






什么是布隆过滤器
布隆过滤是由一个二进制数组和一系列随机映射函数,可以检索一个元素是否存在一个集合中,空间效率和时间效率上都比一般的算法要好,但是有一定误判的情况和删除困难.
二进制数组 数据结构仅需要存储“0”或“1”占用内存极少
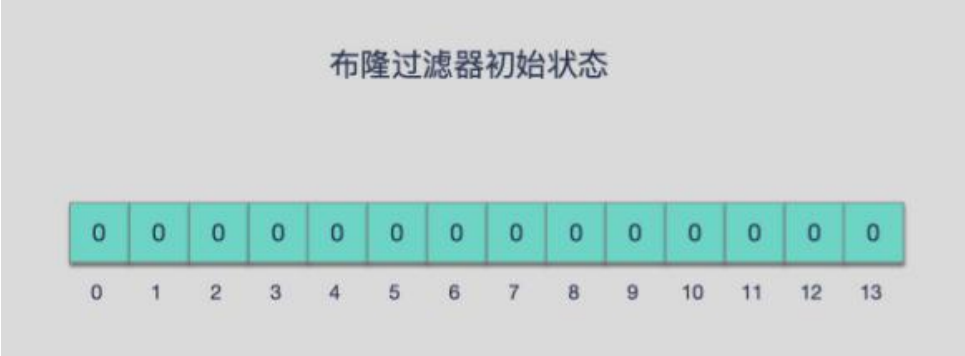
一系列随机映射函数(Hash函数)构成
布隆过滤器中的哈希函数对于其准确性至关重要。为了实现高效的布隆过滤器,我们需要选择合适的哈希函数,并注意避免冲突、优化哈希长度、考虑空间效率和查询效率以及进行测试和调优1。哈希函数的个数需要权衡,个数越多则布隆过滤器的效率越低,但误报率会变低;如果太少的话,误报率会变高23。除了选择合适的哈希函数外,我们还可以通过合并多个布隆过滤器来提高其准确性,这种方法被称为“多重布隆过滤器”。
原理
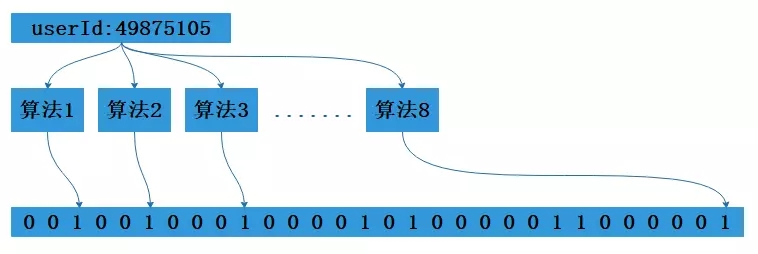
将key值传入一系列Hash函数得到对应的一系列数组地址(索引下标),注意这里一般来说有几个Hash函数就会得到几个地址,然后去判断这几个索引下标对应的值是否均为1,是的话则说明存在,否则不存在
布隆过滤器会有一定误判率。说明即使是在一系列Hash函数下,依然会有巧合:“一个不存在的元素,对应的一系列映射后的地址的值为1,即出现误判
- 存在误判的可能性:当布隆过滤器判断某个元素存在时,有一定的概率是误判的,即元素实际上并不存在于集合中,但布隆过滤器错误地认为存在。
- 不存在误判的确定性:当布隆过滤器判断某个元素不存在时,这个判断是绝对准确的,即如果布隆过滤器认为元素不存在,那么元素一定不在集合中。
布隆过滤器元素的修改和删除
由于我们在插入元素时,不同的值可能经过一系列hash函数后得到一系列地址,存在hash冲突问题,有可能多个值的地址是同一个,那么将这个1改为0无法确定这个地址是否也对应其他的值,会导致数据的逻辑丢失的问题(存在的值在检索的时候返回不存在)
布隆过滤器优缺点
优点:
时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
保密性强,布隆过滤器不存储元素本身
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set、Map集合)
缺点:
有点一定的误判率,但是可以通过调整参数来降低
无法获取元素本身
很难删除元素
实现
java代码
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}
Guava工具类
public BloomFilter<CharSequence> init() {
BloomFilter<CharSequence> bloomFilter =
BloomFilter.create(Funnels.stringFunnel(
Charset.forName("utf-8")), 10000, 0.0001);
//int expectedInsertions 10000 预计添加的元素
//double fpp 0.0001 误判率
return bloomFilter;
}
simpleBloomFilter.add(s.getSkuId()); //添加元素
simpleBloomFilter.contains(skuId)//查询元素Hutool工具类 (hutool 的布隆过滤器不支持 指定 错误比率,并且内存占用太高了)
import cn.hutool.bloomfilter.BitMapBloomFilter;
public class HutoolBloomFilter {
public static void main(String[] args) {
// 一旦数量过大很容易出现内存异常:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
int capacity = 1000;
// 初始化
BitMapBloomFilter filter = new BitMapBloomFilter(capacity);
for (int i = 0; i < capacity; i++) {
filter.add(String.valueOf(i));
}
System.out.println("存入元素为=={" + capacity + "}");
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (int i = capacity; i < capacity * 2; i++) {
if (filter.contains(String.valueOf(i))) {
count++;
}
}
System.out.println("误判元素为=={" + count + "}");
}
}redisson实现和redisbloom(插件需要安装)
RedisBloom和Redisson实现的过滤器区别:
数据结构: RedisBloom相当于为了实现过滤器而新增了一个数据结构,而Redisson是基于redis原有的bitmap位图数据结构来通过硬编码实现的过滤器。
存储: 存储两者其实并没有差距,都没有存储原数据,我使用Redisson存储了10000条数据然后设置的0.01容错占用了11.7kb也符合布隆过滤器的占用。
import io.rebloom.client.Client;
import redis.clients.jedis.Jedis;
public class JrebloomDemo {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("192.168.115.239", 6379);
//jedis.auth("123456");
//创建client也支持连接池的:public Client(Pool<Jedis> pool)
Client client = new Client(jedis);
// 测试数据
int capacity = 10000;
// 容错率,只能设置0 < error rate range < 1 不然直接会异常!
double errorRate = 0.01;
// 测试的key值
String key = "ceshi";
// 创建过滤器:可以创建指定位数和容错率的布隆过滤器,如果过滤器已经存在创建的话就会异常
if (!jedis.exists(key)) {
client.createFilter(key, capacity, errorRate);
}
for (int i = 0; i < capacity; i++) {
client.bfInsert(key, String.valueOf(i));
}
System.out.println("存入元素为=={" + capacity + "}");
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (int i = capacity; i < capacity * 2; i++) {
if (client.exists(key, String.valueOf(i))) {
count++;
}
}
System.out.println("误判元素为=={" + count + "}");
// 删除过滤器
client.delete(key);
}
}
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
//.setPassword("123456")
.setDatabase(0);
//获取客户端
RedissonClient redissonClient = Redisson.create(config);
// 测试数据
int capacity = 10000;
// 容错率,只能设置0 < error rate range < 1 不然直接会异常!
double errorRate = 0.01;
// 测试的key值
String key = "ceshi";
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(key);
// 初始化布隆过滤器,预计统计元素数量为10000,期望误差率为0.01
bloomFilter.tryInit(capacity, errorRate);
for (long i = 0; i < capacity; i++) {
bloomFilter.add(String.valueOf(i));
}
System.out.println("存入元素为=={" + capacity + "}");
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (int i = capacity; i < capacity * 2; i++) {
if (bloomFilter.contains(String.valueOf(i))) {
count++;
}
}
System.out.println("误判元素为=={" + count + "}");
// 删除过滤器
// bloomFilter.delete();
}
}















 2765
2765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









