物理内存的一半)。
3、关闭Transparent Huge Pages(THP)
THP会造成内存锁影响redis性能,建议关闭
Transparent HugePages :用来提高内存管理的性能
Transparent Huge Pages在32位的RHEL 6中是不支持的
执行命令 echo never > /sys/kernel/mm/transparent_hugepage/enabled
把这条命令添加到这个文件中/etc/rc.local
我看过不少的关于redis的学籍,以及一些学习笔记,虽然都还不错,但是能够从浅深入到源码的却很少,前几天看到的一份来阿里大牛自产的“Redis深度笔记”,起码是我目前看到过的最完善,最有深度的一份笔记了。有需要可以点击文末名片免费领取,无套路。

笔记大概分为以下几个部分:
-
开篇基础部分
-
九大应用部分
-
八大原理部分
-
三大集群部分
-
九大拓展部分
-
七大源码部分
一、开篇基础部分
-
开篇:授人以鱼不若授人以鱼-Redis可以用来做什么
-
基础:万丈高楼平地起-Redis基础数据结构

二、九大应用部分
-
千帆竞发-分布式锁
-
缓兵之计-延时队列
-
节衣缩食-位图
-
四两拨千斤-HyperLogLog
-
层峦叠嶂-布隆过滤器
-
断尾求生-简单限流
-
一毛不拔-漏斗限流
-
近水楼台-GeoHash
-
大海捞针-Scan

三、八大原理部分
-
鞭辟入里-线程IO模型
-
交头接耳-通信协议
-
未雨绸缪-持久化
-
雷厉风行-管道
-
同舟共济-事务
-
小道消息-PubSub
-
开源节流-小对象压缩
-
有备无患-主从同步

四、三大集群部分
-
李代桃僵-Sentinel
-
分而治之-Codis
-
众志成城-Cluster
最后
手绘了下图所示的kafka知识大纲流程图(xmind文件不能上传,导出图片展现),但都可提供源文件给每位爱学习的朋友

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-Cluster
最后
手绘了下图所示的kafka知识大纲流程图(xmind文件不能上传,导出图片展现),但都可提供源文件给每位爱学习的朋友
[外链图片转存中…(img-8HEcupbT-1713614678781)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-ZsoIHkXS-1713614678781)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









