







本期我们评测AI大模型在教育领域-小学奥数这个场景的应用能力,并输出大模型担任AI老师的综合分析。同时,教育等行业各领域不同类型、不同岗位、不同细分维度的AI数字员工评测,都在爆肝输出中,敬请期待(或者包子们想评测那个岗位,欢迎私信,有求必测!)。
一、评测结论:
*106个大模型实测横评得分区间分布统计表
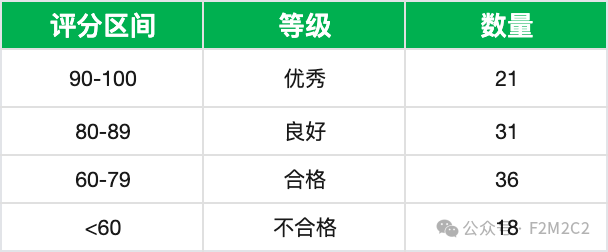
*优秀率/不合格率统计表

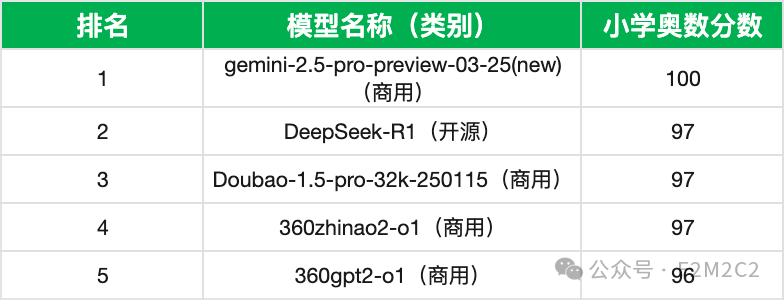
*106个大模型实测横评得分前五名统计表
-
关键结论
-
商用模型垄断头部:
-
前5名中商用占4席,且包揽第1、3、4、5名,领域能力应用优势明显。
-
前5名平均分高达 97.4分(满分100),接近人类专家水平。
-
-
开源模型存在“单点突破”:
-
DeepSeek-R1以97分位列第2,是唯一进入前5的开源模型,但后续断层明显(第6名开源模型得分96分)。
-
-
国产商用模型表现抢眼:
-
360系模型(360zhinao2-o1、360gpt2-o1)在前5名中占2席,阿里系qwq-32b排名第6与第5名得分相同,展现国产技术竞争力。
-
-
AI大模型在小学奥数考试的综合表现总结
1. 核心优势
- 顶尖答题能力
商用模型(如gemini-2.5、DeepSeek-R1)在奥数题解中已接近人类专家水平。
- 高稳定性与覆盖率
商用模型在优秀(≥90分)和良好(80-89分)区间占比超70%,具备大规模教学应用的坚实技术基础。
- 开源潜力可挖掘
DeepSeek-R1等头部开源模型证明,通过针对性优化,开源方案可达到商用标杆水平。
2. 局限性
- 长尾效应显著
低分模型(<60分)占比18%,需严格筛选才能用于教学。
- 开源模型适用场景受限
中低分段开源模型需结合人工审核或定制化训练,难以直接部署。
3. 应用建议
- 高精度场景
优先选择商用头部模型(如gemini-2.5、360zhinao2-o1),确保答案正确性。
- 成本敏感场景
采用开源标杆模型(如DeepSeek-R1)并针对性微调,平衡性能与预算。
- 风险规避
避免直接使用60分以下模型,尤其是开源低分模型错误率较高。
二、评测维度:
针对教育行业-小学奥数领域考试所涉及的专业知识,构建评测题集,进行评测。
各科目完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
三、评测方法:
根据以上评测维度和题集构建,选取国内外的106个大模型进行实测横评,让他们分别答题,根据结果进行打分,并统计每个大模型的答题准确率,输出综合得分和排名。每一个大模型评测的评测题集、评测得分、评测错题,均可见、可查询、可溯源!
*106个大模型得分排名(图)|绿色(闭源),蓝色(开源)
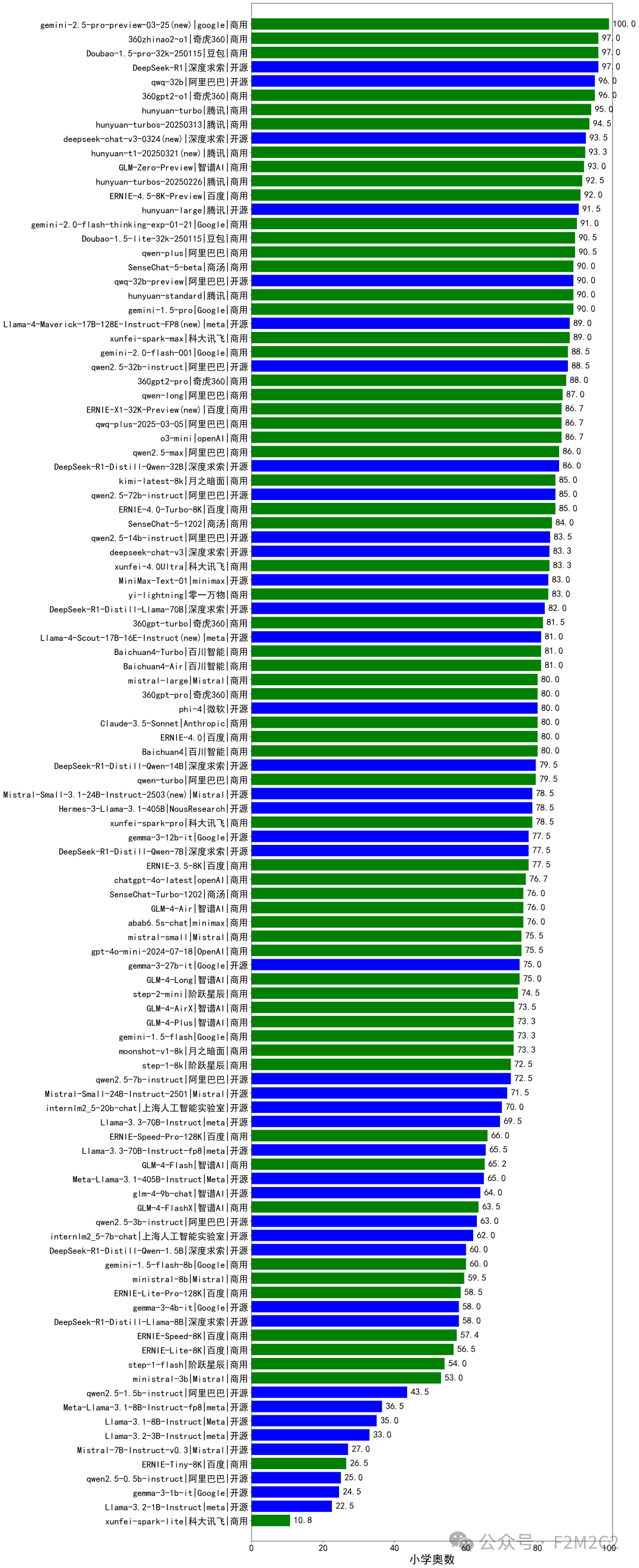
*106个大模型列表、得分和排名:

关于大模型评测EasyLLM:https://easyllm.site
-
最全——全球最全大模型评测平台,已囊括200+大模型、300+评测维度
-
最新——每周更新大模型排行榜
-
最方便——无需注册/梯子,国内外各个大模型可一键评测
-
结果可见——所有大模型评测的方法、题集、过程、得分结果,可见可追溯
-
错题本——百万级大模型错题本
-
免费——为您的私有模型提供免费的全方位评测服务,欢迎私信

我们的目标是:
通过评测为大家透视化呈现,各个大模型的能力边界,以支持大家高效使用!欢迎交流!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









