







一、MongoDB 集群简介
MongoDB是一个基于分布式文件存储的数据库,其目的在于为WEB应用提供可扩展的高性能数据存储解决方案。下面将以3台机器介绍最常见的集群方案。具体介绍,可以查看官网 https://docs.mongodb.com/v3.4/introduction/。
1、集群组件的介绍
-
**mongos(路由处理):**作为Client与MongoDB集群的请求入口,所有用户请求都会透过Mongos协调,它会将数据请求发到对应的Shard(mongod)服务器上,再将数据合并后回传给用户。
-
**config server(配置节点):**即:配置服务器;主要保存数据库的元数据,包含数据的分布(分片)以及数据结构,mongos收到client发出的需求后,会从config server加载配置信息并缓存于内存中。 一般在生产环境会配置不只一台config server,因为它保存的元数据极为重要,若损坏则影响整个集群运作。
-
**shard(分片实例存储数据):**shard就是分片。MongoDB利用分片的机制来实现数据分布存储与处理,达到横向扩容的目的。默认情况下,数据在分片之间会自动进行移转,以达到平衡,此动作是靠一个叫平衡器(balancer)的机制达成。
-
**replica set(副本集):**副本集实现了数据库高可用,若没做副本集,则一旦存放数据的服务器节点挂掉,数据就丢失了,相反若配置了副本集,则同样的数据会保存在副本服务器中(副本节点),一般副本集包含了一个主节点与多个副本节点,必要时还会配置arbiter(仲裁结点)作为节点挂掉时投票用。
-
**arbiter(仲裁节点):**仲裁服务器本身不包含数据,仅能在主节点故障时,检测所有副本服务器并选举出新的主节点,其实现方式是通过主节点、副本节点、仲裁服务器之间的心跳(Heart beat)实现。
2、MongoDB应用场景
-
网站数据:适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
-
缓存:由于性能很高,也适合作为信息基础设施的缓存层。在系统重启之后,搭建的持久化缓存可以避免下层的数据源过载。
-
大尺寸、低价值的数据:使用传统的关系数据库存储一些数据时可能会比较贵,在此之前,很多程序员往往会选择传统的文件进行存储。
-
高伸缩性的场景:非常适合由数十或者数百台服务器组成的数据库。
-
用于对象及JSON数据的存储:MongoDB的BSON数据格式非常适合文档格式化的存储及查询。
3、选用MongoDB的缘由
选用MongoDB的数据是以BSON的数据格式,高度伸缩方便扩展,并且数据水平扩展非常简单,支持海量数据存储,性能强悍。
二、集群的监测
1、监测数据库存储统计信息
docker中进入mongos或shard实例,执行以下命令:
docker exec -it mongos bash;
mongo --port 20001;
use admin;
db.auth("root","XXX");
说明:通过此命令,可以查询集群的成员的集合数量、索引数量等相关数据。
db.stats();
2、查看数据库的统计信息
说明:通过此命令,可以查看操作数量、内存使用状况、网络io等
db.runCommand( { serverStatus: 1 } );
3、检查复制集成员状态
rs.status();
三、基本的运维操作
1、设置和查看慢查询
# 设置慢查询
db.setProfilingLevel(1,200);
# 查看慢查询级别
db.getProfilingLevel();
# 查询慢查询日志,此命令是针对于某一库进行设置
db.system.profile.find({ ns : 'dbName.collectionName'}).limit(10).sort( { ts : -1 } ).pretty();
2、查看执行操作时间较长的动作
db.currentOp({"active" : true,"secs_running" : { "$gt" : 2000 }});
3、动态调整日志级别和设置缓存大小
# 设置日志级别参数
db.adminCommand( { "getParameter": 1, "logLevel":1});
# 设置cache大小参数
db.adminCommand( { "setParameter": 1, "wiredTigerEngineRuntimeConfig": "cache_size=4G"});
4、添加和移除复制集成员
# 查看复制集成员
rs.status().members;
# 添加成员
rs.add('127.0.0.1:20001');
# 移除成员
rs.remove('127.0.0.1:20001');
5、设置数据库和集合分片
# 在mongos admin库设置库允许分片
sh.enableSharding("dbName");
# 在mongos 的admin库设置集合分片片键
sh.shardCollection("dbName.collectionName", { filedName: 1} );
6、添加和移除分片
# 查看分片状态
sh.status();
# 在mongos执行添加分片(可以为单个实例或复制集)
db.runCommand( { removeShard: "shardName" } );
db.runCommand({addshard:"rs1/ip-1:20001,ip-2:20001,ip-3:20001"});
# 在mongos执行移除分片
db.runCommand( { removeShard: "shard3" } );
# 在mongos执行刷新mongos配置信息
db.runCommand("flushRouterConfig"));
说明:移除分片命令至少执行两次才能成功删除,执行到state为completed才真正删除,否则就是没用删除成功,该分片处于{"draining" : true}状态,该状态下不但该分片没用删除成功,而且还影响接下来删除其他分片操作,遇到该状态再执行一次removeshard即可,最好就是删除分片时一直重复执行删除命令,直到state为completed; 还有一个需要注意的地方就是:被成功删除的分片如果想要再加入集群时,必须将data数据目录清理干净才可以再加入集群,否则即使能加入成功也不会存储数据,集合都不会被创建 另外:在删除分片的时有可能整个过程出现无限{"draining" : true}状态,等多久还是这样,而且分片上面的块一个都没有移动到别的分片,解决办法是:在config的config数据库的shard集合中找到该分片的信息,并将draining字段由True改为False,再继续试着删除操作” 上面这句会立即返回,实际在后台执行。 在数据移除的过程当中,一定要注意实例的日志信息,可能出现数据块在迁移的过程中,始终找不到边界条件,导致一直数据迁移不成功,一直重试,解决方案是删除边界数据,重启实例;。如果此分片为主分片,需要先迁移主分片。db.runCommand( { movePrimary: "XXX", to: "other" });在完成删除后,所有mongos上运行下面命令,再对外提供服务,当然也可以重新启动所有mongos实例 。
7、数据的导入导出
# 导出允许指定导出条件和字段
mongoexport -h 127.0.0.1 --port 20001 -uxxx -pxxx -d xxx -c mobileIndex -o XXX.txt
mongoimport -h 127.0.0.1 --port 20001 -uxxx -pxxx -d xxx -c mobileIndex --file XXX.txt
四、MongoDB数据迁移
1、迁移复制集当中的成员
-
关闭 mongod 实例,为了确保安全关闭,使用 shutdown 命令;
-
将数据目录(即 dbPath )转移到新机器上;
-
在新机器上启动 mongod,其中节点的数据目录为copy的文件目录 ;
-
连接到复制集当前的主节点上;
如果新节点的地址发生变化,使用 rs.reconfig() 更新 复制集配置文档 ; 举例,下面的命令过程将成员中位于第 2 位的地址进行更新:
cfg = rs.conf()
cfg.members[2].host = "127.0.0.1:27017"
rs.reconfig(cfg)
使用 rs.conf() 确认使用了新的配置. 等待所有成员恢复正常,使用 rs.status() 检测成员状态。
2、迁移复制集主节点
在迁移主节点的时候,需要复制集选举出一个新的主节点,在进行选举的时候,复制集将读写,通常,这只会持续很短的时间,不过,应该尽可能在影响较小的时间段内迁移主节点.
- 主节点降级,以使得正常的 failover开始.要将主节点降级,连接到一个主节点,使用
replSetStepDown方法或者使用rs.stepDown()方法,下面的例子使用了rs.stepDown()方法进行降级:
rs.stepDown()
- 等主节点降级为从节点,另一个成员成为
PRIMARY之后,可以按照 “迁移复制集的一个成员”迁移这个降级了的节点.可以使用rs.status()来确认状态的改变。
3、从复制集其他节点恢复数据
MongoDB 通过复制集能保证高可靠的数据存储,通常生产环境建议使用「3节点复制集」,这样即使其中一个节点崩溃了无法启动,我们可以直接将其数据清掉,重新启动后,以全新的 Secondary 节点加入复制集,或者是将其他节点的数据复制过来,重新启动节点,它会自动的同步数据,这样也就达到了恢复数据的目的。
- 关闭需要数据同步的节点
docker stop node; # docker环境中
db.shutdownServer({timeoutSecs: 60}); # 非docker环境
- 拷贝目标节点机器的数据存储目录(/dbPath)到当前机器的指定目录。
scp 目标节点 shard/data -> 当前节点 shard/data
-
当前节点以复制过来的数据文件启动节点
-
将新的节点添加到复制集
# 进入复制集的主节点,执行添加新的节点命令
rs.add("hostNameNew:portNew");
# 等待所有成员恢复正常,检测成员状态
rs.status();
# 移除原来的节点
rs.remove("hostNameOld>:portOld");
五、MongoDB线上问题场景解决
1、MongoDB 新建索引导致库被锁
问题说明:某线上千万级别集合,为优化业务,直接执行新建索引命令,导致整个库被锁,应用服务出现不可用。
解决方案:找出此操作进程,并且杀死。改为后台新建索引,速度很会慢,但是不会影响业务,该索引只会在新建完成之后,才会生效;
# 查询运行时间超过200ms操作
db.currentOp({"active" : true,"secs_running" : { "$gt" : 2000 }}) ;
# 杀死执行时间过长操作操作
db.killOp(opid)
# 后台新建索引
db.collectionNmae.ensureIndex({filedName:1}, {background:true});
2、MongoDB没有限制内存,导致实例退出
问题说明:生产环境某台机器启动多个mongod实例,运行一段时间过后,进程莫名被杀死;
解决方案:现在MongoDB使用WiredTiger作为默认存储引擎,MongoDB同时使用WiredTiger内部缓存和文件系统缓存。从3.4开始,WiredTiger内部缓存默认使用较大的一个:50%(RAM - 1 GB),或256 MB。 例如,在总共4GB RAM的系统上,WiredTiger缓存将使用1.5GB的RAM()。相反,具有总共1.25 GB RAM的系统将为WiredTiger缓存分配256 MB,因为这超过总RAM的一半减去1千兆字节()。0.5 * (4 GB - 1GB) = 1.5 GB``0.5 * (1.25 GB - 1 GB) = 128 MB < 256 MB。如果一台机器存在多个实例,在内存不足的情景在,操作系统会杀死部分进程;
# 要调整WiredTiger内部缓存的大小,调节cache规模不需要重启服务,我们可以动态调整:
db.adminCommand( { "setParameter": 1, "wiredTigerEngineRuntimeConfig": "cache_size=xxG"})
3、MongoDB删除数据,不释放磁盘空间
问题说明:在删除大量数据(本人操作的数据量在2000万+)的情景下,并且在生产环境中请求量较大,此时机器的cpu负载会显得很高,甚至机器卡顿无法操作,这样的操作应该谨慎分批量操作;在删除命令执行结束之后,发现磁盘的数据量大小并没有改变。
解决方案:
-
方案一:我们可以使用MongoDB提供的在线数据收缩的功能,通过Compact命令
db.collectionName.runCommand("compact")进行Collection级别的数据收缩,去除集合所在文件碎片。此命令是以Online的方式提供收缩,收缩的同时会影响到线上的服务。为了解决这个问题,可以先在从节点执行磁盘整理命令,操作结束后,再切换主节点,将原来的主节点变为从节点,重新执行Compact命令即可。 -
方案二:使用从节点重新同步,secondary节点重同步,删除secondary节点中指定数据,使之与primary重新开始数据同步。当副本集成员数据太过陈旧,也可以使用重新同步。数据的重新同步与直接复制数据文件不同,MongoDB会只同步数据,因此重同步完成后的数据文件是没有空集合的,以此实现了磁盘空间的回收。
针对一些特殊情况,不能下线secondary节点的,可以新增一个节点到副本集中,然后secondary就自动开始数据的同步了。总的来说,重同步的方法是比较好的,第一基本不会阻塞副本集的读写,第二消耗的时间相对前两种比较短。
-
若是primary节点,先强制将之变为secondary节点,否则跳过此步骤:
rs.stepdown(120); -
然后在primary上删除secondary节点:
rs.remove("IP:port"); -
删除secondary节点dbpath下的所有文件
-
将节点重新加入集群,然后使之自动进行数据的同步:
rs.add("IP:port"); -
等数据同步完成后,循环1-4的步骤可以将集群中所有节点的磁盘空间释放
-
4、MongoDB机器负载极高
问题说明:此情景是在客户请求较大的情景性,由于部署MongoDB的机器包含一主一从,MongoDB使得IO100%,数据库阻塞,出现大量慢查询,进而导致机器负载极高,应用服务完全不可用。
解决方案:在没有机器及时扩容的状况下,首要任务便是减小机器的IO,在一台机器出现一主一从,在大量数据写入的情况下,会互相抢占IO资源。于是此时摒弃了MongoDB高可用的特点,摘掉了复制集当中的从节点,保证每台机器只有一个节点可以占用磁盘资源。之后,机器负载立马下来,服务变为正常可用状态,但是此时MongoDB无法保证数据的完整性,一旦有主节点挂掉便会丢失数据。此方案只是临时方法,根本解决是可以增加机器的内存、使用固态硬盘,或者采用增加分片集来减少单个机器的读写压力。
# 进入主节点,执行移除成员的命令
rs.remove("127.0.0.1:20001");
# 注意:切勿直接关停实例
5、MongoDB分片键选择不当导致热读热写
问题说明:生产环境中,某一集合的片键使用了与_id生成方式相似,含有时间序列的字段作为升序片键,导致数据写入时都在一个数据块,随着数据量增大,会造成数据迁移到前面的分区,造成系统资源的占用,偶尔出现慢查询。
解决方案:临时方案设置数据迁移的窗口,放在在正常的时间区段,对业务造成影响。根本解决是更换片键。
# 连接mongos实例,执行以下命令
db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "23:00", stop : "4:00" } } }, true );
# 查看均衡窗口
sh.getBalancerWindow();
六、MongoDB优化建议
1、应用层面优化
查询优化:确认你的查询是否充分利用到了索引,用explain命令查看一下查询执行的情况,添加必要的索引,避免扫表操作。
合理设计分片键:增量sharding-key:适合于可划分范围的字段,比如integer、float、date类型的,查询时比较快。随机sharding-key: 适用于写操作频繁的场景,而这种情况下如果在一个shard上进行会使得这个shard负载比其他高,不够均衡,故而希望能hash查询key,将写分布在多个shard上进行,考虑复合key作为sharding key, 总的原则是查询快,尽量减少跨shard查询,balance均衡次数少;单一递增的sharding key,可能会造成写数据全部在最后一片上,最后一片的写压力增大,数据量增大,会造成数据迁移到前面的分区。MongoDB默认是单条记录16M,尤其在使用GFS的时候,一定要注意shrading-key的设计。不合理的sharding-key会出现,多个文档,在一个chunks上,同时,因为GFS中存贮的往往是大文件,导致MongoDB在做balance的时候无法通过sharding-key来把这多个文档分开到不同的shard上, 这时候MongoDB会不断报错最后导致MongoDB倒掉。解决办法:加大chunks大小(治标),设计合理的sharding-key(治本)。
通过profile来监控数据:进行优化查看当前是否开启profile功能 用命令db.getProfilingLevel() 返回level等级,值为0|1|2,分别代表意思:0代表关闭,1代表记录慢命令,2代表全部。开启profile功能命令为 db.setProfilingLevel(level); #level等级,值level为1的时候,慢命令默认值为100ms,更改为db.setProfilingLevel(level,slowms)如db.setProfilingLevel(1,50)这样就更改为50毫秒通过db.system.profile.find() 查看当前的监控日志。
2、硬件层面优化
2.1 确定热数据大小:可能你的数据集非常大,但是这并不那么重要,重要的是你的热数据集有多大,你经常访问的数据有多大(包括经常访问的数据和所有索引数据)。使用MongoDB,你最好保证你的热数据在你机器的内存大小之下,保证内存能容纳所有热数据; 2.2 选择正确的文件系统:MongoDB的数据文件是采用的预分配模式,并且在Replication里面,Master和Replica Sets的非Arbiter节点都是会预先创建足够的空文件用以存储操作日志。这些文件分配操作在一些文件系统上可能会非常慢,导致进程被Block。所以我们应该选择那些空间分配快速的文件系统。这里的结论是尽量不要用ext3,用ext4或xfs;
3、架构上的优化
尽可能让主从节点分摊在不同的机器上,避免IO操作的与MongoDB在同一台机器;
七、总结
MongoDB具有高性能、易扩展、易上手等特点,在正确使用的情况下,其本身性能还是非常强悍,在一些关键点如片键的选择、内存的大小和磁盘IO,往往是限制其性能的最大瓶颈。针对于片键,在业务系统初期,可以先不对集合进行数据分片,因为分片键一旦确定就无法修改,后期可根据业务系统的情况,认真筛选字段。一般情况下,不建议使用升序片键(是一种随着时间稳定增长的字段,自增长的主键是升序键 ),因为这个会导致局部的热读热写,不能发挥分片集群的真正实力。建议使用hash片键或者随机分发的片键,这样可以保证数据的均匀分发在分片节点;针对于内存,建议内存的大小能够包含热数据的大小加索引大小,保证内存能容纳所有热数据 。针对于磁盘资源,MongoDB的高速读写是以磁盘的IO作为基础,为了保证其性能,建议将主从节点以及高IO的应用分离,以保证IO资源尽可能不存在抢占。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
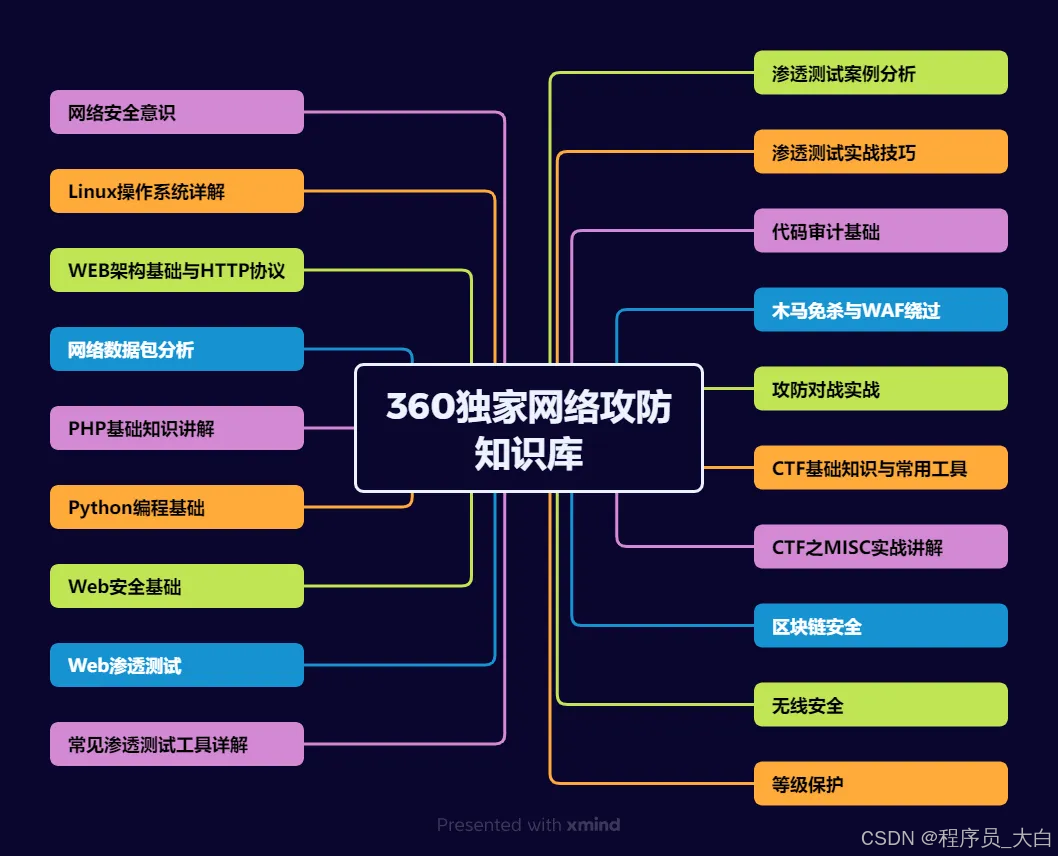
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









