









Requests对图片验证码的处理
在web端的登录接口经常会有图片验证码的输入,而且每次登录时图片验证码都是随机的;当通过request做接口登录的时候要对图片验证码进行识别出图片中的字段,然后再登录接口中使用;
通过request对图片验证码的识别方法(带有噪点的图片)
一、通过在本地安装OcrServer工具识别图片验证码
百度下载ocrserver工具
如下图:解压后双击OcrServer.exe;然后电脑的右下角会显示该服务的IP和端口


二、通过python编写脚本,并配合OcrServer工具,识别出图片验证码的值
前置条件:导入需要的插件
import base64 import request
1、发送图片验证码的接口,返回图片的响应后保存到指定文件夹
# 获取验证码图片,并保存下来为123.png
response = requests.get('获取验证码图片的URL地址')
img = response.content
with open('../sample/123.png','wb') as f:
f.write(img)
2、打开并读取图片后,通过base64对图片进行编码
# 读取图片后,通过base64对图片进行编码
png = open('123.png','rb')
res = png.read()
s = base64.b64encode(res)
png.close()
# print(s.decode('ascii'))
3、在本地打开OcrServer.exe插件后,发送编码后的图片到指定的url地址,返回值为json格式
# 在本地打开OcrServer.exe插件后,发送编码后的图片到指定的url地址,返回值为json格式:{"code":"验证码图片的值"}
response = requests.post(url="http://127.0.0.1:12349",data=s)
code_num = response.json()
print(code_num['code'])
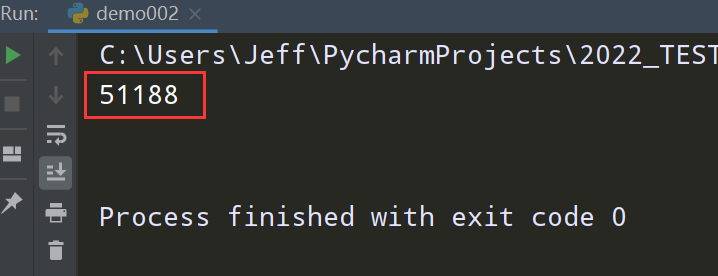
4、查看识别的验证码图片的值
获取到的验证码图片如下图

代码执行后输出的结果如下图

全部代码如下图示例:可写成一个封装类,用来调用
import base64
import requests# 获取验证码图片,并保存下来为123.png
response = requests.get('获取图片验证码的url地址')
img = response.content
with open('../sample/123.png','wb') as f:
f.write(img)# 读取图片后,通过base64对图片进行编码
png = open('123.png','rb')
res = png.read()
s = base64.b64encode(res)
png.close()
# print(s.decode('ascii'))# 在本地打开OcrServer.exe插件后,发送编码后的图片到指定的url地址,返回值为json格式{“code”:"验证码图片的值"}
response = requests.post(url="http://127.0.0.1:12349",data=s)
code_num = response.json()
print(code_num['code'])
通过编写python代码,导入第三方库(),识别图片验证码(没有噪点的图片)
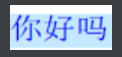
没有噪点的图片;如下图:
纯数字:下面代码的图片名称以为666.png代替

纯中文:下面代码的图片名称以为999.png代替
1、首先下载 Pillow库和 pytesseract库,用来识别图片验证码
pip install Pillow pip install pytesseract
2、通过导入第三方库,然后编写如下代码识别图片验证码;
示例代码:下面以纯数字的图片验证码举例
from PIL import Image
import pytesseract# pytesseract和PIL只能对图片验证码没有噪点的识别成功
path = '666.png'
captcha = Image.open(path)
result = pytesseract.image_to_string(captcha,lang="chi_sim")
print(result)
执行结果:识别成功
示例代码:下面以纯中文的图片验证码举例
from PIL import Image
import pytesseract# pytesseract和PIL只能对图片验证码没有噪点的识别成功
path = '999.png'
captcha = Image.open(path)
result = pytesseract.image_to_string(captcha,lang="chi_sim")
print(result)
执行结果:识别成功

获取验证码图片的URL地址
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









