






(本文全是个人的理解,没有过多的概念性的知识,相当于笔记)
二叉树的两大种遍历方式
1.深度优先遍历
深度优先遍历,(我看像)是一种从头到尾的一种遍历方式,我觉得他就是用递归从根到叶子结点的一种遍历方式。
一个单个的二叉树分为三个部分,根节点,左孩子结点和右孩子结点。

我们在遍历的时候,提出了三种遍历的方式,前序遍历,中序遍历和后序遍历。他们的顺序分别是中左右,左中右和左右中(这里的中指的就是根节点)。
我们以三个力扣题目为例。
1)前序遍历
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:

输入:root = [1,null,2,3] 输出:[1,2,3]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:
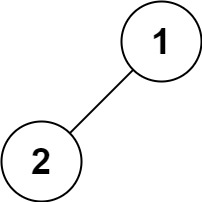
输入:root = [1,2] 输出:[1,2]
示例 5:

输入:root = [1,null,2] 输出:[1,2]
根据上边所给出的例子,我们可以发现前序遍历就是按照中左右的顺序进行的深度优先遍历。
但是总感觉上边的例子不具有代表性,我们自己举一个例子。

我们先自行判断一下,这个二叉树的前序遍历。
按照,中左右的顺序,我们很容易得出
1 2 4 5 3 6 7

而我们只需要实现下边这个段代码的功能。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
}
};返回值是vect<int>类型的,所以我们可以首先定义一个vector<int>的数组。
然后我们确定一种方式,其实用的是栈,这个用起来是真的妙,但是他是怎么想出来的,我也不知道。
我先给出整体性的代码吧.
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if(root!=NULL)
st.push(root);
while(!st.empty())
{
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if(node->right)st.push(node->right);
if(node->left)st.push(node->left);
}
return result;
}
};这是用一个栈通过栈的push和pop来处理二叉树上的结点,按照顺序尾插到result数组中。
我们把栈实例化成这样的一个桶——

把数据push进去,就相当于是把数据放入桶中,反之,pop就是把数据从桶中取出。
当然,值得一提的是,这个栈中储存的并不是真正的数据,而是一个TreeNode* 的结点,是一个指针。
以这个图为例,逐步说明一下,栈的push和pop的过程。(我为了简便,就按照数据的形式写,但是必须要明白这个其实是一个指针)

首先我们判断这个根节点root是否为空,不为空,我们把他加入到桶中及进行后续的操作。

到达while(!st.empty())这一步后,我们先不解释为什么是st不为空的时候,就一直执行循环。

这一步就是把栈的最上层的结点赋给node,然后再把最上层的结点从栈中删除,因为只是从栈中删除,并不影响这个结点本身,所以依然可以对这个结点进行操作,也就是把这个结点的值(指的是node->val,也就是1)尾插到result数组中去。(建议大家可以结合着整体的代码,来分析一下整个的过程,这样理解起来会比较容易)
接下来就是把node的右左孩子push进入栈中,为甚是右左,而不是左右呢?我们不妨就画画,理解一下。
假如是左右的顺序的话,那么左右结点进入栈后的情况就是下图。

由于这个栈只有一个出口,换句话来讲,3就一定会在2的前面,这就变成了,我们先遍历了右节点,再去遍历了左节点,这个顺序是错误的,从我们之前得出的结果(1 2 4 5 3 6 7)也能推翻这个不合理的顺序。
因此我们采取右左的顺序,像这样。

还是提一句吧——
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
这两行代码,是检测node的左结点(右节点)不为空,才会将左节点(右节点)push进入栈中,因为对于栈中的元素,我们都是要进行后续的操作的,所以肯定不能把空指针放进去,不然就会操作空指针,程序就崩溃了。由于我们往栈中添加元素,总会有加完的时候,也就是把二叉树中的所有的元素都加入了栈中(但其实这个时候,栈中的元素并不是二叉树的全部元素,因为我们再添加的时候,也会进行pop,但可以保证的是二叉树中所有的元素都进去过)。当所有的结点都进去过之后,就不会push,只有栈的pop,直到把整个栈中的元素给输出完毕。
由于,此时栈中还有元素(我们刚刚push进去的3,2,再次强调这里的3,2并不是真正的数据3,2,而是结点,他们的值是3,2)
然后,再次开始这个循环

继续把栈的最上层加入到result的数组中,result中存储的就是1,2。接着再把node的左右子树push到栈中,也就是如下图。

后续过程,我们通过画图来说明



最后只剩下两个结点,为了简便,我只画他们pop的过程

最终得到的result中的值是1,2,4,5,3,6,7,这个result数组中存储的值正好就是我们前序遍历的结果。
想必,看到这里大家就是一脸懵,为啥这样使用栈就能得出最终的结果呢?
懵是正常的,我也不懂,有人知道的话,就在评论区说一下吧,跪求一解!!
2)后序遍历
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:

输入:root = [1,null,2,3] 输出:[3,2,1]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
大家可能会感到奇怪,我们平常明明是前序,中序,后序的顺序,为什么这里讲的时候,就是前序,后序,中序呢?这不是反人类嘛。。
其实不然,恰恰是因为我们的后续遍历也可以用上边的方法来实现。
先给出整体的代码
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left);
if (node->right) st.push(node->right);
}
reverse(result.begin(),result.end());
return result;
}
};比对前序遍历的代码,我们很容易发现在返回result之前,我们有一个反转的操作,但其实还有一个比较隐蔽的操作,就是
if (node->left) st.push(node->left);
if (node->right) st.push(node->right);
我先摆明一下,这样修改之后的顺序:中右左
如果你分不清楚的话,你可以类比一下前序遍历的顺序:中左右。我们把左右换了一下位置,也就得到了中右左。
后边遍历的顺序是:左右中
这不是正好反转了一下嘛?
所以,就实现了从前序遍历到后序遍历。
3)中序遍历
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3] 输出:[1,3,2]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
中序遍历的顺序是左中右
我对他的理解就是,我应该先从左往下,直到叶子结点,再回溯,再从左向下,再回溯。
给出整体性的代码。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur!=NULL||!st.empty())
{
if(cur!=NULL)
{
st.push(cur);
cur = cur->left;
}
else
{
cur = st.top();
st.pop();
result.push_back(cur->val);
cur = cur->right;
}
}
return result;
}
};我们定义的这个cur就是我们用来探测的“无人机”,st是记录他的位置(它也像一个路径)的仪器。
我们以此图为例:

这个最终得出的答案是:2 1 4 3
依旧是设计一个栈,把元素push进入栈中进行处理。

然后让cur向左下。



这里我们还需要对4的左右孩子进行判断和回溯,这里我就省略这个过程,直接写从3到4的回溯。

最后得到的数组result就是:2,1,4,3,这样就完成了中序遍历。
2.广度优先遍历(层序遍历)
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

输入:root = [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1] 输出:[[1]]
示例 3:
输入:root = [] 输出:[]
这种遍历方式,相比于之前的遍历方式,更容易被我们所理解。就是从上往下,从左往右,依次把节点上的值加入到数组中。
在这里,我们要使用一个新的工具——队列(queue)
首先,返回值是vector<vecotr<int> >类型的,我们首先定义一个该类型的result,这就相当于是一个二维数组,我们把他想象成行和列的关系,那么每一行就应该是每一层上的所有元素的集合。
而我们要使用的队列就相当于是一个单向的通道,就像这样:
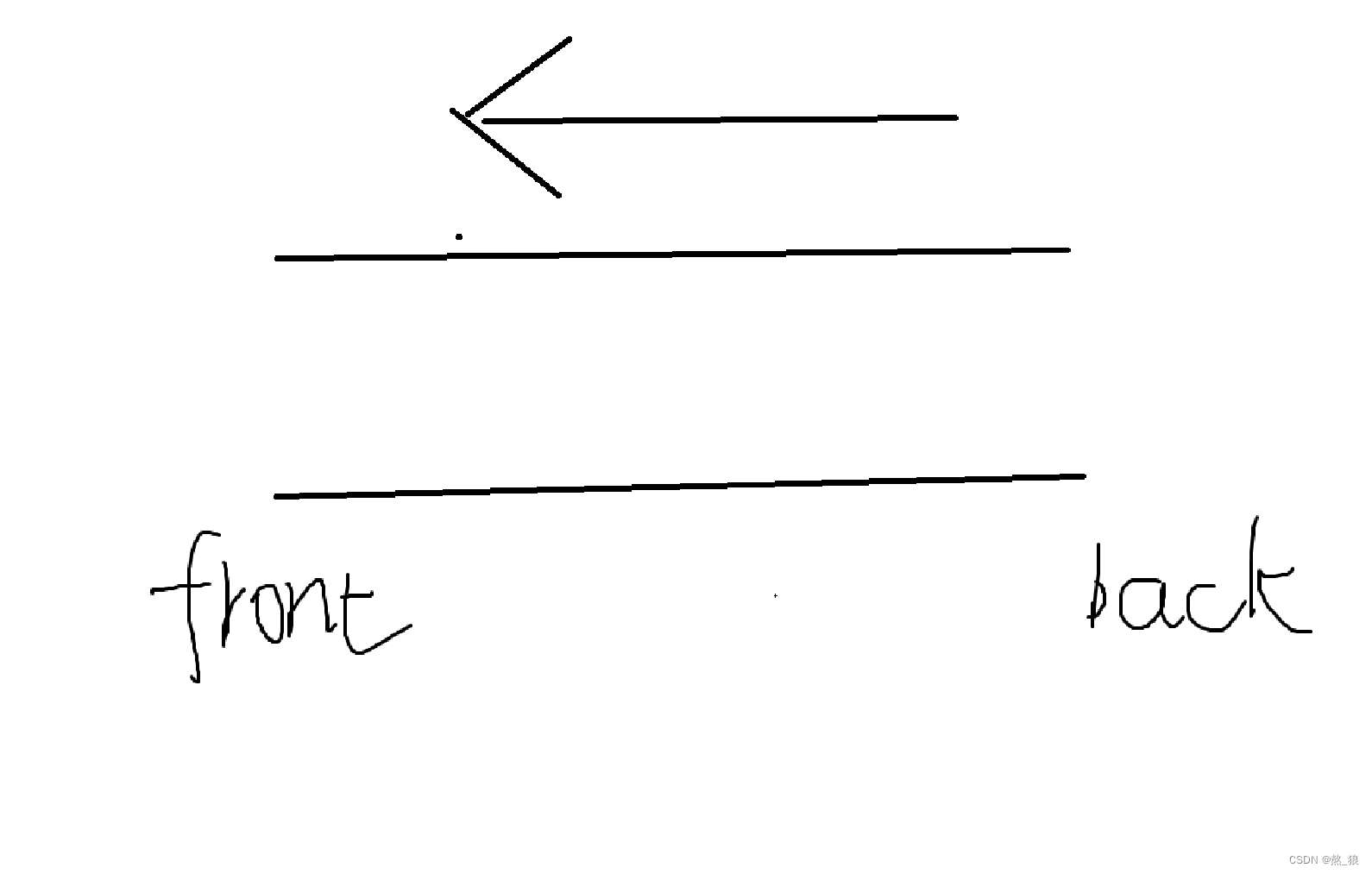
下边给出整体的代码:
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int> > result;
queue<TreeNode*> que;
if(root == NULL)
return result;
que.push(root);
while(!que.empty())
{
vector<int> vec;
size_t size = que.size();
while(size--)
{
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if(node->left) que.push(node->left);
if(node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};que(定义的队列),这个就是用来储存每一层中的元素,并且把每一层中的元素输出出去。存到vec这个一维数组中,再把vec存到这个二维数组result中。
在存储的时候,我们要先记录一下这个队列的当前的元素个数,以便我们准确的储存一层数据。
在存到一维数组的过程中,用一个临时的node来保存队头,把队头中的元素尾插到vec数组中,再把队头删去,在插入的过程中,不断把node的左节点和右节点放入que中。
最终这个队列的大小为空的时候,就是我们遍历结束的时候,大家不妨模拟一下这个过程。
我们以此图为例:




最终队列清空,我们得出来一个二维数组result,并把这个结果返回回去。
其实力扣上有很多题目都是可以通过层序遍历解决的,列举了一些题目,大家可以尝试自行解决一下。
其实学会了层序遍历,我们很容易以此为模板,打十来个不成问题。
“我要打 ’十‘ 个”

力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
题目一:给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。
示例 1:

输入:root = [3,9,20,null,null,15,7] 输出:[3.00000,14.50000,11.00000] 解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。 因此返回 [3, 14.5, 11] 。
示例 2:

输入:root = [3,9,20,15,7] 输出:[3.00000,14.50000,11.00000]
这道题目很明显,我们使用层序遍历的方式是最为简单的,计算每一层的元素的和,同时记录一下这一层的元素的个数,然后把他们相除得出平均值,再存到result的数组中。
这里给出整体性的代码。
class Solution {
public:
vector<double> averageOfLevels(TreeNode* root) {
vector<double> result;
queue<TreeNode*> que;
if(root != NULL)
{
que.push(root);
}
while(!que.empty())
{
double sum = 0;
size_t size = que.size();
for(int i = 0;i<size;i++)
{
TreeNode* node = que.front();
que.pop();
sum += node->val;
if(node->left)que.push(node->left);
if(node->right)que.push(node->right);
}
result.push_back(sum/size);
}
return result;
}
};这个就是在遍历每一层的时候,用result数组来存储每一层的平均值,最后返回这个result数组。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:

输入: [1,2,3,null,5,null,4] 输出: [1,3,4]
示例 2:
输入: [1,null,3] 输出: [1,3]
示例 3:
输入: [] 输出: []
这个题目的意思就是从右边看,我们能看到哪个结点,然后把他们存到一个数组中返回就行了。
给出整体性的代码。
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
vector<int> result;
queue<TreeNode*> que;
if(root != NULL)que.push(root);
while(!que.empty())
{
size_t size = que.size();
for(int i = 0;i<size;i++)
{
TreeNode* node = que.front();
que.pop();
if(i == size-1)
{
result.push_back(node->val);
}
if(node->left)que.push(node->left);
if(node->right)que.push(node->right);
}
}
return result;
}
};这个并不困难,对于把左右结点的放入的顺序和之前也是一样的,读者可自行完成。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:

输入:root = [1,null,3,2,4,null,5,6] 输出:[[1],[3,2,4],[5,6]]
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
这道题只是把二叉树换成了n叉树而已,有多少叉我挨着加进去不就好了嘛。
class Solution {
public:
vector<vector<int>> levelOrder(Node* root) {
vector<vector<int> > result;
queue<Node*> que;
if(root == NULL)
return result;
que.push(root);
while(!que.empty())
{
vector<int> vec;
size_t size = que.size();
while(size--)
{
Node* node = que.front();
que.pop();
vec.push_back(node->val);
for(int i = 0;i<node->children.size();i++)
{
if(node->children[i])
que.push(node->children[i]);
}
}
result.push_back(vec);
}
return result;
}
};
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例1:

输入: root = [1,3,2,5,3,null,9] 输出: [1,3,9]
示例2:
输入: root = [1,2,3] 输出: [1,3]
这个题目和之前的题目很相似,只是遍历的时候,不断记录每一层的最大值就可以了。
整体代码如下:
class Solution {
public:
vector<int> largestValues(TreeNode* root) {
vector<int> result;
queue<TreeNode*>que;
if(root == NULL)
return result;
que.push(root);
while(!que.empty())
{
int max = que.front()->val;
size_t size = que.size();
while(size--)
{
TreeNode* node = que.front();
que.pop();
max = max>node->val?max:node->val;
if(node->left )que.push(node->left);
if(node->right) que.push(node->right);
}
result.push_back(max);
}
return result;
}
};
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例 1:

输入:root = [1,2,3,4,5,6,7] 输出:[1,#,2,3,#,4,5,6,7,#] 解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
示例 2:
输入:root = [] 输出:[]
首先,我们需要明确——完美二叉树也被称为满二叉树,其定义是每层都是满的,像一个稳定的三角形。所以请不要一脸懵。
下面给出整体性的代码:
class Solution {
public:
Node* connect(Node* root) {
queue<Node*> que;
if(root != NULL)
que.push(root);
while(!que.empty())
{
size_t size = que.size();
Node* node = NULL;
Node* prenode = NULL;
for(int i = 0;i<size;i++)
{
if(!i)
{
prenode = que.front();
que.pop();
node = prenode;
}
else
{
node = que.front();
que.pop();
prenode->next = node;
prenode = prenode->next;
}
if(node->left)que.push(node->left);
if(node->right)que.push(node->right);
}
node->next = NULL;
}
return root;
}
};这里用来双指针的思路,prenode和node就是用来记录每一层的结点和控制他们之间的联系,当然每一层的第一个结点需要特殊处理。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 1:

输入:root = [3,9,20,null,null,15,7] 输出:3
示例 2:
输入:root = [1,null,2] 输出:2
这道题我们既可以使用广度优先遍历(层序遍历),又可以使用深度优先遍历。
广度优先遍历:
class Solution {
public:
int maxDepth(TreeNode* root) {
queue<TreeNode*> que;
int depth = 0;
if(root != NULL)
que.push(root);
while(!que.empty())
{
depth++;
size_t size = que.size();
while(size--)
{
TreeNode* node = que.front();
que.pop();
if(node->left)que.push(node->left);
if(node->right)que.push(node->right);
}
}
return depth;
}
};最大深度,并不难,只要每次遍历一层时候加一就可以了。
深度优先搜素:
class Solution {
private:
int getheight(TreeNode* node)
{
if(node == NULL) return 0;
return 1+max(getheight(node->left),getheight(node->right));
}
public:
int maxDepth(TreeNode* root) {
return getheight(root);
}
};这段代码可能读者会有点看不懂。实际上,不要觉得他有多高大上。有人说:递归很简单,我会判断边界,中间过程但是看不懂一点。的确,真的有相当一部分人(包括我自己)也搞不懂递归的逻辑,有时我就感觉他是个反人类的东西,但不得不承认,人家确实好用。
这个代码与其说是计算深度,不如说是计算高度的,因为我们的这段代码就是把叶子结点看作是第一层(或者说把叶子结点的下一个空看作是0),这样向上回溯得到整个树的高度。整个树的高度等于他的深度。所以,这种做法也是非常合理的。
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
示例 1:

输入:root = [3,9,20,null,null,15,7] 输出:2
示例 2:
输入:root = [2,null,3,null,4,null,5,null,6] 输出:5
做过最大深度之后,我们再来看看这里的最小的深度,当然也有广度优先搜索和深度优先搜素。
广度优先搜素:
class Solution {
public:
int minDepth(TreeNode* root) {
queue<TreeNode*> que;
if(root != NULL)
que.push(root);
int depth = 0;
while(!que.empty())
{
size_t size = que.size();
depth++;
for(int i = 0;i<size;i++)
{
TreeNode* node = que.front();
que.pop();
if(node->left)que.push(node->left);
if(node->right)que.push(node->right);
if(node->left == NULL&&node->right == NULL)
return depth;
}
}
return depth;
}
};我们在最大深度的基础上做出改进,只要在层序遍历的时候碰到了叶子节点,我们就返回这个深度,那么他就是最小的深度了。
深度优先搜索:
class Solution {
public:
int minDepth(TreeNode* root) {
if(root == NULL)return 0;
if(root->left == NULL&&root->right == NULL)return 1;
int m1 = minDepth(root->left);
int m2 = minDepth(root->right);
if(root->left==NULL||root->right==NULL)return m1+m2+1;
return min(m1,m2)+1;
}
};给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:

输入:root = [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1]
示例 2:
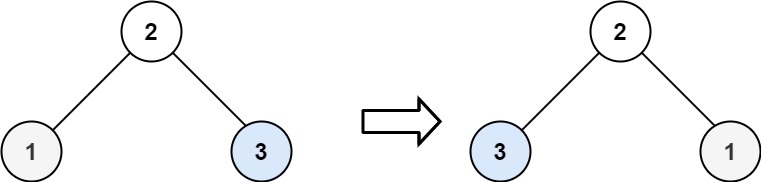
输入:root = [2,1,3] 输出:[2,3,1]
示例 3:
输入:root = [] 输出:[]
给出一个整体性的代码。
这里,我们既可以使用栈,也可以使用队列。因为我们只需要把整个树给记录的同时,反转一下他们的左右结点可以了。
栈:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
stack<TreeNode*> st;
if(root != NULL)
st.push(root);
while(!st.empty())
{
TreeNode* node = st.top();
swap(node->left,node->right);
st.pop();
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
}
return root;
}
};队列:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
queue<TreeNode*> que;
if(root != NULL)
que.push(root);
while(!que.empty())
{
size_t size = que.size();
while(size--)
{
TreeNode* node = que.front();
swap(node->left,node->right);
que.pop();
if(node->left)que.push(node->left);
if(node->right)que.push(node->right);
}
}
return root;
}
};我个人感觉这两个做法没有什么太大的区别,只是所用的数据结构不一样罢了,正所谓“回”字有不少写法,会一种就行了。
关于二叉树的遍历,先写到这里,因为二叉树的东西有点多,如果是一篇写完的话,实在是太难为人了,而且这一篇写的也挺长的了,一万二千多了。
所以我决定按照一定的顺序,一边学一边写,争取能把二叉树的知识给记录一遍。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









