






一,使用场景(缓存穿透)
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
二,解决方案
(1)缓存无效key
如果缓存和数据库都查不到某个key的数据,就写一个到redis中并且设置过期时间。这种方案可以解决请求的key变化不频繁的情况,如果黑客恶意频繁攻击,每次都构建不同的key,会导致redis中存大量无效的key。
所以这种方案无法从根本上解决问题。
(2)布隆过滤器
什么是布隆过滤器?
布隆过滤器可以很方便的判断出一个给定的数据是否存在海量数据中(redis缓存数据),具体来说,他会将每个可能存在的请求key都放到布隆过滤器中,请求过来时会判断请求key是否在布隆过滤器里,如果存在,就返回混存中对应的数据,如果不存在,就认为这是一个无效的请求,返回本次请求错误。
具体实现就是一个key,经过若干个哈希函数,计算得到在位数组上的位置index,将这些位置都设置为1。
编码实现:
(只用了一个哈希函数)
package com.example.bloomfilter;
import java.util.BitSet;
/**
* @Author YuLing
* @Date 2024-04-07 10:08
* @Description:
* @Version 1.0
*/
public class BloomFilter {
static final int DEFAULT_SIZE = 2 >> 24;
BitSet bitSet = new BitSet(DEFAULT_SIZE);
public void add(Object value) {
int hash = hash(value);
bitSet.set(hash, true);
}
public boolean contains(Object value) {
int hash = hash(value);
return bitSet.get(hash) == true;
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter();
long cap = 10000000L;
for (long i = 0; i < cap; i++) {
bloomFilter.add(i);
}
int cnt = 0;
for (long i = cap; i < cap * 2; i++) {//不存在可能会判定为存在 存在不会判错
if (bloomFilter.contains(i)) {
cnt++;
}
}
System.out.println(cnt);
}
}
Guava库提供的:
依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.0.1-jre</version>
</dependency>package com.example.bloomfilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @Author YuLing
* @Date 2024-04-07 11:12
* @Description:
* @Version 1.0
*/
public class GuavaTest {
/**
* 要插入多少数据
*/
private static long cap = 1000000L;
/**
* 期望的误判率
*/
private static double fpp = 0.01;
public static void main(String[] args) {
BloomFilter<Long> bloomFilter = BloomFilter.create(Funnels.longFunnel(), cap, fpp);
for (long i = 0; i < cap; i++) {
bloomFilter.put(i);
}
int count = 0;
for (long i = cap; i < cap * 2; i++) {
if (bloomFilter.mightContain(i)) {
count++;
}
}
System.out.println(count);
}
}上面这种自己指定错误率(必须是大于0的小数)和自定义插入数据量。
可以通过打断点进去,当数据量是一百万,错误率是0.01的时候,需要的位数是九百多万,经过的哈希函数是7个。
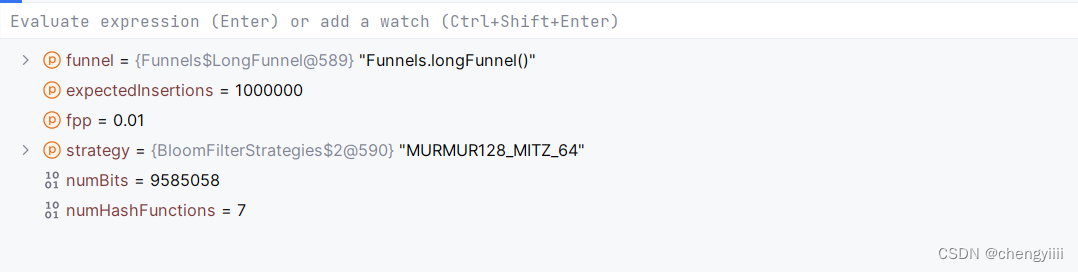
然后数据量没变,错误率改成0.01,再次debug,这次需要的位数是一千多万位,经过的哈希函数是10个。
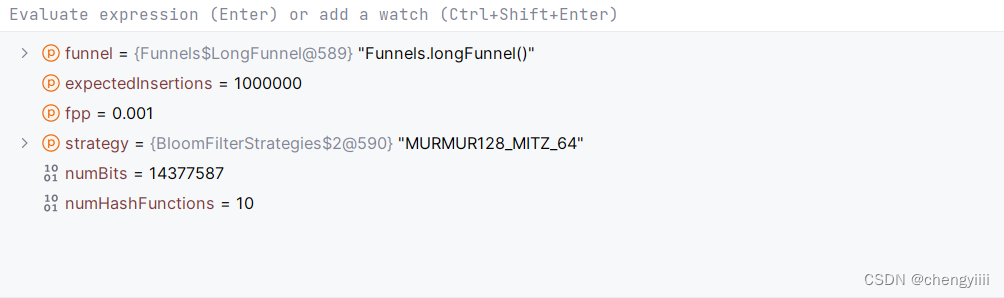
fpp越小,那需要的空间就会越大,并且需要经过更多的哈希函数进行运算。
但是相比较HashMap,布隆过滤器的空间效率还是非常高的。
布隆过滤器为什么会出现误判现象?
布隆判断出某个元素存在实际上可能他并不存在,判断出某个元素不存在他一定不存在。
也就是哈希值相同的可能是不同的字符串,但是哈希值不同的字符串肯定不同。
可通过适当增加数组大小或者调整哈希函数来降低误判概率。















 2754
2754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









