







文章目录
前言
上一节博客链接:《MySQL必知必会》个人实现全记录(3)——6~10章-CSDN博客
本节内容:数据处理函数、聚集函数、分组、子查询
第11章:使用数据处理函数
本章介绍什么是函数,MySQL支持何种函数,以及如何使用这些函数。
文本处理函数


SOUNDEX是一个将任何文 本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似 的发音字符和音节,使得能对串进行发音比较而不是字母比较。虽然 SOUNDEX不是SQL概念,但MySQL(就像多数DBMS一样)都提供对 SOUNDEX的支持。
来看两个例子
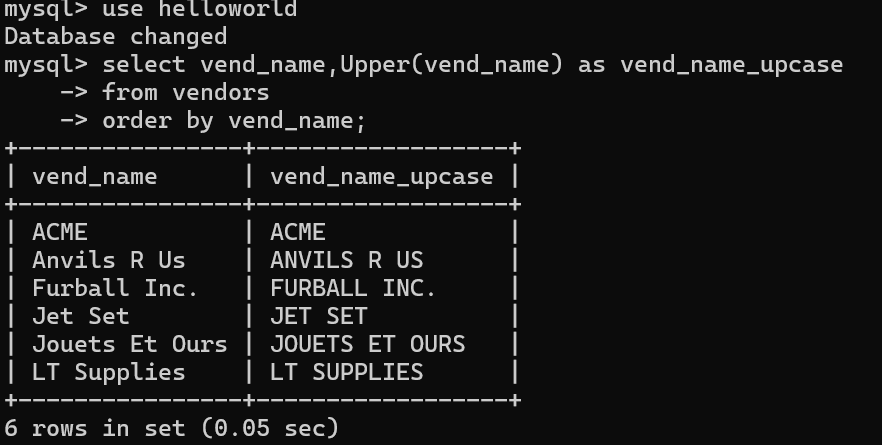
select vend_name,Upper(vend_name) as vend_name_upcase
from vendors
order by vend_name;
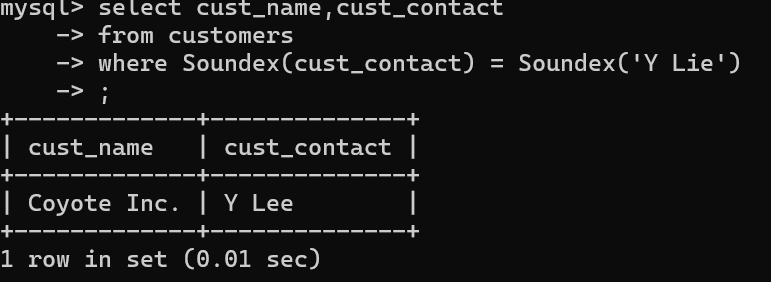
select cust_name,cust_contact
from customers
where Soundex(cust_contact) = Soundex('Y Lie');
第一段代码,效果是把串转化为大写
第二段代码,效果是匹配读音类似于’Y Lie’的串
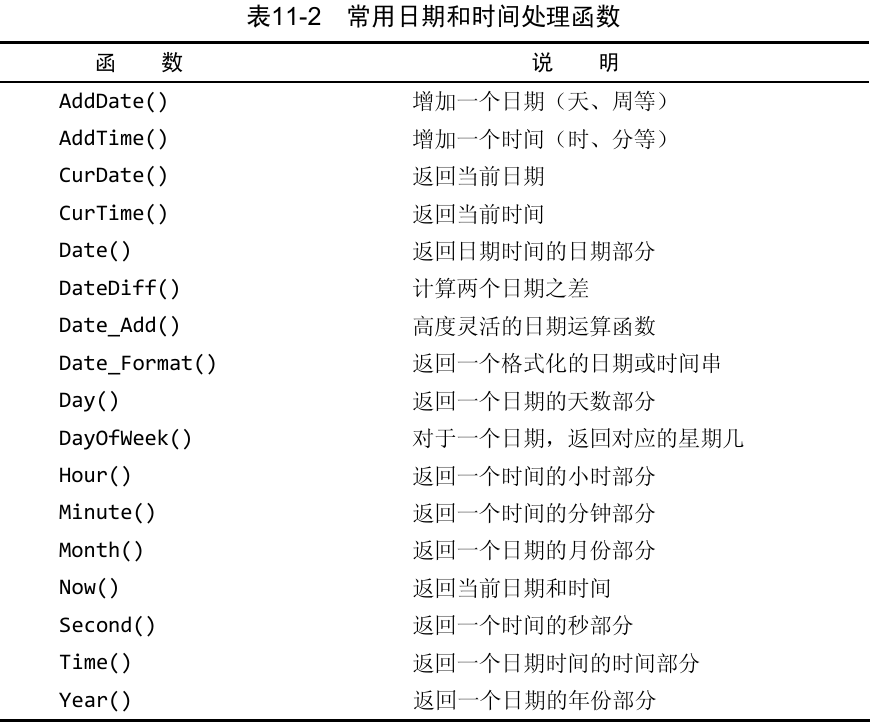
日期处理和时间处理函数
同样是两个例子
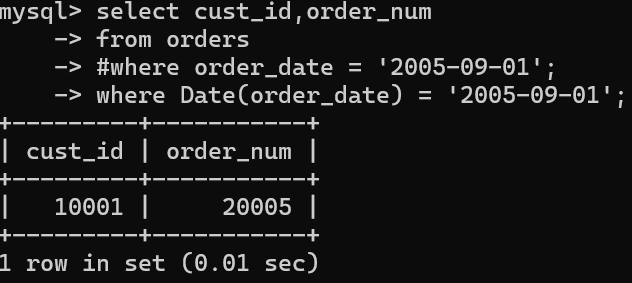
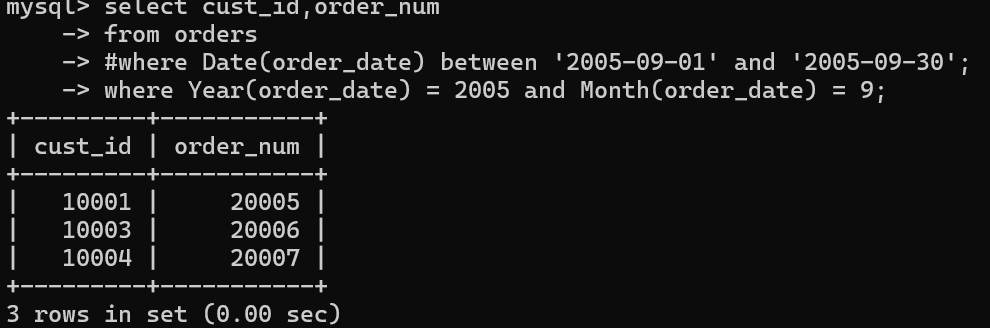
select cust_id,order_num
from orders
#where order_date = '2005-09-01';
where Date(order_date) = '2005-09-01';
select cust_id,order_num
from orders
#where Date(order_date) between '2005-09-01' and '2005-09-30';
where Year(order_date) = 2005 and Month(order_date) = 9;
第一个例子,通过使用date,精确的选取出日期,比注释方法更安全
第二个例子,效果等价于注释部分,筛选出2005年9月的数据
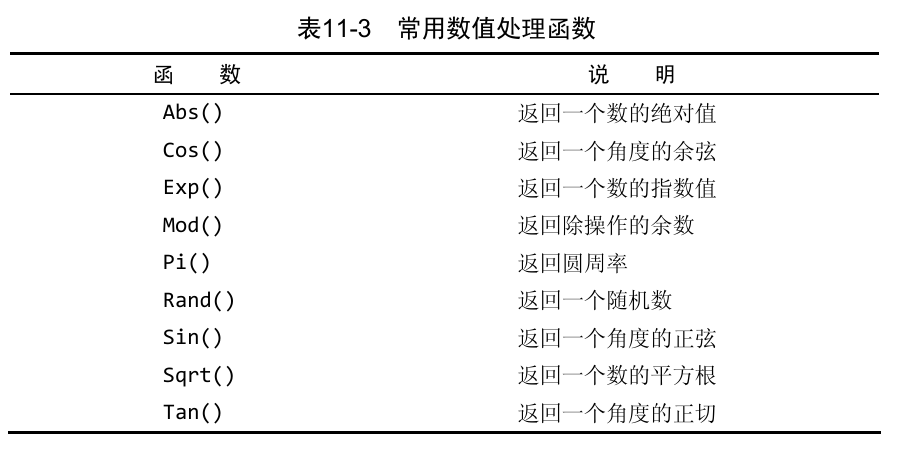
数值处理函数
数值处理函数仅处理数值数据。这些函数一般主要用于代数、三角或几何运算,因此没有串或日期—时间处理函数的使用那么频繁。
第12章:汇总数据
本章介绍什么是SQL的聚集函数以及如何利用它们汇总表的数据。
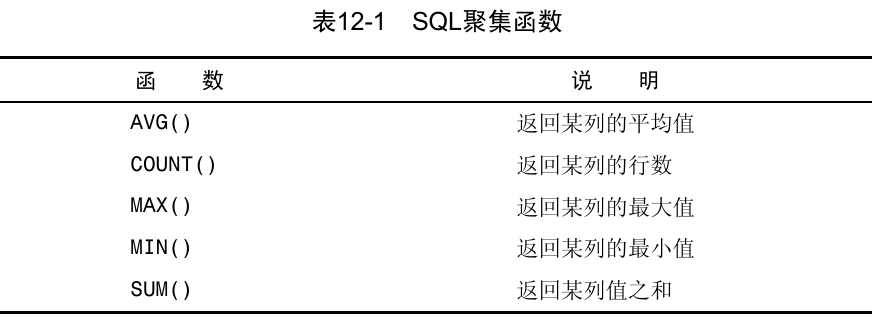
聚集函数
有时,我们只需要汇总后的数据(最大最小平均值、计数、求和),不需要数据本身。Mysql提高了聚集函数,让我们能直接获取汇总后的数据。
MySQL还支持一系列的标准偏差聚集函数,但这本书并未涉及这些内容。
/*AVG函数
*1.AVG()只能用来确定特定数值列的平均值,而
*且列名必须作为函数参数给出。为了获得多个列的平均值,
*必须使用多个AVG()函数。
*2.AVG()函数忽略列值为NULL的行。*/
select avg(prod_price) as avg_price
from products;
#where vend_id = 1003;
/*COUNT函数
*如果指定列名,则指定列的值为空的行被COUNT()
*函数忽略,但如果COUNT()函数中用的是星号(*),则不忽
*略。*/
select count(cust_email) as num_cust
select count(*) as num_cust
from customers;
/*MAX函数
*1.但MySQL允许将它用来返回任意列中的最大
*值,包括返回文本列中的最大值。在用于文本数据时,如果数
*据按相应的列排序,则MAX()返回最后一行。
*2.MAX()函数忽略列值为NULL的行。*/
select max(prod_price) as max_price
from products;
/*MIN函数
*1.MySQL允许将它用来返回任意列中的最小值,包括返回文本
*列中的最小值。在用于文本数据时,如果数据按相应的列排序,
*则MIN()返回最前面的行。
*2.MIN()函数忽略列值为NULL的行。*/
select min(prod_price) as min_price
from products;
/*SUM函数
*1.利用标准的算术操作符,
*所有聚集函数都可用来执行多个列上的计算。
*2.SUM()函数忽略列值为NULL的行。*/
select sum(item_price*quantity) as total_price
from orderitems
where order_num = 20005;
聚集不同值
使用distinct关键字,只考虑非重复部分,重复的只计一次
使用all(或者不使用任何关键字),就是默认行为,对所有行计数
组合聚集函数
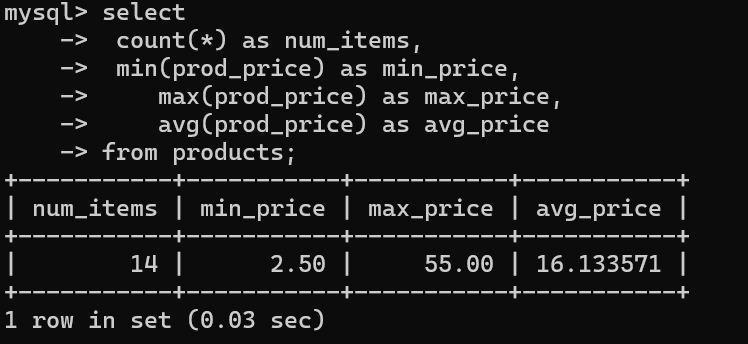
上述聚集函数可以在一个select语句里组合使用
select count(*) as num_items,
min(prod_price) as min_price,
max(prod_price) as max_price,
avg(prod_price) as avg_price
from products;
第13章:分组数据
本章将介绍如何分组数据,以便能汇总表内容的子集。这涉及两个新SELECT语句子句,分别是GROUP BY子句和HAVING子句。
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算。
创建分组
使用group by子句建立分组
要求:
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套, 为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上 进行汇总。换句话说,在建立分组时,指定的所有列都一起计算 (所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式 (但不能是聚集函数)。如果在SELECT中使用表达式,则必须在 GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子 句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列 中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
例子
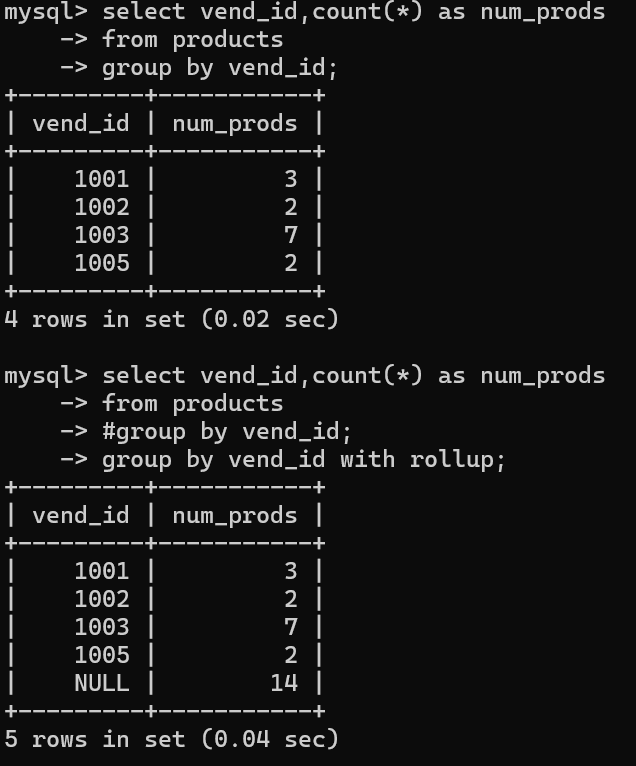
select vend_id,count(*) as num_prods
from products
#group by vend_id;
group by vend_id with rollup;
过滤分组
我们之前使用where过滤行,现在,我们可以用having过滤分组,目前为止所 学过的所有类型的WHERE子句都可以用HAVING来替代。
有另一种理解方法,WHERE在数据 分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重 要的区别,WHERE排除的行不包括在分组中。这可能会改变计 算值,从而影响HAVING子句中基于这些值过滤掉的分组。
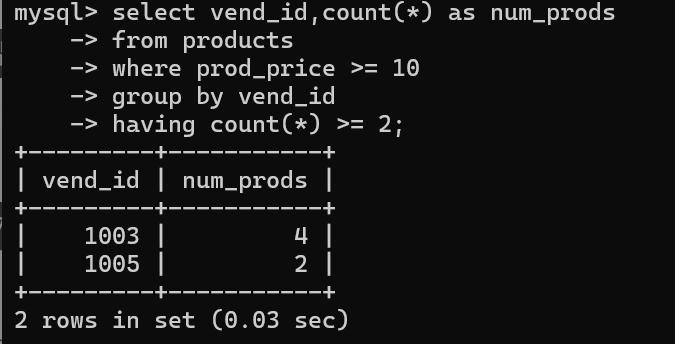
select vend_id,count(*) as num_prods
from products
where prod_price >= 10
group by vend_id
having count(*) >= 2;
上面这个例子,先用where按行过滤出价格在10之上的行,然后把这些行按vend_id分组,接着按分组过滤,过滤出有2个及以上行的组,注意这些组里的行的价格仍然在10之上。
分组和排序

我们经常发现用GROUP BY分 组的数据确实是以分组顺序输出的。但情况并不总是这样,它并不是SQL 规范所要求的。此外,用户也可能会要求以不同于分组的顺序排序。仅 因为你以某种方式分组数据(获得特定的分组聚集值),并不表示你需要 以相同的方式排序输出。应该提供明确的ORDER BY子句,即使其效果等 同于GROUP BY子句也是如此。
一般在使用GROUP BY子句时,应该也给 出ORDER BY子句。这是保证数据正确排序的唯一方法。千万 不要仅依赖GROUP BY排序数据。
SELECT子句顺序


第14章:使用子查询
本章介绍什么是子查询以及如何使用它们。
SELECT语句是SQL的查询。迄今为止我们所看到的所有SELECT语句 都是简单查询,即从单个数据库表中检索数据的单条语句。SQL还允许创建子查询(subquery),即嵌套在其他查询中的查询。
利用子查询进行过滤
#硬编码
select order_num
from orderitems
where prod_id = 'TNT2'; #得到的结果是20005 20007
select cust_id
from orders
where order_num in (20005,20007); #得到的结果是10001 10004
#嵌套
select cust_id
from orders
where order_num in (select order_num
from orderitems
where prod_id = 'TNT2');
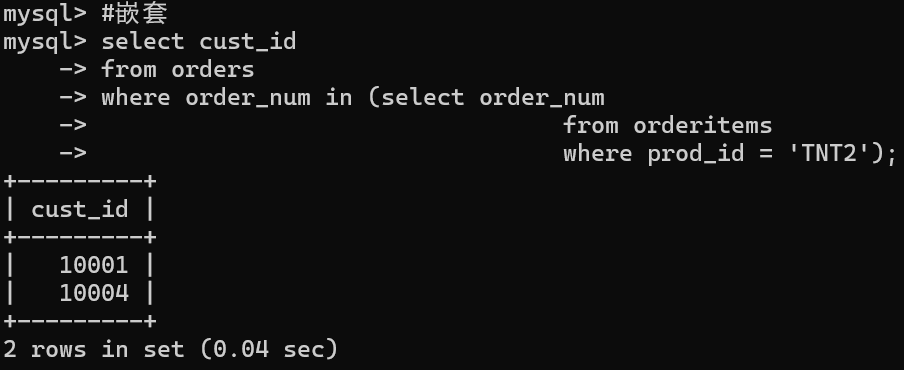
二者等价。
可见,在WHERE子句中使用子查询能够编写出功能很强并且很灵活的 SQL语句。对于能嵌套的子查询的数目没有限制,不过在实际使用时由于 性能的限制,不能嵌套太多的子查询。
在WHERE子句中使用子查询(如这里所示),应 该保证SELECT语句具有与WHERE子句中相同数目的列。通常, 子查询将返回单个列并且与单个列匹配,但如果需要也可以 使用多个列。
虽然子查询一般与IN操作符结合使用,但也可以用于测试等于(=)、 不等于(<>)等。
作为计算字段使用子查询
select cust_name,
cust_state,
(select count(*)
from orders
where orders.cust_id = customers.cust_id) as orders
from customers
order by cust_name;
由于我修改过样例表,下面的结果和课本上的不完全相同
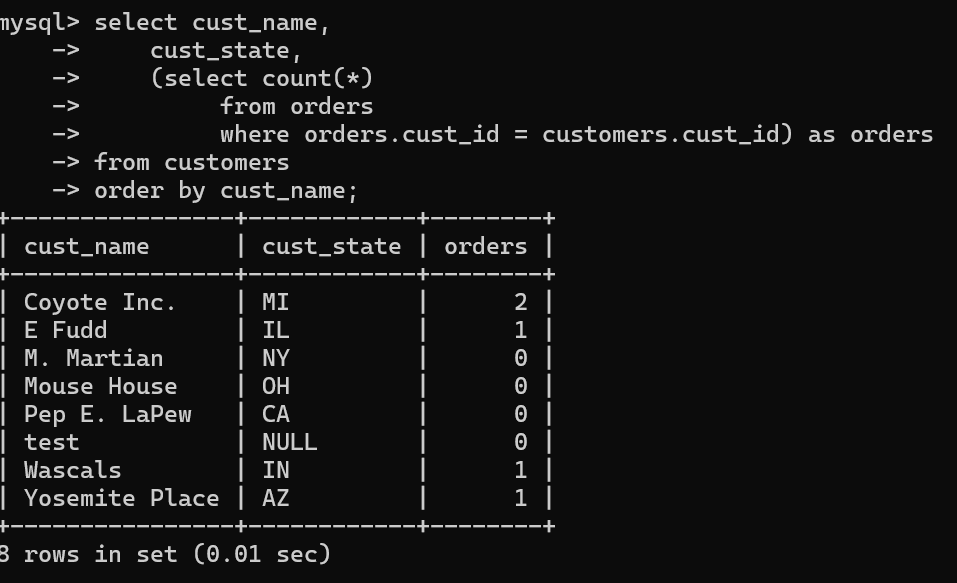
注意,代码使用了完全限定列名,目的是确定列名,避免多义性。涉及到外部查询的子查询被称为相关子查询
结语
本节进一步学习了select语句,这其中最重要的肯定还是子查询,自此我们的查询方法得到了极大的拓展。
下一部分涉及到了联结,也就说明我们从单表环境进入到了多表环境。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









