






图(Graph)是一种重要的数据结构,广泛应用于计算机科学和现实世界的各种问题中,如网络分析、路径规划、社交网络等。图的遍历是图算法的基础,通过遍历我们可以访问图中的所有节点,进而解决许多复杂问题。图的遍历主要有两种方式:深度优先搜索(DFS)和广度优先搜索(BFS)。本文将介绍这两种遍历方法,并提供完整的C语言实现。
图的基本概念
在图论中,图由顶点(Vertex)和边(Edge)组成。根据边的方向性,图可以分为有向图和无向图;根据边的权重,图可以分为带权图和无权图。
- 无向图:边没有方向,表示顶点之间的双向关系。
- 有向图:边有方向,表示顶点之间的单向关系。
图的表示
图在计算机中的表示方法主要有邻接矩阵和邻接表。
- 邻接矩阵:使用一个二维数组表示顶点之间的连接关系。如果顶点i和顶点j之间有边,则matrix[i][j]为1,否则为0。
- 邻接表:使用数组加链表的方式表示图。每个顶点对应一个链表,链表中存放与该顶点相邻的所有顶点。
本文使用邻接表表示图,并实现DFS和BFS算法。
C语言实现
图的结构定义
首先,我们定义图的结构和相关操作。
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTICES 100
// 邻接表中的节点
typedef struct AdjListNode {
int dest;
struct AdjListNode* next;
} AdjListNode;
// 邻接表
typedef struct AdjList {
AdjListNode* head;
} AdjList;
// 图结构
typedef struct Graph {
int numVertices;
AdjList* array;
} Graph;
// 创建一个新的邻接表节点
AdjListNode* newAdjListNode(int dest) {
AdjListNode* newNode = (AdjListNode*)malloc(sizeof(AdjListNode));
newNode->dest = dest;
newNode->next = NULL;
return newNode;
}
// 创建一个图,包含V个顶点
Graph* createGraph(int V) {
Graph* graph = (Graph*)malloc(sizeof(Graph));
graph->numVertices = V;
// 创建邻接表
graph->array = (AdjList*)malloc(V * sizeof(AdjList));
for (int i = 0; i < V; ++i)
graph->array[i].head = NULL;
return graph;
}
// 向图中添加边
void addEdge(Graph* graph, int src, int dest) {
// 添加从src到dest的边
AdjListNode* newNode = newAdjListNode(dest);
newNode->next = graph->array[src].head;
graph->array[src].head = newNode;
// 如果是无向图,添加从dest到src的边
newNode = newAdjListNode(src);
newNode->next = graph->array[dest].head;
graph->array[dest].head = newNode;
}
深度优先搜索(DFS)
深度优先搜索是一种遍历或搜索图的算法,从起始节点开始,沿着一条路径向前走,直到无法继续为止,然后回溯到上一个节点,继续寻找新的路径。
// 深度优先搜索的递归实现
void DFSUtil(Graph* graph, int v, int visited[]) {
visited[v] = 1;
printf("%d ", v);
AdjListNode* crawl = graph->array[v].head;
while (crawl) {
int adjVertex = crawl->dest;
if (!visited[adjVertex])
DFSUtil(graph, adjVertex, visited);
crawl = crawl->next;
}
}
// 深度优先搜索的初始化函数
void DFS(Graph* graph, int startVertex) {
int* visited = (int*)malloc(graph->numVertices * sizeof(int));
for (int i = 0; i < graph->numVertices; ++i)
visited[i] = 0;
DFSUtil(graph, startVertex, visited);
free(visited);
}
广度优先搜索(BFS)
广度优先搜索是一种遍历或搜索图的算法,从起始节点开始,先访问所有邻居节点,然后依次访问这些邻居节点的邻居节点。
#include <stdbool.h>
// 广度优先搜索的实现
void BFS(Graph* graph, int startVertex) {
bool* visited = (bool*)malloc(graph->numVertices * sizeof(bool));
for (int i = 0; i < graph->numVertices; ++i)
visited[i] = false;
int* queue = (int*)malloc(graph->numVertices * sizeof(int));
int front = 0, rear = 0;
visited[startVertex] = true;
queue[rear++] = startVertex;
while (front != rear) {
int currentVertex = queue[front++];
printf("%d ", currentVertex);
AdjListNode* crawl = graph->array[currentVertex].head;
while (crawl) {
int adjVertex = crawl->dest;
if (!visited[adjVertex]) {
visited[adjVertex] = true;
queue[rear++] = adjVertex;
}
crawl = crawl->next;
}
}
free(visited);
free(queue);
}
测试函数
最后,我们编写一个测试函数来验证上述图遍历算法。
int main() {
int V = 5;
Graph* graph = createGraph(V);
addEdge(graph, 0, 1);
addEdge(graph, 0, 4);
addEdge(graph, 1, 2);
addEdge(graph, 1, 3);
addEdge(graph, 1, 4);
addEdge(graph, 2, 3);
addEdge(graph, 3, 4);
printf("Depth First Traversal starting from vertex 0:\n");
DFS(graph, 0);
printf("\nBreadth First Traversal starting from vertex 0:\n");
BFS(graph, 0);
return 0;
}
运行结果:
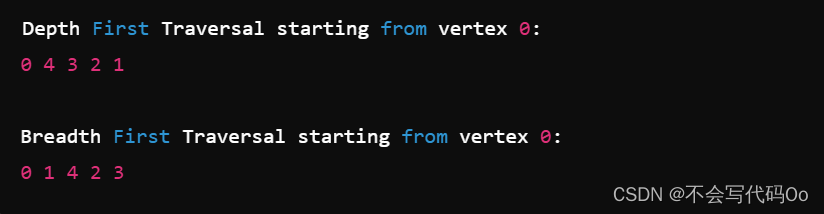
代码讲解
- 图的表示:我们使用邻接表来表示图,每个顶点对应一个链表,链表中存放与该顶点相邻的所有顶点。
- 深度优先搜索(DFS):DFS算法通过递归实现,从起始节点开始,沿着一条路径向前走,直到无法继续为止,然后回溯到上一个节点,继续寻找新的路径。
- 广度优先搜索(BFS):BFS算法通过队列实现,从起始节点开始,先访问所有邻居节点,然后依次访问这些邻居节点的邻居节点。
- 测试函数:我们创建一个包含5个顶点的图,并添加一些边,最后使用DFS和BFS算法遍历图,并输出遍历结果。















 2045
2045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









