






案例一单例模式
只有一个对象,只实例化一个对象
饿汉模式
在程序开始初期的实例化一个对象

static成员初始化时机是在类加载的时候,static修饰的instance只有唯一一个,初始化也是只执行一次,static修饰的是类属性,就是在类对象上的,每个类对象在JVM中只有一份,里面的静态成员也是只有一份
后续想要获得instance,就可以调用getInstance来获得已经new好的这个对象,就不需要重新new
懒汉模式
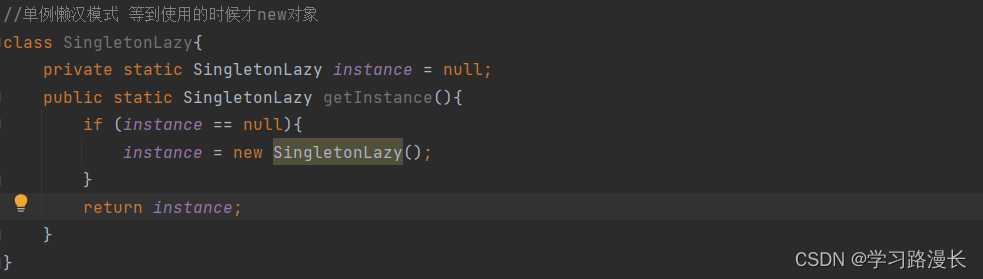
不是在程序启动的时候创建实例,而是在第一次使用的时候才去创建
核心单例模式
万一,其他代码想new一个这个类的实例怎么办,我们要禁止其他的代码new这个类的实例,只需将构造方法前面加private即可,因为其他代码想实例化一个对象,势必需要调用构造方法,那么这个构造方法是私有的,只能在SingleTon这个类中调用构造方法,在其他代码中调用这个构造方法势必会编译错误


s1和s2都是调用类里面的静态方法,将instance这个对象返回给s1,s2,所有他们所指向的对象都是一样的,打印s1一定等于s2
关于懒汉和饿汉的线程安全问题
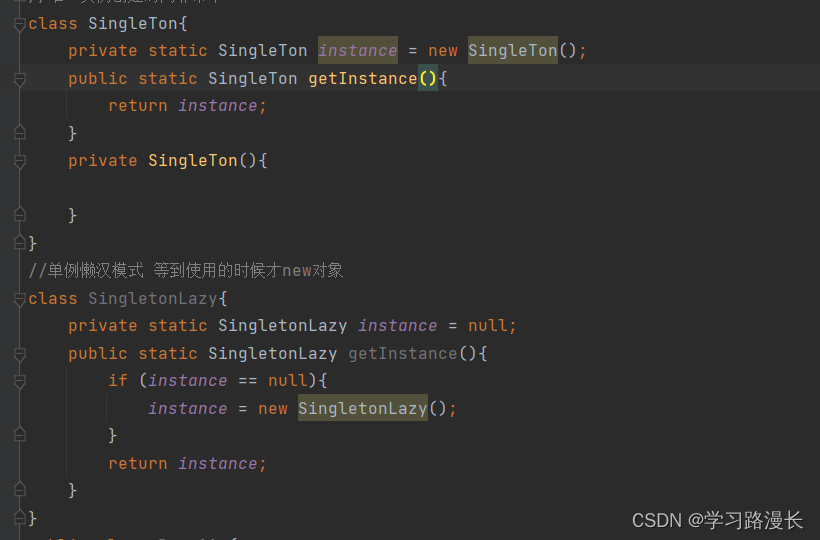
结合代码来看,首先懒汉模式是线程不安全的,而饿汉模式是线程安全的,因为在Java程序刚开始运行的时候instance对象就被创建好,多线程中饿汉模式只是读取了instance的值,并没有修改,多个线程读取同一变量的值是不会引起线程安全问题的
懒汉模式线程不安全的原因
相反懒汉模式则会引起线程不安全,因为懒汉模式是在有需要的时候才会去实例化对象,在多线程编程中懒汉模式要进行读和写操作,这一修改变量的值不是原子的,所有会造成线程不安全的问题,因此我们要使用synchronized对读和写操作进行加锁,打包成一个原子的操作,加锁会影响性能的问题,如果是第一次判断instance是否为空则需要加锁,若后续第二次...等,每次加锁都势必会影响性能问题,因此我们可以考虑在加一个if判断
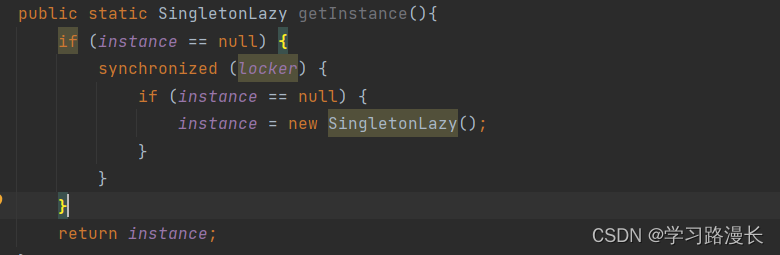
双重if判断含义不同,第一层if判断是判断是否需要加锁,在实例化之后instance有了自己的值就无需加锁,在实例化之前就需要加锁,假如有t1和t2两个线程并发执行上述代码,第一次执行第一个if由于instance的值为null,所有两个线程的if判断都为真进入if语句内,此时遇到synchronized,这个两个线程都是同一个锁对象,假设t1线程先获取到锁,此时t2进入阻塞等待,t1执行第二个if判断,instance为null判断为真,则new一个对象赋值给instance,此时instance有了自己的值不再为空,锁的代码块解锁,t1线程释放锁,t2线程获取到锁,进行if判断,此时instance有了自己的地址不在为空,所以这个判断为假,不在实例化对象,所以这样就做到了只实例化一个对象达成了目的,当第二次执行上述代码时,由于instance不为null,所以直接return instance的值,这样我们就是读取了这个变量的值并没有进行修改操作,从而线程安全
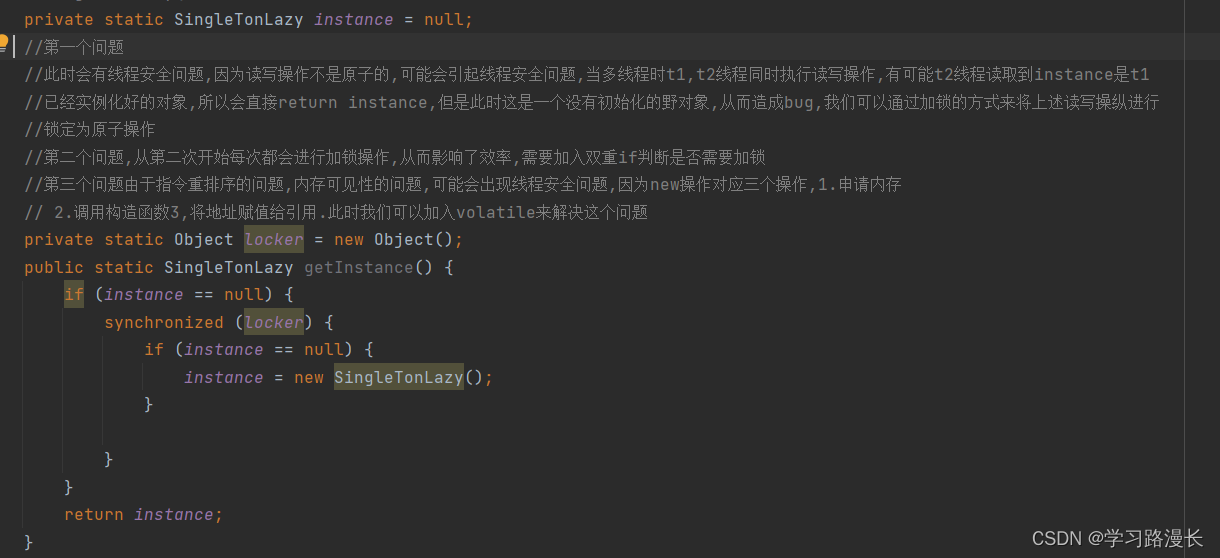
还有一个需要考虑的问题那就是内存可见性的问题,那就是编译器会优化代码,把instance的值存到寄存器当中,每次从寄存器读取instance的值,从而使每次instance的值都为null,这就会使我们的new对象操作变得无意义,为了防止这个问题,我们也可以在instance加入volatile修饰,防止它被编译器优化掉.
面试考
![]()
这一个new操作对应三个操作1.申请内存,2.调用构造函数3.把地址赋值给引用,
延伸(了解即可)
案例二:阻塞等待
之前所学的队列是最基础的队列,在实际开发中还有许多变种队列
1.队列,先进先出
2.优先级队列,具有优先级的先出去.
3.BlockingQueue(标准库提供)阻塞队列,先进先出,线程安全,具有阻塞功能,阻塞(1.当队列为空的时候,尝试出队列,出队列操作会阻塞,一直阻塞到队列不为空的时候,2.当队列满的时候,尝试入队列,入队列操作就会阻塞,一直阻塞到队列不为满时,)
4.消息队列,不是普通的先进先出,而是通过topic这样的参数来对数据进行归类,出队列的时候,指定topic,每个topic下的数据先进先出,也具有阻塞特性
消息队列的作用:实现生产者消费者模型
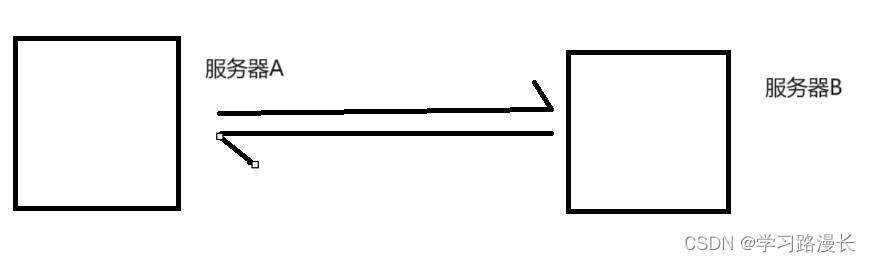
如图所示,上述A与B直接进行调用,意味这A中有关于包含B的逻辑,B中包含有关于A的逻辑,此时彼此之间产生了一定的耦合,当对A进行修改时,会影响到B,如果修改B一定会影响到A,
当我们引入消息队列之后实现生产者消费者模型的好处
1.能够使程序解耦合:,使程序之间的关联性不大
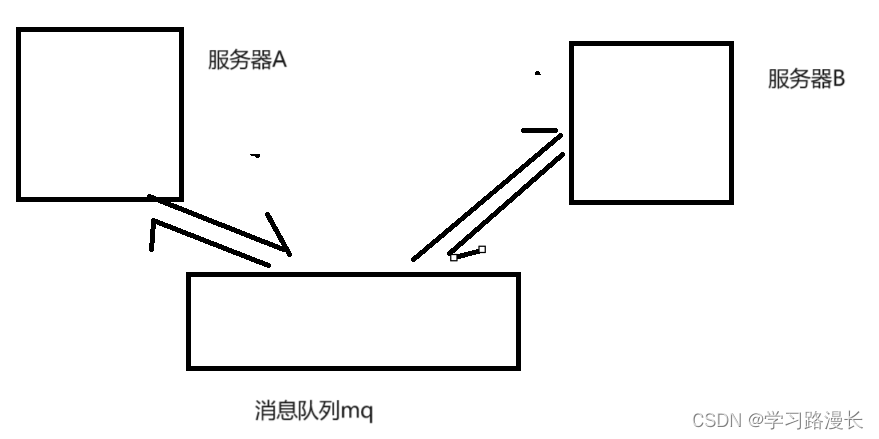
服务器A之间与消息队列mq进行交互,并不知道服务器B的存在,服务器B之间与消息队列mq进行交互,并不知道服务器A的存在,服务器A,B只关心与队列的交互,此时对A修改势必影响不到B,如果服务器A挂了,也不会影响到B,此时如果以后需要引入服务器C,直接让服务器C在队列里面读取数据即可,不需要对服务器A进行修改.
2.削峰填谷:
客户端发来的请求,个数多少是未知的,没办法提前预知,遇到特殊情况,就可能导致客户端给服务器的请求激增
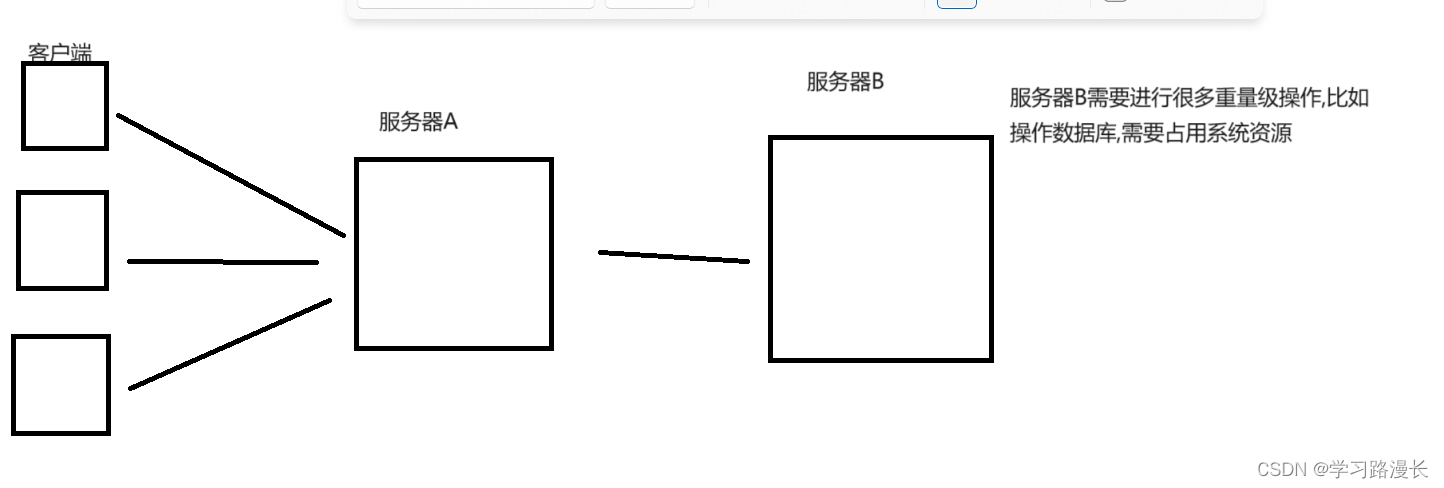
正常情况下A收到一个客户端请求,就需要请求一次B,请求激增的话,由于A的工作比较简单,消耗的资源少,但是B的工作复杂,占用的资源多,就容易挂(服务器每处理一个请求,就需要消耗一定的系统资源,同一时刻处理太多的请求,消耗的总资源超过了机器提供的,则就会卡死)
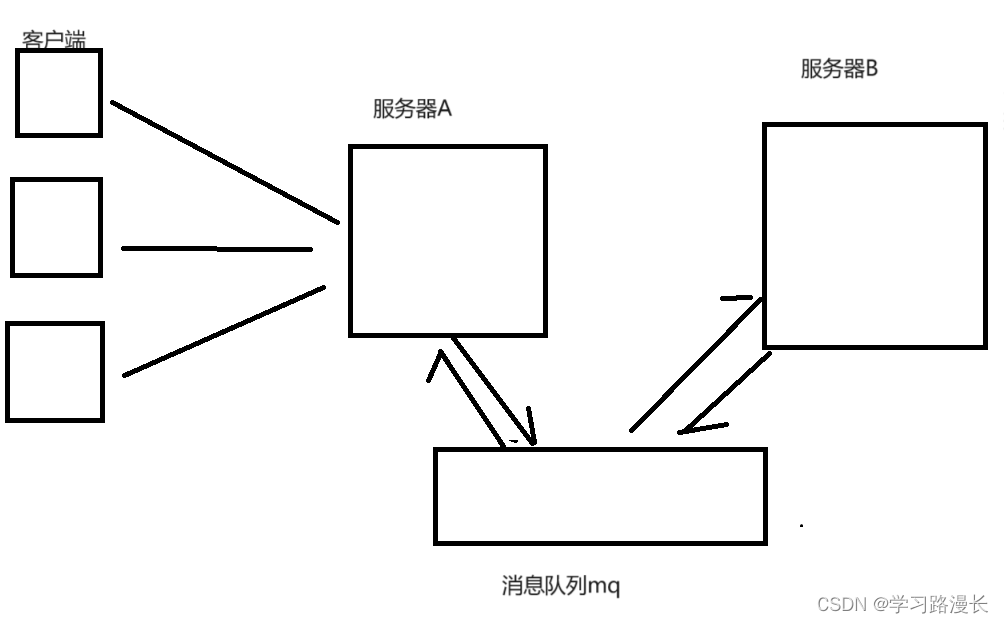
此时我们引入消息队列mq,无论A的请求有多少,都不会影响B,他们通过消息队列进行交互,有了消息队列mq,此时无论A写的有多快,B都可以按照固定的节奏来消费数据,B的节奏就不会跟着A,相当于mq给服务器B的保护起来
缺点:
最大的缺点就是效率,多了一次访问,和网络通信,效率折损,不适合响应速度特别高的场景
通过代码实现阻塞队列以及消费者生产者模型
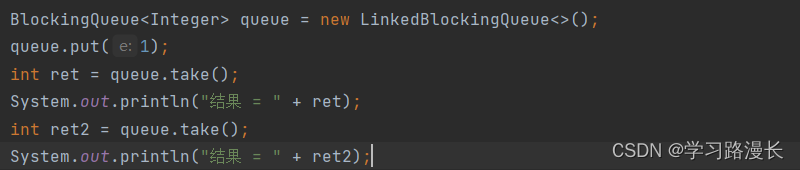
阻塞队列
Blocking是一个接口,不能直接通过new来实例化对象,我们需要new实现这个接口的类

![]()
上述这三个类是实现Blocking接口的类,
阻塞队列常用的方法put()和take(),这两个方法具有阻塞特性
![]()
![]()
使用put会抛出Interrupted异常,因为put会引起阻塞,阻塞过程中其他线程尝试终止put,此时put会抛出异常
消费者生产者模型
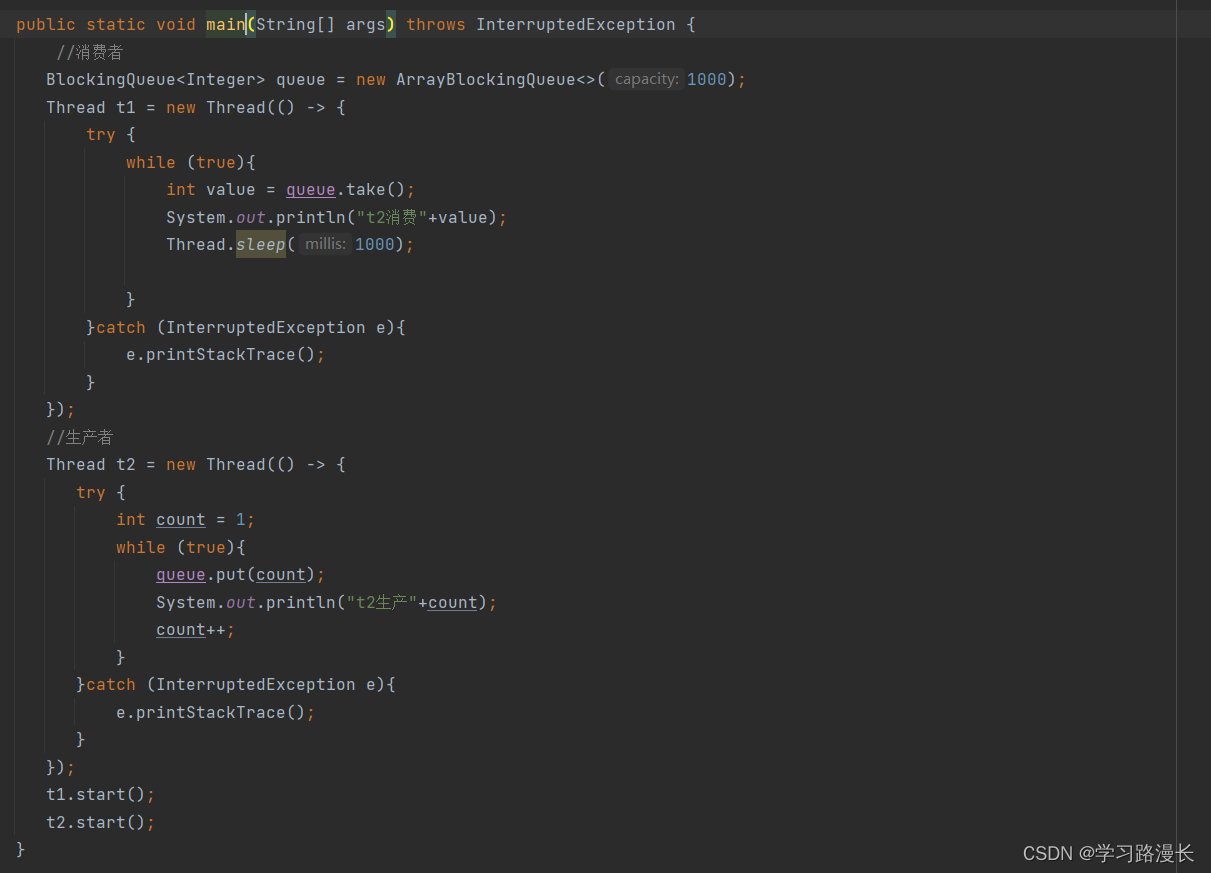
自主实现阻塞队列
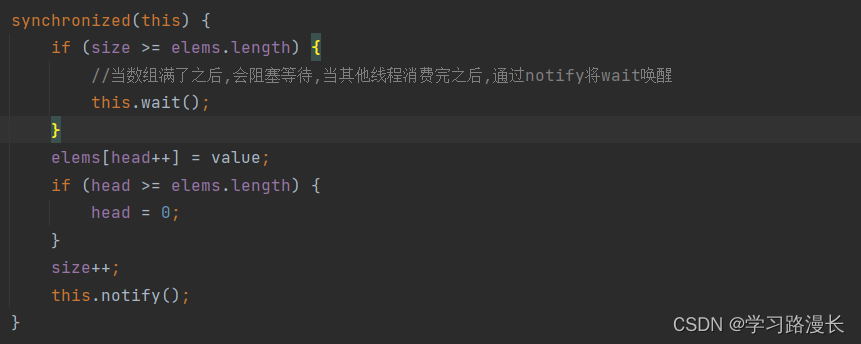
if存在的问题,如果将wait唤醒之后,他会继续向下执行下面的逻辑,不会在进行判断,如果此时数组满了,则它会将之前的值给覆盖掉,不安全,所以保险起见应该用while来代替if,这样就能在wait醒来之后,在进行一次判断看是否符合条件.
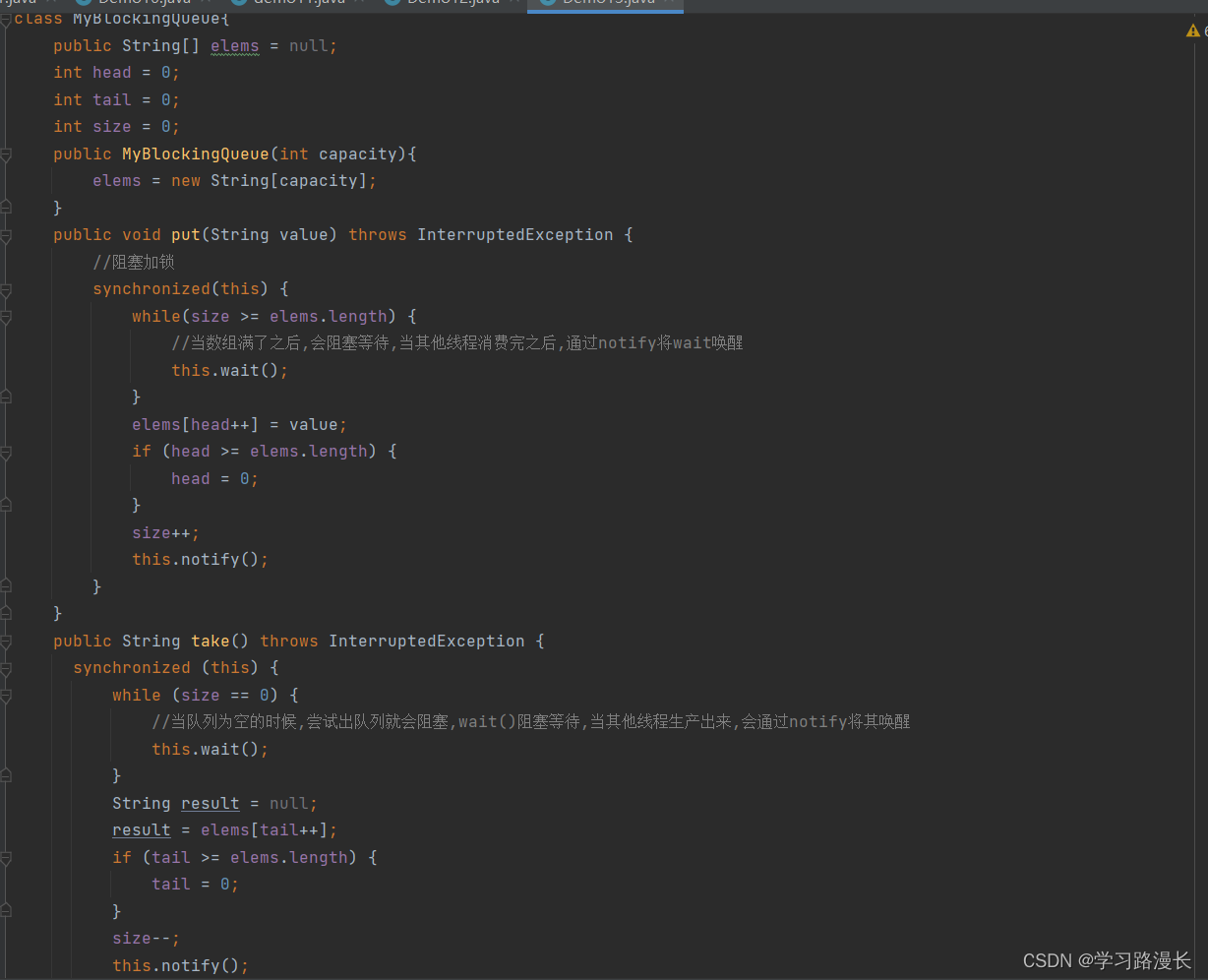
案例三:线程池
池就是为了提高效率存在,包括常量池,线程池,进程池,内存池数据库,连接池,把需要用到的资源提前准备好,放入到池子里面
并发编程使用多进程,就可以了,由于线程比经常更轻量,频繁的创建和销毁,更有优势,随着时代的发展1s内服务器处理的请求变得越来越多,所以线程频繁的创建和销毁的开销也变得越来越明显,
如何优化?
1)线程池
2)协程(纤程)
为什么引入线程池
创建线程/销毁线程,是用户态和内核态配合完成的工作,
线程池/协程,创建销毁只需要用户态不需要内核态,
调用系统api,来进行创建/销毁线程这个过程需要内核,内核完成的工作属于是不可控的,
如果使用线程池,提前把线程创建好,放在用户态代码完成的数据结构当中,后面用的时候直接从里面取,不用的时候再放回池子里去,这个过程完全是用户态代码,就不用与内核进行交互
协程本质上也是纯用户态的操作,规避内核操作,不是在内核里把线程提前创建好,而是利用内核的一个线程来表示多个线程(纯用户态,进行协程之间的调度)
线程池
在Java标准库中的ThreadPoolExecutor,这个类使用起来特别复杂,因为在构造方法中有特别多的参数,我们需要了解到各个参数的含义,面试中会考
Java文档中,在util>concurrent
![]()

参数最多的构造方法,我们来了解一下这七个参数
第一个参数corePoolSize核心线程数
第二个参数maximumPoolSize最大线程数(核心线程+非核心线程)
第三个参数keepAliveTime非核心线程允许空闲的最大时间
第四个参数unit是停留的时间(s,day,mintue)枚举类型

第五个参数workQueue线程池的任务队列,线程池会提供submit方法,让其他的线程把任务提供给线程池,线程池内部需要这样一个队列的数据结构,把要执行的任务保存起来,后续线程池内部的工作线程就会消耗这个队列,从而完成具体的任务,执行Runnable里面的run方法
第六个参数threadFactor,标准库提供的创建线程的工厂,这个线程工厂,主要就是为了批量的给要创建的线程设置一些属性啥的,线程工厂,在工厂方法中,把线程的属性提前初始化好了,主要搭配线程池来用
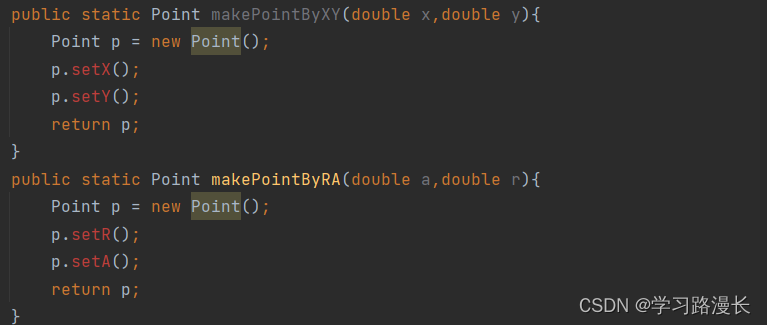
工厂设计模式,其实也是一种设计模式,解决构成方法创建对象太坑了的问题,实例化对象时,使用构造方法,但是由于构造方法必须与类名相同,所有我们只能通过重载来实现不同的构造方法,然后这样就会有局限性例如
class Point{
}
public Point(double x, double y)(笛卡尔坐标系)
public Point(double r, double α)(极坐标系)
上述这个构造方法实例化对象的例子是会编译报错的,因为上述方法没有构成重载
我们可以通过静态方法包装一下构造方法成一个静态方法,工厂模式代码,规避了上述构造方法不能重载的问题,这个方法就是工厂方法,这样写代码的套路就是工厂模式
第七个参数最重要的参数handler
handle不是句柄的意思,句柄是一个资源标识,这里的handle是拒绝策略,这个其实是一个枚举类型,
如果当前任务队列满了,采用什么拒绝策略呢?在标准库中提供了四种方法,下面这张图就是
![]()
四种策略
第一种方法AbortPolicy直接抛出异常(任务处理不过来)
第二种方法CallerRunsPolicy由调用者负责执行,如果队列满了&&调用了submit入队列,那么调用者就自己执行Runable的run方法
第三种方法DiscardOldestPolicy,丢掉最老的任务,让新的任务去队列种排队
第四种方法DiscardPolicy,丢掉最新的任务,按照原来的节奏执行
标准库线程池中设定是这样的,把线程分成两类1.核心线程(corePoolSize),2.非核心线程,
这里面就涉及到动态扩展,一个线程池刚被创建出来的时候,里面就包含核心线程数这么多的线程,在刚开始任务比较少的时候,这这几个核心线程数就够用,线程池中提供了一个方法submit(),可以添加任务,每个任务都是一个RUNNABLE,如果任务太多了,这四个线程不够了就会自动创建新的线程,来支持更多的任务
在线程池中,创建的线程不能超过最大线程数,如果现在的任务不是很重,那么可以把非核心线程数回收,线程池中线程数目必须不少于核心线程数,线程池是用来降低创建销毁线程的频次的,而不是不完全销毁线程
非核心线程要在线程池不忙的时候回收掉,而不是立即回收,例如停留时间3s内没有任务可以做,就可以被回收了
在实际开发中线程个数设置多少合适?
根据实验的方式来进行找到一个合适的值,对程序进行性能测试,最终根据实际的响应速度跟系统开销找到最合适的值.
根据程序的特点来进行设置极端一点可以分为两大类
1.CPU密集型,代码逻辑都需要通过CPU来进行干活,线程数目不应该超过CPU逻辑核心数
2.IO密集型,代码大部分时间在等待IO操作,不消耗CPU不参与调度,瓶颈不在CPU,更多考虑的是网络带宽

由于标准库也知道ThreadPollExecuter使用起来费劲,所有自己提供了一个工厂类方法Exceutors,下面是线程池提供的工厂方法

常用的包装类

自己实现一个线程池
线程池包括1.若干个线程,2.任务队列,3.submit方法
案例四:定时器

定时器在Java标准库中定义的类是Timer,定时器顾名思义就如同生活中的闹钟一样,比如下午2点去上班,我们一点睡觉,则我们可以定一个闹钟去定时一个小时,以后去执行上班任务,在代码中也是,Timer提供了一个schedule方法,我们可以添加一定时间以后需要执行任务,通过重写run方法来实现.
模拟定时器功能
需要定义一个类,用来执行任务基于Runnable的run方法实现,定义一个成员变量runnable调用run方法来实现任务,还有一个变量time这个是用来记录任务执行的决定时间的,实现比较器接口,从而保证这个优先级队列是小根堆

还需要一个数据结构来保存上述任务,


上述数据结构是优先级队列,为什么不使用阻塞队列,因为如果使用阻塞队列就得再加一把锁,同时有两把锁可能会造成死锁的问题,所以我们自己手动设定一把锁是最好的选择,在这个类里面,有一个schedule方法是增加任务到这个优先级队列当中,我们这个构造方法是用来扫描队列中的每个任务是否到达了指定时间,如果队列元素为空的时候和没到执行任务的时候,这个线程就会wait,不去占用cpu的资源,当有新的任务进来就会立即开始工作,用notify进行唤醒,而用sleep的话,就是彻底睡眠,有新任务进来也会在睡眠,使用interrupt唤醒是非常规手段,所以使用wait,由于这两个线程同时对队列进行修改操作,可能会造成线程不安全,所以需要加锁















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









