







一、二叉树的定义
1.二叉树的定义
二叉树(Binary Tree)是n(n≥0)个结点的有限集,它或者是空集(n=0),称为空二叉树;或者是由一个根结点及两棵互不相交的、分别称为左子树和右子树的二叉树组成。
二叉树的存储结构:
typedef struct bitreenode {
int data;
struct bitree* rchild,* lchild;
}bitree;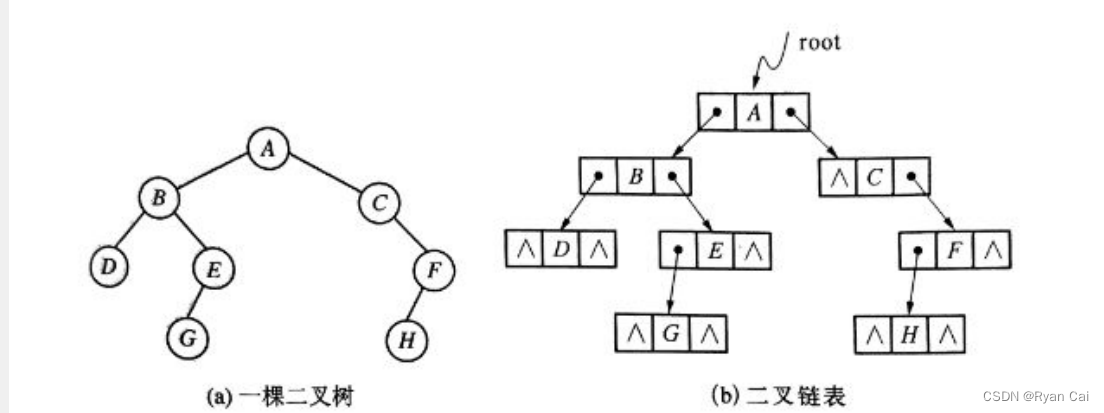
2.二叉树的性质
两种特殊二叉树:
(1)满二叉树:在一棵二叉树中,如果所有分支结点的度都等于2,且所有叶子结点都在同一层上,则这棵二叉树称为满二叉树。
(2)完全二叉树:对一棵深度为h,具有n个结点的二叉树从第一层开始自上而下、自左至右地连续编号1,2,…,n,如果编号为i(1≤i≤n)的结点与深度为h的满二叉树中编号为i的结点位置完全相同,则这棵二叉树称为完全二叉树。

一些性质:
1. 二叉树第i(i≥1)层上至多有个结点。
2.深度为h(h≥1)的二叉树至多有个结点。
3.对任何一棵二叉树,若其叶子数为,度为2的节点数为
,则有
=
+1

这里再讨论两个完全二叉树的性质:
4.具有n(n≥1)个结点的完全二叉树,其深度。
5.对具有n(n≥1)个结点的完全二叉树从树根开始自上而下、自左至右地连续编号1,2,…,n,对于任意的编号为i(1≤i≤n)的结点x,有:
(1)若i=1,则x是根结点,无双亲;否则x的双亲的编号。
(2)若2i>n,则x是叶子结点,无左孩子;否则x的左孩子的编号为2i。
(3)若2i+1>n,则工无右孩子;否则x的右孩子的编号为2i+1。
(4)若i是奇数且不为1,则x的左兄弟的编号为i-1;否则x无左兄弟。
(5)若i是偶数且小于n,则x的右兄弟的编号为i+1;否则x无右兄弟。
二、二叉树的创建
顺序:根->左子树->右子树
void create(bitree** T) {
int x;
printf("输入数字:");
scanf_s("%d", &x);
if (x == -1) (*T) = NULL;
else {
*T = (bitree*)malloc(sizeof(bitree));
(*T)->data = x;
create(&(*T)->lchild);
create(&(*T)->rchild);
}
}注意在创建时,输入了终止信号时记得将(*T)赋值为NULL;
三、二叉树的遍历(递归版本)
1.先序遍历
所谓先序遍历,就是先访问二叉树的根节点,然后再访问其左子节点、右子节点。对于前面的二叉树,其先序遍历的结果就是ABDEGCFH。
根据定义,我们可以利用递归写出代码:
void preorder(bitree* root){
if(root){
visit(root);//visit为对节点的操作函数
preorder(root->lchild);
preorder(root->rchild);
}
}(注意在写代码时对root情况的判断!)
2.中序遍历
所谓中序遍历,就是先访问二叉树的左子节点,然后再访问其根节点、右子节点。对于前面的二叉树,其中序遍历的结果就是DBGEACHF。
根据定义,我们可以利用递归写出代码:
void inorder(bitree* root){
if(root){
inorder(root->lchild);
visit(root);
inorder(root->rchild);
}
}3.后序遍历
所谓后序遍历,就是先访问二叉树的左子节点,然后再访问其右子节点、根节点。对于前面的二叉树,其后序遍历的结果就是DGEBHFCA。
根据定义,我们可以利用递归写出代码:
void postorder(bitree* root){
if(root){
postorder(root->lchild);
postorder(root->rchild);
visit(root);
}
}4.总结
不难看出,这三个算法的区别主要在于visit函数出现的时机。这说明,三种遍历的搜索路线是一样的。在我们利用递归写代码的时候,牢记先序、中序、后序是针对访问根的时机而言的,相应的可以快捷的写出代码。

图为二叉树的搜索路径
三、二叉树的遍历(非递归版本,统一迭代法)
在某些时候,我们可能不得不利用非递归完成对二叉树的遍历。那么,有没有一种像递归算法一样,形式上相对统一的方法呢?答案是程序员Carl提供的统一迭代法。
我这里谈一谈我的理解。以中序遍历为例。要使用迭代法进行二叉树的遍历,显然我们需要使用栈来进行模拟。我们想使弹出栈顶元素的元素是我们要放进结果集的元素,所以就需要按逆序放入这些元素。比如要使结果集中顺序为左中右,我们放进栈的顺序就要是右中左。
然而,我们似乎面临一个不可调和的矛盾!当弹出中节点的时候,我们可能是要对他操作(即弹出以后,在按顺序放入右子节点,中节点,左子节点),也有可能是要把他放入结果集。那么该如何区别呢?
统一迭代法给出的答案是在放入按顺序中节点时,在中节点后面放一个NULL空节点作为标记。在后续读的时候,如果遇到空节点直接弹出,并将下一个节点放入结果集中。
那么在运行过程中,连续出现两个非空节点意味着什么?意味着后一个节点仍需被处理。继续以中序遍历举例,当出现连续两个非空节点时,意味着中节点的右子节点仍然需要被弹出->按顺序放如右子节点,中节点,左子节点。这和中序遍历的顺序是一致的。
代码:
typedef struct sqstack{
bitree** elem;
int top;
}sqstack;
void inistack(sqstack* s){
s->elem=(bitree**)malloc(sizeof(bitree*)*101);
s->top=-1;
}
void push(sqstack* s,bitree* node){
s->elem[++(s->top)]=node;
}
void pop(sqstack* s,bitree** node){
*node=s->elem[(s->top)--];
}
int* inorderTraversal(bitree* root, int* returnSize) {
sqstack s;
int* res=(int*)malloc(sizeof(int)*101);
*returnSize=0;
inistack(&s);
if(root) push(&s,root);
while(s.top!=-1){
bitree* node=(bitree*)malloc(sizeof(bitree));
node=s.elem[s.top];
if(node!=NULL){
pop(&s,&node);//弹出该节点,避免重复操作
if(node->right) push(&s,node->right);//添加右节点
push(&s,node);//添加中节点
push(&s,NULL);//中节点还没进行处理,放入NULL作为标记
if(node->left) push(&s,node->left);//添加左节点
}
else{
pop(&s,&node);//弹出空节点
pop(&s,&node);//弹出结果节点
res[(*returnSize)++]=node->val;//加入结果集
}
}
return res;
}
之所以称为统一迭代法,是因为这个方法对三种遍历方式均适用
具体代码仅需改变以下几行的顺序:
if(node->right) push(&s,node->right);//添加右节点
push(&s,node);//添加中节点
push(&s,NULL);//中节点还没进行处理,放入NULL作为标记
if(node->left) push(&s,node->left);//添加左节点
中序:右中左
先序:右左中
后序:中右左
(是的就是原有顺序的逆序)
四、二叉树的层序遍历
对二叉树除了可以按上述的先序、中序和后序规则进行遍历外,还可以自上而下,自左向右逐层地进行遍历。与先中后序遍历不同,层序遍历需要利用一个队列来存放已访问过的结点的孩子,以控制对这些孩子的访问先后次序。层序遍历的算法思路是:
(1)非空根指针入队。
(2)若队列为空,则遍历结束;否则重复执行:
1.队头元素出队,并访问;
2若被访结点有左孩子,则左孩子人队;
3若被访结点有右孩子,则右孩子入队。
代码:
Definition for a binary tree node.
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
};
typedef struct queue{
struct TreeNode** elem;
int front;
int rear;
int maxsize;
}queue;
//初始化
void iniqueue(queue* q,int maxsize){
q->maxsize=maxsize;
q->elem=(struct TreeNode**)malloc(sizeof(struct TreeNode*)*q->maxsize);
q->front=q->rear=0;
}
//扩容
void increment(queue* q, int incresize) {
struct TreeNode** new_elem = (struct TreeNode**)malloc(sizeof(struct TreeNode*) * (q->maxsize + incresize));
int i = 0, k = q->front;
while ((k) % q->maxsize != q->rear) {
new_elem[i] = q->elem[k];
i++;
k = (k + 1) % q->maxsize;
}
q->elem = new_elem;
q->maxsize+=incresize;
}
//入队
void push(queue*q,struct TreeNode* p){
if((q->rear+1)%q->maxsize==q->front){
increment(q,1);
}
q->elem[q->rear]=p;
q->rear=(q->rear+1)%q->maxsize;
}
//出队
void pop(queue*q,struct TreeNode** temp){
if(q->rear!=q->front){
*temp=q->elem[q->front];
q->front=(q->front+1)%q->maxsize;
}
}
int** levelOrder(struct TreeNode* root, int* returnSize, int** returnColumnSizes) {
int i;
int** res=(int**)malloc(sizeof(int*)*2001);
*returnSize=0;
*returnColumnSizes=(int*)malloc(sizeof(int)*2001);
queue q;
iniqueue(&q,2001);
if(!root) return NULL;
push(&q,root);
while(q.front!=q.rear){
int len=(q.rear-q.front)%q.maxsize;
res[*returnSize]=malloc(sizeof(int)*len);
for(i=0;i<len;i++){
struct TreeNode*temp=(struct TreeNode*)malloc(sizeof(struct TreeNode));
pop(&q,&temp);
if(temp){
res[*returnSize][i]=temp->val;
if(temp->left) push(&q,temp->left);
if(temp->right) push(&q,temp->right);
}
}
(*returnColumnSizes)[*returnSize]=len;
(*returnSize)++;
}
return res;
}C语言使用数组模拟队列,需要自己手写,有关部分显得十分臃肿。C++等其他语言在这方面上优势还是比较明显的。当然在实际做题的时候,没必要写的这么“严谨”。可以将队列直接写到函数里面,给数组分配足够大的空间。
为了使遍历更为高效,我们也可以对二叉树进行线索化。可以参阅下一篇文章:
参考资料:
1.《数据结构及应用算法》















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









