









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
测试免密登录是否配置成功
测试成功之后,exit回到ljl节点
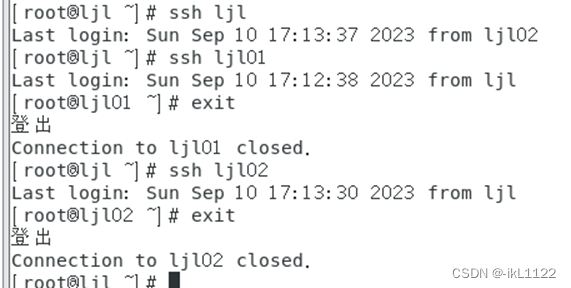
5.配置环境变量
在上一节,jdk和hadoop的环境变量都以配置好

6.配置hadoop-env.sh文件及其他重要文件
首先进入hadoop所在配置文件目录/usr/local/src/Hadoop-3.3.6/etc/hadoop,在此目录打开终端。
vim Hadoop-env.sh
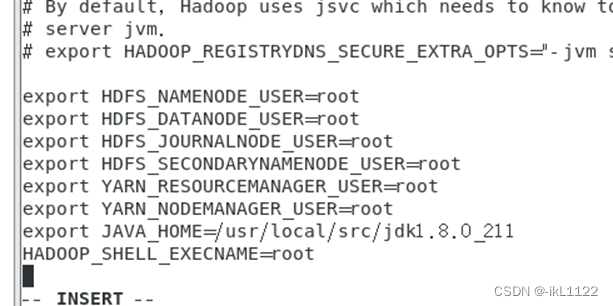
修改core-site.xml, vim core-site.xml
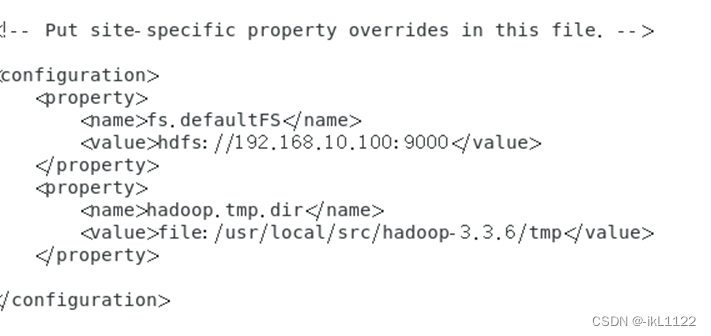
修改hdfs-site.xml文件
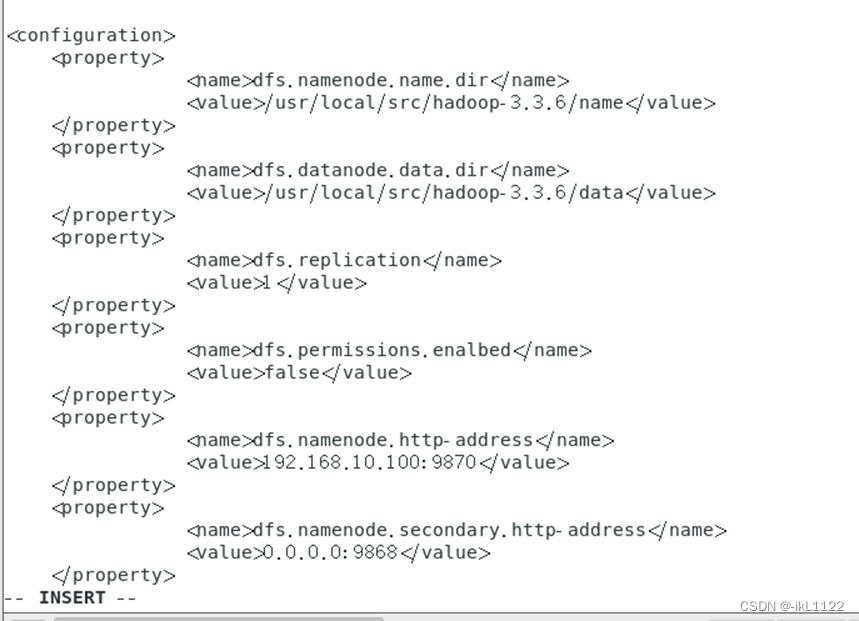
修改yarn-site.xml文件

修改mapred-site.xml文件

修改workers

7.分发文件
cd /usr/local/src# 分发jdk,$PWD:获取当前所在目录的绝对路径 scp -r jdk1.8.0_211 root@ljl01:$PWD scp -r jdk1.8.0_211 root@ljl02:$PWD # 分发hadoop scp -r hadoop-3.3.6 root@ljl01:$PWD scp -r hadoop-3.3.6 root@ljl02:$PWD # 分发/etc/hosts scp /etc/hosts root@ ljl01:/etc/ scp /etc/hosts root@ ljl02:/etc/ # 分发/etc/profile scp /etc/profile root@ ljl01:/etc/ scp /etc/profile root@ ljl02:/etc/

然后在两个从节点上执行 source /etc/profile

8.启动hadoop集群并测试
启动hdfs
start-dfs.sh
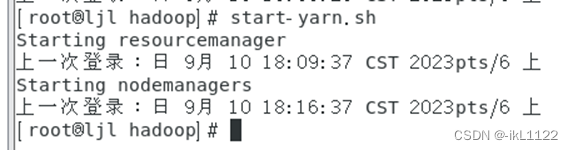
启动yarn
start-yarn.sh
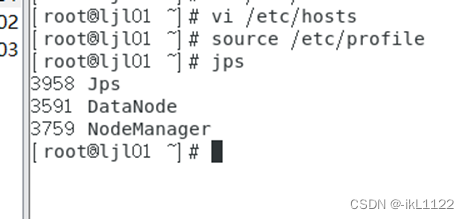
jps 分别查看三个节点的进程



9.访问web界面
主节点的地址+端口号(如:192.168.10.100:9870)
10.运行官方案例
统计每个单词出现的频率
vi words.txt 然后添加如下内容
hadoop hdfs hdfs Hadoop mapreduce mapreduce Hadoop hdfs Hadoop yarn yarn



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
5437586762)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









