







前言
大家好呀,我是Humble,今天给大家带来的内容是C语言的编译和链接,以及编译中的预处理详解
这一章的内容更加偏向底层,可帮助我们更好的了解我们平时写的代码都是怎么被计算机读懂的

好了 废话不多说,开始今天的分享~
一.翻译环境和运行环境
不知道大家有没有想过,当我们在VS或者其他编译器上创建.c源文件之后,计算机又进行了哪些操作使其转换成可执行的.exe文件并被执行呢?
其实,在这中间存在两个环境,即我们今天要说的 翻译环境和运行环境
在翻译环境中:源代码被转换为可执行的机器指令
在运行环境中:它用于实际执行代码
下面用一张图表示翻译环境和运行环境
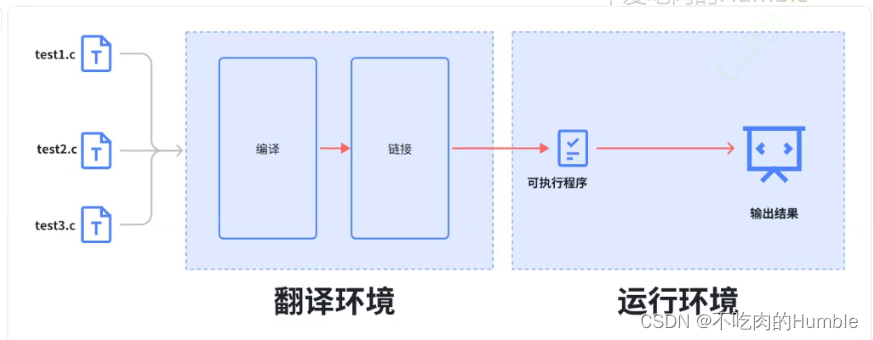
好,对翻译环境和运行环境都有了一个粗略的印象之后,我们先来详细看看翻译环境中有哪些内容吧
二.翻译环境
翻译环境是由编译和链接两个大的过程组成的
而编译(广义)又可以分解成:预处理(或者叫预编译)、编译(狭义)、汇编三个过程
关系如下图: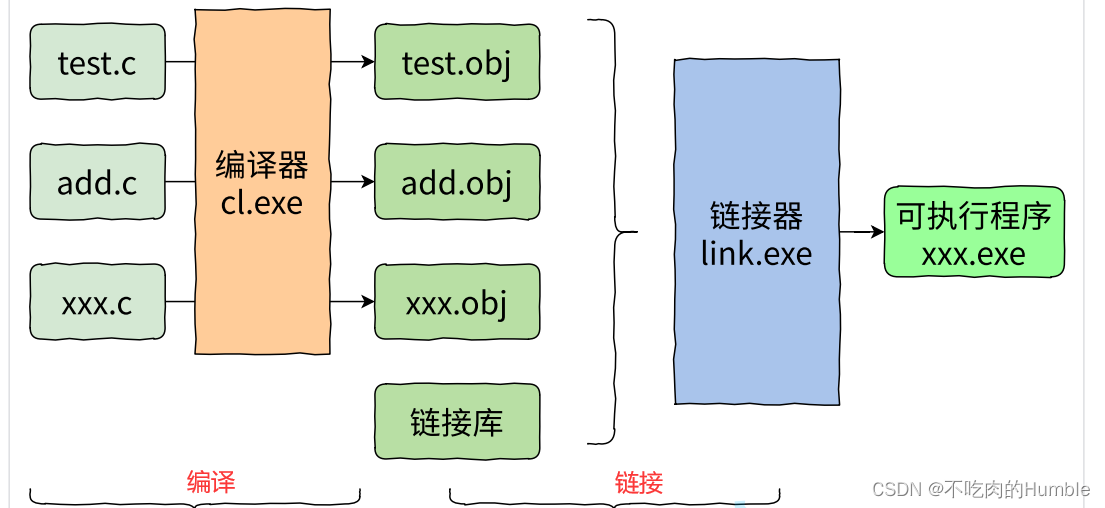
一个C语言的项目中可能有多个 .c 文件一起构建,多个 .c 文件如何生成可执行程序也正如上图所示,用文字表示可分以下两点:
1.多个.c文件单独经过编译出编译处理生产对应的目标文件
(注:在Windows环境下的目标文件的后缀是 .obj ,Linux环境下目标文件的后缀是 .o )
2.多个目标文件和链接库一起经过链接器处理生成最终的可执行程序
如果再把编译展开成3个过程(预处理(或者叫预编译)、编译(狭义)、汇编),
那就变成了下面的过程:
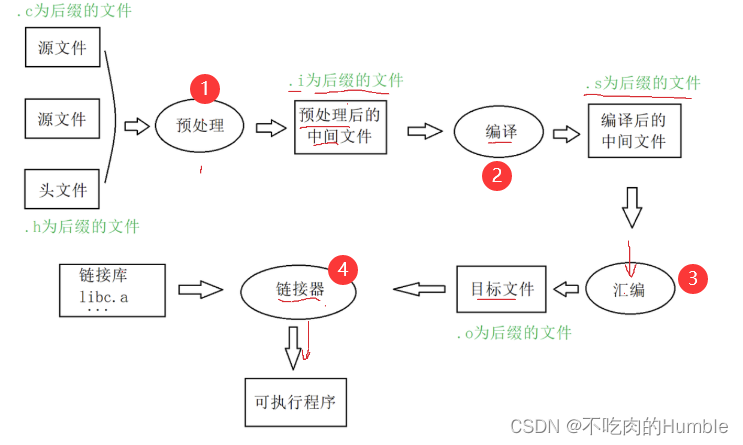
注:
预处理后得到的文件变成.c为后缀
编译后得到的文件变成.s为后缀
汇编后得到的文件变成.o为后缀
下面我们具体的看一下编译的三个过程
下面所有的示例以gcc为例,来拆解编译与链接的过程
A.预处理(预编译)
在预处理阶段,源文件和头文件会被处理成为.i为后缀的文件
在 gcc 环境下想观察一下,对 test.c 文件预处理后的.i文件,命令如下:
gcc -E test.c -o test.i
预处理阶段主要处理那些源⽂件中#开始的预编译指令。⽐如:#include,#define,处理的规则如下:
1.将所有的 #define 删除,并展开所有的宏定义
2. 处理所有的条件编译指令,如: #if、#ifdef、#elif、#else、#endif 。
3. 处理#include预编译指令,将包含的头文件的内容插入到该预编译指令的位置,这个过程是递归进行的,也就是说被包含的头文件也可能包含其他文件
4. 删除所有的注释
*5.添加行号和文件名标识,方便后续编译器生成调试信息等
*6.保留所有的#pragma的编译器指令,编译器后续会使用
经过预处理后的 .i 文件中不再包含宏定义,因为宏已经被展开。并且包含的头文件都被插入到.i文中。
所以当我们无法知道宏定义或者头文件是否包含正确的时候,可以查看预处理后的.i文件来确认
上面是对预处理的一个大致的介绍,接下来我们来详细讲一下预处理的一些知识,
内容比较丰富,希望对大家有帮助~
1.预定义符号
C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的
下面这些都是预定义符号
__FILE__ //进行编译的源文件
__LINE__//文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
举个例子,我们将下面的代码在VS上打印一下
printf("file:%s line:%d\n", __FILE__, __LINE__);
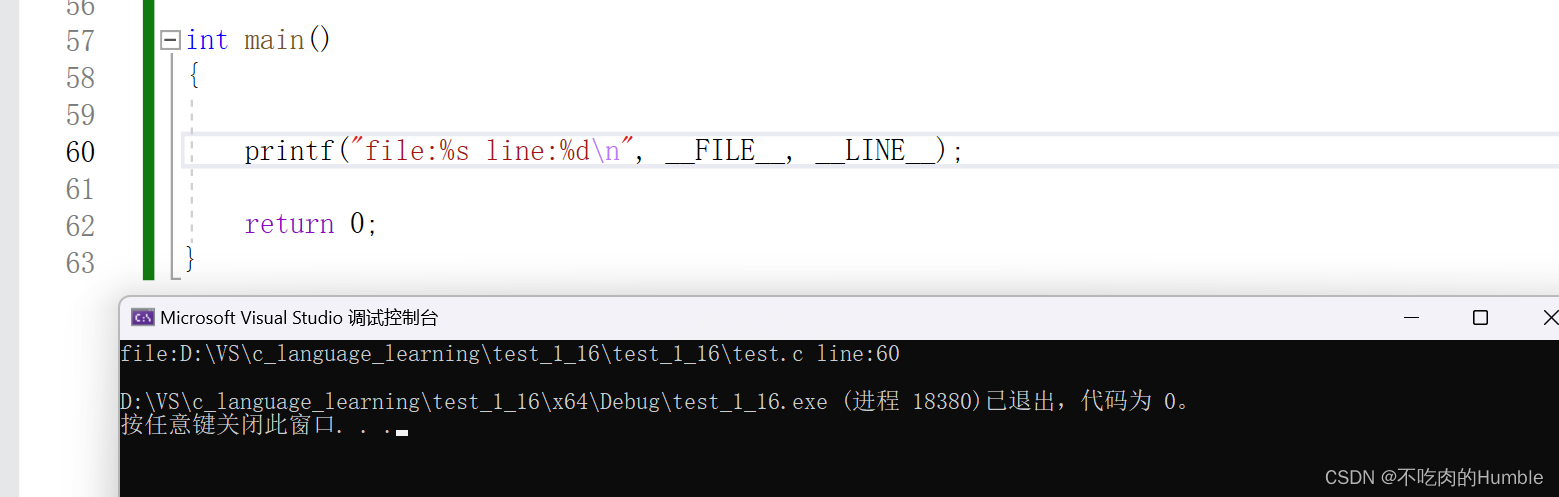
我们发现就可以读取文件所在目录以及文件当前的行号
2.#define定义常量
基本格式如下:
#define name stuff //name为名字 stuff为常量值
举个例子
#define MAX 1000
注意:在define定义标识符的时候,在最后最好不要加上 ;
这样容易导致问题,比如下面的场景
#define MAX 1000
if(condition)
max = MAX;
else
max = 0;
如果是加了分号的情况,等替换后,if和else之间就是2条语句,即max = 1000;;
而没有大括号的时候,if后边只能有一条语句。这里会出现语法错误
3. #define定义宏
首先,什么是宏?
在#define机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏或定义宏
下面是宏的申明方式:
#define name( parament-list ) stuff //其中的 parament-list 是一个由逗号隔开的符号表,它们可能出现在stuff中
注意:参数列表的左括号必须与name紧邻,如果两者之间有任何空白存在,参数列表就会被解释为stuff的⼀部分
举个例子:
#define SQUARE( x ) x * x //用于计算x的平方
这个宏接收一个参数 x .
如果在上述声明之后,把 SQUARE( 5 ); 置于程序中下面这个表达式替换上面的表达式: 5 * 5
BUT!
这个宏存在一个问题:请观察下面的代码段:
int a = 5;
printf("%d\n" ,SQUARE( a + 1) );
这里有一个陷阱,乍⼀看,你可能觉得这段代码将打印36
事实上它将打印11,为什么呢?
因为替换时,当参数x被替换成a+1后,所以这条语句实际上变成了:
printf ("%d\n",a + 1 * a + 1 );
这样就比较清晰了,由替换产生的表达式并没有按照预想的次序进行求值
对于这个问题的解决方案也不难
在宏定义上加上两个括号,这个问题便轻松的解决了
如下:
#define SQUARE(x) (x) * (x)
所以,当我们使用#define定义宏时,都应该用这种方式加上括号,避免在使用宏时由于参数中的
操作符或邻近操作符之间不可预料的相互作用
4. 带有副作用宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果
副作用就是表达式求值的时候出现的永久性效果
例如:
x+1;//不带副作用
x++;//带有副作用
下面我们来看一下带有副作用的宏参数
请看下面的代码,输出的结果是什么?
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
...
x = 5;
y = 8;
z = MAX(x++, y++);
printf("x=%d y=%d z=%d\n", x, y, z);
这里我们得知道预处理器处理之后的结果是什么
z = ( (x++) > (y++) ? (x++) : (y++));
所以最后输出的结果是:
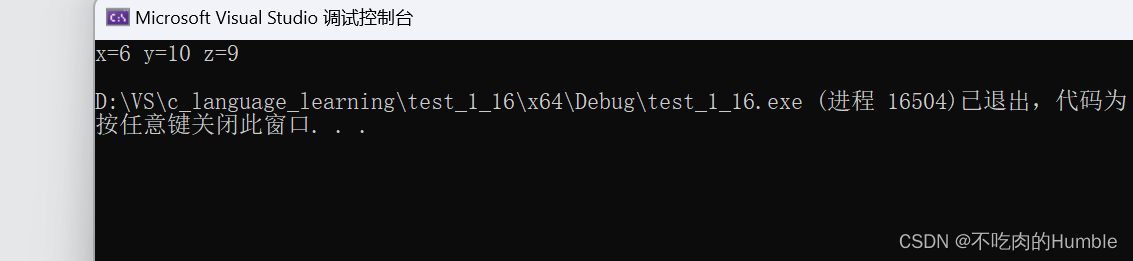
最后的结果z与x++和y++都不同,这就是带有副作用的宏参数
5. 宏替换的规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤:
1. 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号,如果是,它们首先被替换
2. 替换文本随后被插入到程序中原来文本的位置,对于宏,参数名被他们的值所替换
3. 最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程
注意:
1. 宏参数和#define定义中可以出现其他#define定义的符号,但是对于宏,不能出现递归
2. 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索
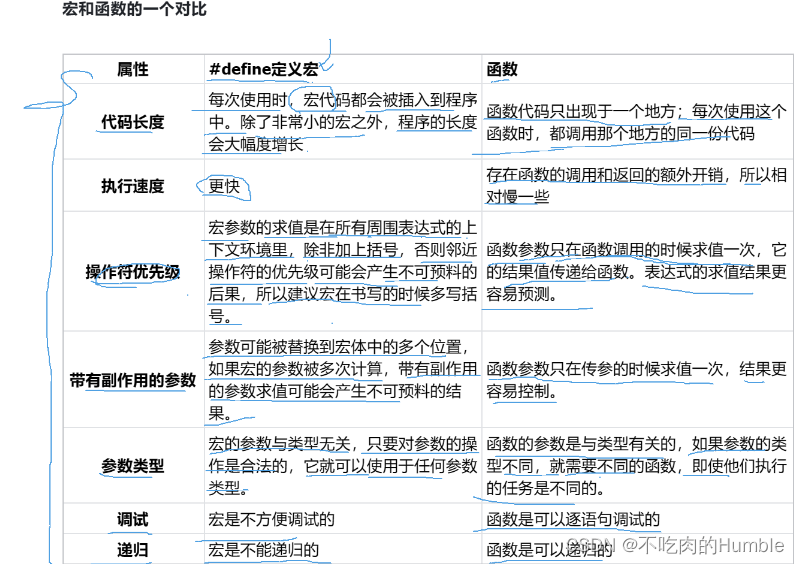
6.宏函数的对比
其实在了解宏之后,我们发现它与函数是非常相似的,下面我们来对它俩进行一个对比
宏通常被应用于执行简单的运算
宏的优势:
1.在小型的运算中,宏比函数在程序的规模和速度方面更胜一筹
2.更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使⽤。
而宏可以适用于整形、长整型、浮点型等类型。因为宏是类型无关的
宏的劣势:
1. 每次使用宏的时候,就有一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度
2. 宏是没法调试的
3. 宏由于类型无关,也就不够严谨
4. 宏可能会带来运算符优先级的问题,导致程序容易出现错误
不过,宏有时候可以做函数做不到的事情
比如:宏的参数可以出现类型,但是函数做不到
#define MALLOC(num, type) (type )malloc(num sizeof(type))
...
//使用
MALLOC(10, int);//类型作为参数
//预处理器替换之后:
(int)malloc(10 sizeof(int));最后,我们对宏和函数以图表的形式进行一个比较:
7. #和##
先说#
#运算符将宏的⼀个参数转换为字符串字⾯量。它仅允许出现在带参数的宏的替换列表中
#运算符所执⾏的操作可以理解为”字符串化“
当我们有⼀个变量 int a = 10; 的时候,我们想打印出: the value of a is 10
就可以写:
#define PRINT(n) printf("the value of "#n " is %d", n);
当我们按照下面的方式调用的时候:
PRINT(a);//当我们把a替换到宏的体内时,就出现了#a,而#a就是转换为 a),
代码就会被预处理为:
printf("the value of ""a" " is %d", a);
这样就可以实现the value of a is 10 的打印效果了
再说##
## 可以把位于它两边的符号合成⼀个符号,它允许宏定义从分离的文本片段创建标识符。 ## 被称
为记号粘合
这样的连接必须产生一个合法的标识符。否则其结果就是未定义的。
这里我们想想,写一个函数求2个数的较大值的时候,不同的数据类型就得写不同的函数。
比如:
int int_max(int x, int y)
{
return x>y?x:y;}
但是这样写起来太繁琐了,现在我们这样写代码试试:
//宏定义,与函数定义很类似!
#define GENERIC_MAX(type) \type type##_max(type x, type y)\
{ \
return (x>y?x:y); \
}
使用宏,定义不同函数
GENERIC_MAX(int)
int main()
{
//调用函数
int m = int_max(2, 3);
printf("%d\n", m);
return 0;}
这样我们就能得到 3 的结果了
注意:在实际开发过程中##其实使用的很少,所以这里也是了解即可
8. 命名约定
一般(不是绝对的哦)来讲函数的宏的使用语法很相似。
所以语言本身没法帮我们区分二者,
那我们平时的一个习惯是:
把宏名全部大写
函数名不要全部大写
9.#undef
这条指令用于移除一个宏定义
#undef NAME
//如果现存的⼀个名字需要被重新定义,那么它的旧名字首先要被移除
10.命令行定义
许多C的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处。
举个例子:
假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大些,我们需要一个数组能够大些
代码如下:
int main()
{
int array [ARRAY_SIZE];
int i = 0;
for(i = 0; i< ARRAY_SIZE; i ++)
{
array[i] = i;
}
for(i = 0; i< ARRAY_SIZE; i ++)
{
printf("%d " ,array[i]);
}
printf("\n" );
return 0;
}在GCC编译器中,我们在命令行中定义符号:
gcc -D ARRAY_SIZE=10 programe.c
这样,我们在代码上虽然没有定义ARRAY_SIZE,但通过命令行定义,最终打印出1~10的数字
11.条件编译
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的。因为我们有条件编译指令
比如:
调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译
#define __DEBUG__
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0; i<10; i++)
{
arr[i] = i;
#ifdef __DEBUG__
printf("%d\n", arr[i]);//为了观察数组是否赋值成功
#endif //__DEBUG__
}
return 0;
}
常见的条件编译指令如下:
1.
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__
#if __DEBUG__
//..
#endif
2.多个分⽀的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
3.判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
4.嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif12. 头文件的包含
本地文件包含
#include "filename"
查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。如果找不到就提示编译错误
库文件包含
#include <filename.h>
查找策略:查找头文件直接去标准路径下去查找,如果找不到就提示编译错误
Q:这样是不是可以说,对于库文件也可以使用 “ ” 的形式包含?
A:答案是肯定的,可以,但是这样做查找的效率就低些,当然这样也不容易区分是库问件还是本地文件了
嵌套文件包含
我们已经知道, #include 指令可以使另外一个文件被编译,就像它实际出现于 #include 指令的
地方一样
这种替换的方式很简单:预处理器先删除这条指令,并用包含文件的内容替换
一个头文件被包含10次,那就实际被编译10次,如果重复包含,那么对编译的压力就比较大
比如下面有这样的.c源文件和.h头文件
test.c
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
int main()
{
return 0;
}
test.h
struct Stu()
{
int id;
char name[20];
};
如果直接这样写,test.c文件中将test.h包含5次,预处理后代码量会剧增。如果工程比较大,那么后果真的不堪设想
那么如何解决头文件被重复引入的问题?
答案:条件编译
每个头文件的开头写:
#ifndef __TEST_H__
#define __TEST_H__
//头文件的内容
#endif //__TEST_H__
就可以避免头文件的重复引入
注:对这方面知识的考察还是有的,上面的这个问题其实就来自《高质量C/C++编程指南》中附录的考试试卷
13.其他预处理指令
#error
#pragma
#line
...
//这里就不做介绍了,感兴趣可以自行了解
注:可以参考《C语言深度解剖》学习
B.编译
编译过程就是将预处理后的文件进行一系列的:词法分析、语法分析、语义分析及优化,生成相应的汇编代码文件
编译过程的命令如下:
gcc -S test.i -o test.s
假设有下面的代码,我们该怎么分析呢?
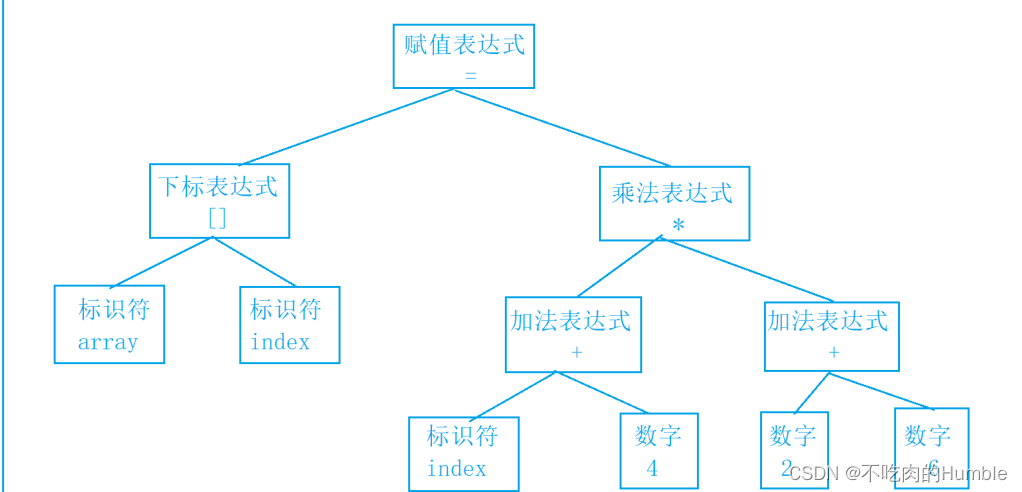
array[index] = (index+4)*(2+6);
这就需要我们刚刚讲的:词法分析、语法分析、语义分析及优化
a.词法分析
将源代码程序被输入扫描器,扫描器的任务就是简单的进行词法分析,把代码中的字符分割成⼀系列的记号(关键字、标识符、字⾯量、特殊字符等)
而上面代码进行词法分析后可以得到了16个记号

b.语法分析
接下来语法分析器,将对扫描产⽣的记号进行语法分析,从而产生语法树。这些语法树是以表达式为节点的树
语法树如下图所示:
c.语义分析
由语义分析器来完成语义分析,即对表达式的语法层面分析,编译器所能做的分析是语义的静态分
析。静态语义分析通常包括声明和类型的匹配,类型的转换等
这个阶段会报告错误的语法信息
通过这三个分析,就完成了第二步,接下来我们看编译的第三个过程:汇编
C.汇编
汇编器是将汇编代码转转变成机器可执行的指令,每一个汇编语句几乎都对应一条机器指令。就是根据汇编指令和机器指令的对照表一一的进行翻译,也不做指令优化
汇编的命令如下:
gcc -c test.s -o test.o
我们知道翻译环境是由编译和链接两个大的过程组成的,讲完了编译的三个过程,接下来我们说说链接
D.链接
链接是⼀个复杂的过程,链接的时候需要把⼀堆⽂件链接在⼀起才⽣成可执⾏程序。
链接过程主要包括:地址和空间分配,符号决议和重定位等这些步骤。
链接解决的是一个项目中多文件、多模块之间互相调用的问题。
比如:
在一个C的项目中有2个.c文件( test.c 和 add.c ),代码如下
test.c 的代码如下:
extern int Add(int x, int y);
extern int g_val;
int main()
{
int a = 10;
int b = 20;
int sum = Add(a, b);
printf("%d\n", sum);
return 0;
}
add.c 的代码如下:
int g_val = 2022;
int Add(int x, int y)
{
return x+y;
}
我们已经知道,每个源文件都是单独经过编译器处理生成对应的目标文件
test.c 经过编译处理生成 test.o
add.c 经过编译处理生成 add.o
我们在 test.c 的文件中使用 add.c 文件中的 Add 函数和 g_val 变量
在 test.c 文件中每一次使用 Add 函数和 g_val 的时候必须确切的知道 Add 和 g_val 的地址
但是由于每个文件是单独编译的,在编译器编译 test.c 的时候并不知道 Add 函数和 g_val
变量的地址,所以暂时把调用 Add 的指令的目标地址和 g_val 的地址搁置。等待最后链接的时候由链接器根据引用的符号 Add 在其他模块中查找 Add 函数的地址,然后将 test.c 中所有引用到
Add 的指令重新修正,让他们的目标地址为真正的 Add 函数的地址,对于全局变量 g_val 也是类
似的方法修正地址。这个地址修正的过程也被叫做:重定位
关于更多关于编译原理的知识:可以自行阅读《程序员的自我修养》一书来深入详细了解
不过我本人认为,这些原理都过于底层,内容比较晦涩而且枯燥,对于我们目前来说,提高写代码的能力才是最重要的
当然这些编译的原理可以帮助我们了解一些原理性的东西,所以作为了解还是需要的
最后我们来粗略的看一下运行环境的一些知识
三.运行环境
1. 程序必须载入内存中。在有操作系统的环境中:⼀般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
2. 程序的执行便开始。接着便调用main函数。
3. 开始执行程序代码
4. 终止程序 :正常终止main函数;也有可能是意外终止
结语
好了,今天的分享就到这里了
在学习C语言的道路上Humble与各位同行,加油吧各位!
最后希望大家点个免费的赞或者关注吧(感谢感谢),也欢迎大家订阅我的专栏
让我们在接下来的时间里一起成长,一起进步吧!

















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











