







前言:
大家好呀,我是Humble,今天我们来到指针的第二篇博客
我们要在第一篇的基础上拓展一些内容(注意:我们后面所有的内容都是基于前面的基础,还没看过一的小伙伴记得从我的专栏进入阅读哦,也欢迎各位订阅我的专栏)
那么,废话不多说,开始指针的第二篇吧
一.数组名的理解
在上一篇博客中,我们在使用指针访问数组的内容时,有这样的代码
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int *p = &arr[0];
这里我们使用 &arr[0] 的方式拿到了数组第一个元素的地址,但是其实数组名本来就是地址,而且 是数组元素的地址,我们来做个测试,看一下下面代码的测试结果
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}
我们发现数组名和数组首元素的地址打印出的结果一模一样,数组名就是数组首元素(第一个元素)的地址
这时候有同学会有疑问?数组名如果是数首元素的地址,那下面的代码怎么理解呢?
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
return 0;
}这个代码的结果无疑是40,如果arr是数组首元素的地址,那在x64的环境下输出应该的应该是8才对
其实数组名就是数组首元素(第一个元素)的地址是对的,但是有两个例外:
1. sizeof(数组名),sizeof中单独放数组名,这里的数组表示整个数组,计算的是整个数组的大小, 单位是字节
2. &数组名,这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素 的地址是有区别的)
除此之外,任何地方使用数组名,数组名都表示首元素的地址
这时有好奇的同学,可能会试一下下面这个代码
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
printf("&arr = %p\n", &arr);
return 0;
}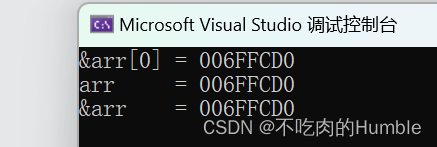
三个打印结果一模一样,这时候又纳闷了,那arr和&arr有啥区别呢?
其实,我们看一下下面的代码就会理解了
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}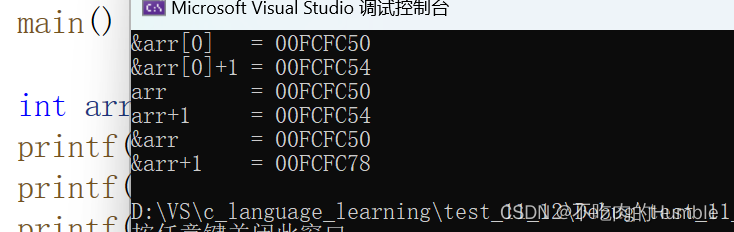
这里我们发现&arr[0]和&arr[0]+1相差4个字节,arr和arr+1 相差4个字节,是因为&arr[0] 和 arr 都是首元素的地址,+1就是跳过一个元素。
但是&arr 和 &arr+1相差40个字节,这就是因为&arr是数组的地址,+1 操作是跳过整个数组的。 到这里大家应该搞清楚数组名的意义了吧。
数组名是数组首元素的地址,但是有2个例外.请大家记住这一点哦
二.使用指针访问数组
好,我们现在对数组名有了一点的理解,再结合前面知识的以及数组的特点,我们就可以很方便的使用指针访问数组了
我们先来简单总结一下:
1.数组在内存中是连续存放的
2.数组名就是首元素的地址(除了2个例外),方便找到起始位置
请看下面这个代码,我们来郑重的介绍一下
int main()
{
int arr[10] = {0};
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
int* p = arr;
for(i=0; i<sz; i++)
{
scanf("%d", p+i);
//scanf("%d", arr+i);//也可以这样写
}
//输出
for(i=0; i<sz; i++)
{
printf("%d ", *(p+i));
}
return 0;
}这里的int* p =arr,arr就是数组的首元素地址,并将其赋给p
在scanf这行的代码,我们原来给数组赋值会写成scanf("%d",&arr[i]);
现在我们可以写成:
scanf("%d", p + i);
或者这样:scanf("%d", arr+i);
因为arr与p是等价的,都是首元素的地址
同理,我们输出的时候可以写成 printf("%d ", *(p + i));
通过分析我们知道了
其实数组名arr和p在这里是等价的。那我们既然可以使用arr[i]可以访问数组的元素,那p[i]是否也可 以访问数组呢
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
for (i = 0; i < sz; i++)
{
printf("%d ", p[i]);
}
for (i = 0; i < sz; i++)
{
printf("%d ",*(arr+i));
}
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
我们发现,上面的代码都是等价的,其实本质就是指针访问
好,之前我们学过了数组,知道了数组是可以传递给函数的,
所以我们接下来讨论一下数组传参的本质。
三.一维数组传参的本质
我们首先从一个问题开始,我们之前都是在函数外部计算数组的元素个数,那我们可以把函数传给一个函数后,函数内部求数组的元素个数吗?
void test(int arr[])
{
int sz = sizeof(arr)/sizeof(arr[0]);
printf("sz = %d\n", sz);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr)/sizeof(arr[0]);
printf("sz = %d\n", sz);
test(arr);
return 0;
}
看一下运行结果,理论上两个sz应该相同

我们发现在函数内部是没有正确获得数组的元素个数。
这就要学习数组传参的本质了,上个小节我们学习了:
数组名是数组首元素的地址;那么在数组传参的时候,传递的是数组名,也就是说本质上数组传参本质上传递的是数组首元素的地址。即test()的括号里放的不是arr数组而是arr数组的首个元素的地址,()里并没有创建新的形参数组,放的应该是 int* arr
所以在计算test中的sz时, sizeof(arr)算的是1个指针变量的大小,因为在x64的环境下1个指针变量的大小是8,而后面的 sizeof(arr[0])是一个整数的大小是4个字节,所以最后得到的结果才为2
所以函数形参的部分理论上应该使用指针变量来接收首元素的地址。那么在函数内部我们写 sizeof(arr) 计算的是一个地址的大小而不是数组的大小。正是因为函数的参数部分是本质是指针,所以在函数内部是没办法求的数组元素个数的
一个小知识:我们把传过去的不是数组而是数组的首元素地址叫做数组的降级
总结:一维数组传参,形参的部分可以写成数组的形式,也可以写成指针的形式
四.冒泡排序
在学冒泡排序之前,我们在来引导一下:
就是我们学习了这些数组,函数之后,能不能将它们结合起来实现一些功能呢?
答案是可以的,接下来我们做一个练习,写一个函数,对一个整形数组的数组进行排序
其实,排序的方法有很多,
我们的先驱已经给我找到了很多的算法
比如:
1.冒泡排序(也就是今天要讲的,比较好理解的一种排序思想)
2.选择排序
3.插入排序
4.希尔排序
5.快速排序
........
那我们就来正式介绍一下冒泡排序
冒泡排序的核心思想就是:两两相邻的元素进行比较
下面是最基础的冒泡排序,通过双重的内外循环,这里数组的10个元素,我们外循环走9次,内循环从9次到8次...遍历次数随比较范围缩小一次次减少
所以在循环完后,我们就得到了有序的数组(这里是升序排列)
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int j = 0;
for(j=0; j<sz-i-1; j++)
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}
int main()
{
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr, sz);
for(i=0; i<sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
不过这段代码也有它的不足,在于效率,比如排序这个数组的序列9,0,1,2,3,5,4,6,8,7
用这样的方法效率就很低了,我们可以用count来跟踪一下比较次数
void bubble_sort(int arr[], int sz)
{
int i = 0;
int count = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
count++;
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
printf("%d\n", count);
}
int main()
{
int arr[] = { 9,0,1,2,3,5,4,6,8,7 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
结果如下:
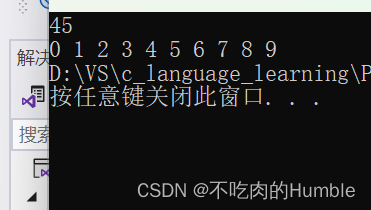
所以我们必须优化,我们可以使用一个变量flag来中止比较已经有序的数组
void bubble_sort(int arr[], int sz)
{
int i = 0;
int count = 0;
for (i = 0; i < sz - 1; i++)
{
int flag = 1;
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
count++;
if (arr[j] > arr[j + 1])
{
flag = 0;
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if (flag == 1)
break;
}
printf("%d\n",count);
}
int main()
{
int arr[] = { 9,0,1,2,3,5,4,6,8,7 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}我们来看一下结果

果然少了不少
五.二级指针
什么是二级指针呢?
我们之前学的其实都是一级指针,比如:
int * pi;
char * pc;
double* pd
.....
我们说指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里?
这就是二级指针
来看下面的代码
int main()
{
int a = 0;
int* p = &a; //p是指针变量,是一级指针!
int** pp = &p;//pp是二级指针!
return 0;
}
这里该怎么理解呢?
我们知道在一级指针中,*是用来说明p是指针的,而int表示p指向的对象a类型是int
好,知道了这点,我们把它类比到二级指针中,同理,后面的这个*是用来说明pp是指针,而int*表示pp指向的对象p的类型是int*
这样大家就能理解二级指针了吧
看到这,相信大家可能会产生这样的想法:
既然有二级,那是不是就可以有三级,四级,或者更高级的指针呢?
其实有的,比如三级指针我们就可以写成int***ppp=&pp;ppp就是三级指针
不过,虽然语法支持,但事实上,我们三级指针就已经用的非常少了
我们一般用到二级指针就差不多了,没必要再往下套了
好,我们继续分析上面的代码,看一下二级指针到底该怎么用:
我们知道p里面放的是a的地址,如果我们对它解引用,就能得到a,
pp里面放的是p的地址,如果我们对它解引用,就能得到p
所以我们用printf函数 打印*pp就能得到&a,**pp就能得到a
看到这,其实我们发现,二级指针并没有想象的那么神秘,二级指针变量是用来存放一级指针变量的地址
六.指针数组
对于这个定义,希望大家先记住下面两句话,这样大家就应该能对指针数组有一个很好的理解了
指针数组其实是存放指针的数组
指针数组的每个元素是指针类型
那么现在我们希望得到一个数组,数组有5个元素,每个元素是整型指针,那么我们该怎么写呢?
思考一下,应该能写出下面的形式:
int* arr[5]; 这个数组的每个元素都是整型指针,所以它是指针数组
我们来看一下下面这张图来辅助理解一下这个概念吧

七.指针数组模拟二维数组
学了指针数组我们可以干什么呢?
接下来我们就通过指针数组来模拟一下二维数组吧
请看下面的代码:
int main()
{
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
int* parr[3] = {arr1, arr2, arr3};
int i = 0;
int j = 0;
for(i=0; i<3; i++)
{
for(j=0; j<5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}
这里的parr[i][j]其实由指针的理解,每一次内循环是
*(arr1+j)
*(arr2+j)
*(arr3+j)
写在一起就是*(*(parr+i)+j )
下面是parr数组的画图演示,来更直观的理解:

parr[i]是访问parr数组的元素,parr[i]找到的数组元素指向了整型一维数组,parr[i][j]就是整型一维数组中的元素
需要注意的是:上述的代码模拟出二维数组的效果,实际上并非完全是二维数组
因为每一行并非是连续的
结语:
好了,今天的分享就到这里了
最后,希望大家点个赞或者关注吧(感谢感谢)
让我们在接下来的时间里一起成长,一起进步吧!(也敬请期待下一篇博客哦)

















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











