








🪐🪐🪐欢迎来到程序员餐厅💫💫💫
主厨:邪王真眼
主厨的主页:Chef‘s blog
所属专栏:c++大冒险
总有光环在陨落,总有新星在闪烁
C++11小故事:
统一的列表初始化
{}初始化
struct Point
{
int _x;
int _y;
};
int main()
{
int array1[] = { 1, 2, 3, 4, 5 };
Point p = { 1, 2 };
return 0;
}C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和自定义的类型,他的本意或许是想给所有变量一个统一的初始化方案(使用初始化列表时,可添加“=”,也可不添加)。
-
对内置类型:
int x2{ 2 };
int x2={2};
int array1[]{ 1, 2, 3, 4, 5 };
double y={1.0};
double y{1.0};
Point p{ 1, 2 };
// C++11中列表初始化也可以适用于new表达式中
int* pa = new int[4]{ 0 };-
对于结构体:
struct Point
{
int _x;
int _y;
};
int main()
{
struct Point p{1,0};
struct Point{1,0};
}-
创建对象时使用列表初始化调用构造函数初始化
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
,_month(month)
,_day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2022, 1, 1); // old style
// C++11支持的列表初始化,这里会调用构造函数初始化
Date d2{ 2022, 1, 2 };
Date d3 = { 2022, 1, 3 };
return 0;
}注意事项:
- d1是调用了构造函数
- d2是c++11的新初始化并且直接调用构造函数
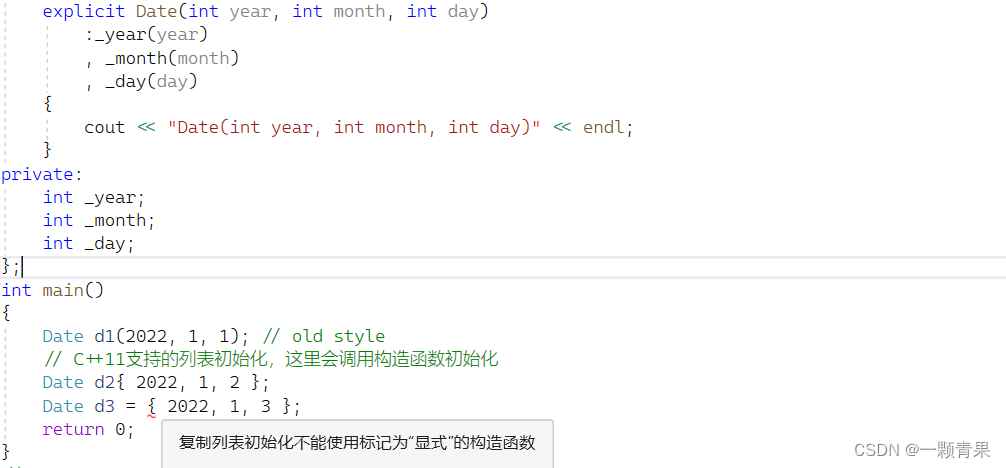
- d3:{2022,1,3}先发生隐式类型转换,通过调用构造函数生成一个类,在以拷贝构造的方式生成d3,证明方法:就是用explicit修饰构造函数(会封锁他的隐类类型转换)就会导致报错(如下图所示)
std::initializer_list
typeid是操作符,不是函数。运行时获知变量类型名称,可以使用 typeid(变量).name()
-
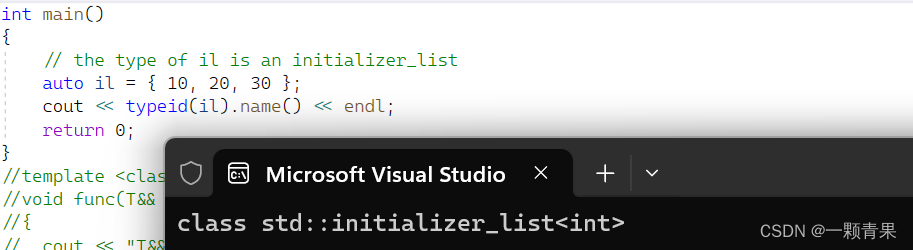
1.std::initializer_list是什么类型:
int main()
{
// the type of il is an initializer_list
auto il = { 10, 20, 30 };
cout << typeid(il).name() << endl;
return 0;
}
-
2.std::initializer_list使用场景:
vector<int> v;
for (int i = 0; i < 5; i++)
{
v.push_back(arr[i]);
}
现在就可以直接用initize_list数据初始化了
int main()
{
vector<int> v = { 1,2,3,4 };
vector<int> v{ 1,2,3,4 };
// 这里{"sort", "排序"}会先初始化构造一个pair对象
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
// 使用大括号对容器赋值
v = {10, 20, 30};
return 0;其实这个新类型就是一个类模板,

他的接口也是十分简单

- constructor:构造函数
- size:表示长度,
- begin,end:迭代器
initializer_list本质上是一个通过迭代器访问数组的容器。当其它容器(vector)通过initializer_list构造自己,其实就该容器遍历initize_list的迭代器,从而把里面的元素一个一个插入
让模拟实现的vector也支持{}初始化和赋值
template<class T>
class vector {
public:
typedef T* iterator;
vector(initializer_list<T> l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
typename initializer_list<T>::iterator lit = l.begin();
while (lit != l.end())
{
*vit++ = *lit++;
}
}
vector<T>& operator=(initializer_list<T> l) {
vector<T> tmp(l);
std::swap(_start, tmp._start);
std::swap(_finish, tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};声明
auto
- 此时的p就是int*
int i = 10;
auto p = &i;
cout<<typeid(i).name()<<endl;
cout << typeid(p).name();
- auto帮我们省去了写冗长的变量类型名的麻烦
auto pf = strcpy;
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();注意事项:
- auto 定义变量必须在定义时初始化
- 函数形参以及返回值不能用auto
decltype
decltype可以检测一个变量或表达式的类型,并且拿这个类型去声明新的类型
int a = 1;
double b = 1.0;
cout<<typeid(decltype( a * b)).name();
- decltype的一些使用使用场景
int a = 1;
double b = 1.0;
decltype(a * b) c = 1;
cout<<typeid(c).name();
nullptr
在C/C++编程习惯中,如果一个指针没有合法的指向,我们基本都是按照如下 方式初始化:
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
// ……
}NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何
种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(int*)
{
cout<<"f(int*)"<<endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}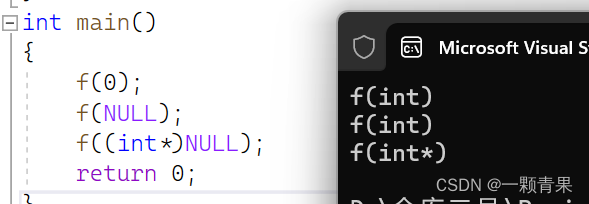
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的
初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器
默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void
*)0。
注意:
- 1. 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入
- 的。
- 2. 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
范围for循环
右值引用和移动语义
左值和右值
-
左值
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;省流:左值显著的特征是可以取地址,但是不一定可以被修改。
-
右值
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
return 0;
}省流:右值显著的特征是不可以取地址,不可以被修改。
简单辨析了什么是左值,什么是右值,现在我们知道左值与右值的最大区别在于可不可以取地址,
右值引用
对左值的引用就是左值引用
我们最开始学的引用就是左值引用,不记得的同学可以去看看我写的这篇博客
c++入门知识
-
右值引用语法
int x = 1, y = 1;
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);-
左值引用可以引用右值吗
- 左值引用能引用左值,一般不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值(常量具有常性,不能修改,如果我们直接把一个常量交给引用,就可能通过引用来修改这个常量,这违背了常性。因此不能直接引用一个右值常量,但是当我们使用const引用,就无法被修改,那么就可以引用了)
// 左值引用只能引用左值,不能引用右值。
int a = 10;
int& ra1 = a; // ra为a的别名
//int& ra2 = 10; // 编译失败,因为10是右值
// const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10;
const int& ra4 = a;- 右值引用可以引用左值吗
原本右值引用是无法引用左值的,但是c++11提供了一个函数move可以把一个左值强转为右值
int a = 10;
// 右值引用可以引用move以后的左值
int&& r3 = std::move(a);注意:move不会改变参数本身的左值属性,这一点可以参考强制类型转化:
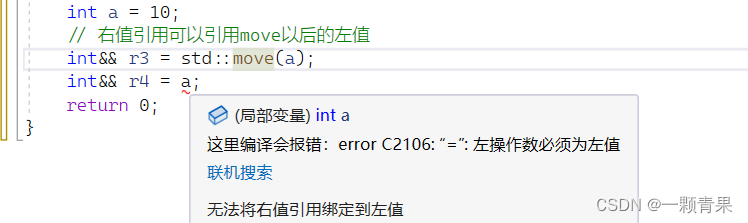
r3右值引用一个被move的左值a,修改r3也会修改左值a,因为r3即是a的别名
int a = 10;
int&& r3 = move(a);
r3 = 1;
cout << a;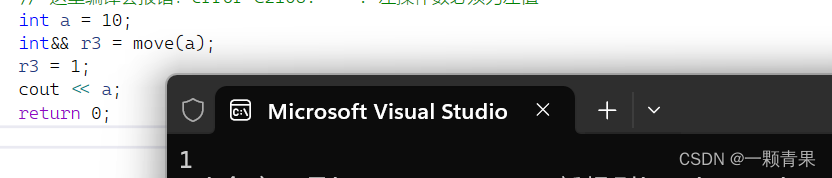
- 关于对常量的右值引用:
先说结论
当右值引用了常量,引用会把常量区中的数据拷贝一份到栈区,然后该引用指向栈区中拷贝后的数据
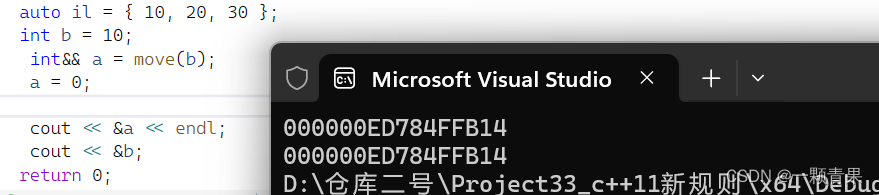
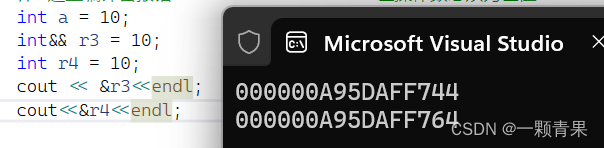
int&& r3 = 10;
r3 = 1;理由一:
如果r3拿到的就是常量10本身,那就可以对其进行修改,那以后我们在用10给别的变量赋值时,他就不再是10了,这显然是十分荒谬的,因此得证
理由二:
看地址
如果r3拿到的就是常量10本身,那他的地址因该是常量区,与10地址相同,但显然r3与r4地址相近,是在栈区。
右值引用使用场景和意义
-
左值引用的使用场景:
void func1(string& s)
{
;
}
void func2(string s)
{
;
}
int main()
{
string s1("hello world");
// func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值
int a = 0, b = 0;
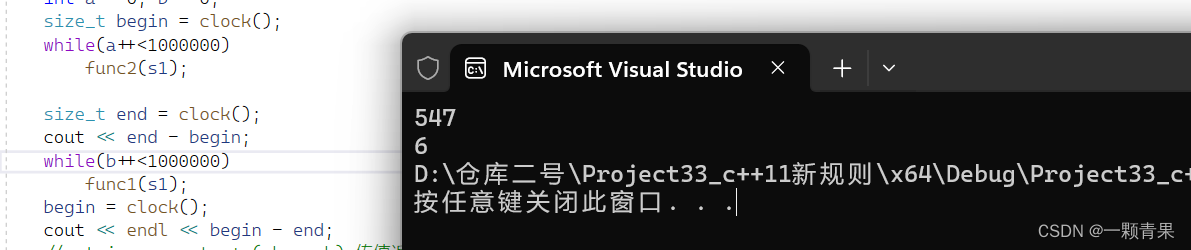
size_t begin = clock();
while(a++<100000000)
func2(s1);
size_t end = clock();
cout << end - begin;
while(b++<100000000)
func1(s1);
begin = clock();
cout << endl << begin - end;
} (realse版本)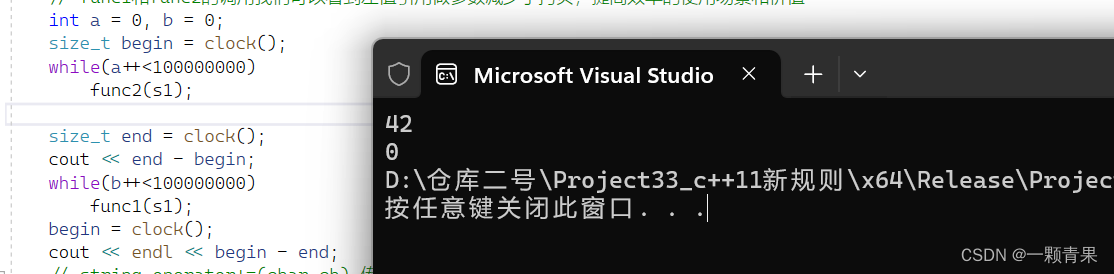
string& func1(string& s)
{
return s;
}
string func2(string& s)
{
return s;
}
int main()
{
string s1("hello world");
// func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值
int a = 0, b = 0;
size_t begin = clock();
while(a++<1000000)
func2(s1);
size_t end = clock();
cout << end - begin;
while(b++<1000000)
func1(s1);
begin = clock();
cout << endl << begin - end;
}
-
左值引用的短板:
string func()
{
string s("aaa");
return s;
}
int main()
{
string s =func();
}因此,右值引用闪亮登场。
我们之前说了被move的左值可以被右值引用,除此之外:
C++会把即将离开作用域的非引用类型的返回值当成右值,这种类型的右值也称将亡值
产生思想:假设b是将亡值,用它去构造a,那我干嘛还要进行深拷贝,我直接把b的数据转移到a身上不就行了(因为b马上自己也要释放空间,那这些数据也会消失,不如直接给a)
-
移动构造、移动赋值:
用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己。
还有移动赋值原理相同
class _string
{
public:
_string(const char* str = "")//"\0"=="",因为结尾没有'\0'会补
: _size(strlen(str))
, _capacity(_size == 0 ? 3 : _size)
{
_str = new char[_capacity + 1];//_capacity不包括最后的'\0'
strcpy(_str, str);
}
_string(_string&& s)
:_str(nullptr)
, _size(s._size)
, _capacity(s._capacity)
{
cout << "移动构造" << endl;
std::swap(_str, s._str);
}
_string& operator=(_string&&s)
{
cout << "移动赋值" << endl;
std::swap(_str, s._str);
}
char* _str;
size_t _size;
size_t _capacity;
};
_string get_string()
{
_string str("");
return str;
}int main()
{
_string s2 = get_string();
return 0;
}相较于之前的两次或一次拷贝构造,因为get_string的返回值是右值,所以直接调用一次或两次移动构造,而移动构造也不是深拷贝,而是直接用swap交换来进行拷贝,效率自然提高
移动构造之所以这么叫,就是因为移走了别人的资源。这部分资源之所以会被移走,就是因为它有右值属性。而它之所以有右值属性,要么就是这个变量是个将亡值,资源不转移就浪费了;要么就是被程序员亲自move了,程序员许可把这个对象的资源转移走,这就保证了资源移动的安全性。
移动语义(Move Semantics)是 C++11 引入的一项重要特性,它允许对象的资源(如堆上分配的内存)在不进行深度复制的情况下进行转移。通过移动语义,可以将对象的资源从一个对象转移到另一个对象,从而避免不必要的内存拷贝,提高程序性能和效率。
万能引用
-
引用折叠
在下面的函数模板中,T&&并不是表示右值引用,他会识别传参类型,传参为左值就是左值引用,传参是右值就是右值引用
template<class T>
void PerfectForward(T&& t)
{
cout << "右值引用" << endl;
}证明如下
template<class T>
void PerfectForward(T&& t)
{
cout << "右值引用" << endl;
}
template<class T>
void PerfectForward(const T& t)
{
cout << "左值引用" << endl;
}
int main()
{
int a = 10;
PerfectForward(move(a));
PerfectForward(a);
return 0;
}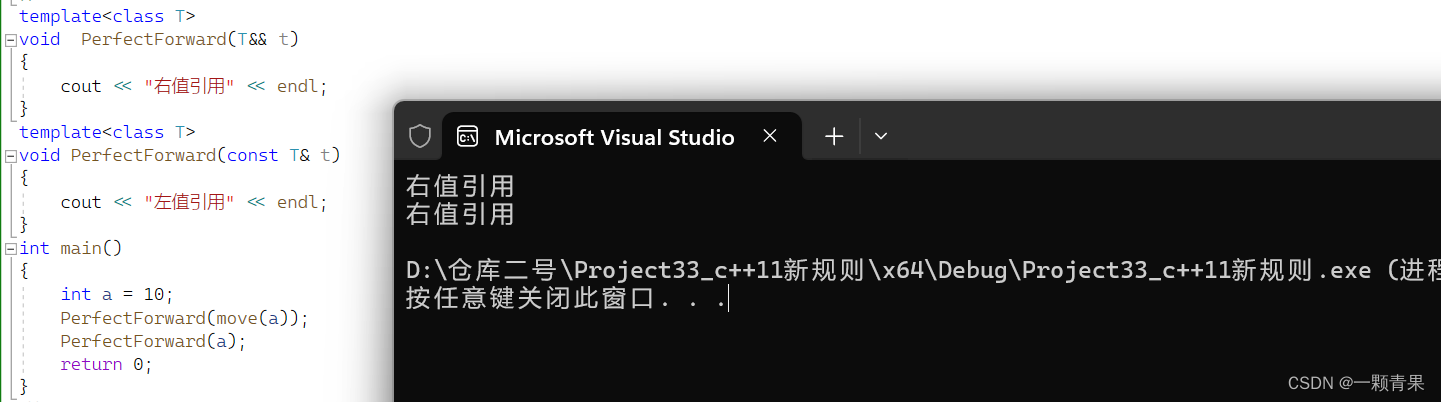
发现第二个函数也是调用的第一个函数模板,则说明第一个函数模板所生成的函数比第二个更适合所传参数,我们知道第二个生成了const int&,最适合的是int&,得证。
可以看作是&&折叠成了一个&,所以万能引用又称为引用折叠
请看以下的代码
void func(int&& t)
{
cout << "右值引用" << endl;
}
void func(const int&& t)
{
cout << "const右值引用" << endl;
}
void func(const int&t)
{
cout << "const左值引用" << endl;
}
void func(int& t)
{
cout << "左值引用" << endl;
}
template<class T>
void PerfectForward(T&& t)
{
func(t);
}
int main()
{
const int a = 10;
PerfectForward(move(a));
PerfectForward(a);
int b = 10;
PerfectForward(move(b));
PerfectForward(b);
PerfectForward(10);
return 0;
}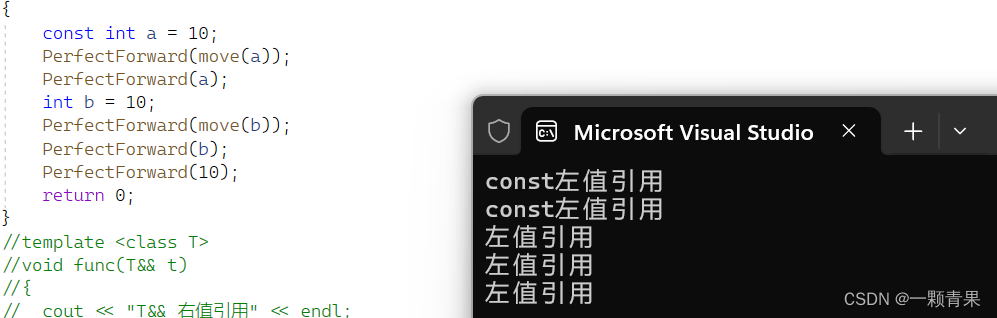
所有都是左值,why???
解答:
a右值引用后b,右值引用指向的对象b是右值属性,但是引用本身a是左值属性(对象b有无const属性会被a继承)
有的老铁要说了在把func变成func(move(T))
万万不可啊,假如我传了一个右值那还好,你这样保证了它的属性不改变,可假如人家本来就是左值呢?那你就把它改成了右值了,这不就出问题了
为什么c++11要这么设计呢?
我们右值引用是为了移动语义,说白了就是转移资源,假如引用后依旧是右值,因为右值是不能被修改的,那就实现不了转移资源,但这样也有bug,即是我们可能会多个函数嵌套,最里面才是转移资源,但它在第一层就把值从左值变成了右值,后面面对函数重载就可能调用错,那怎莫让它类型不改变呢
-
完美转发闪亮登场:
C++提供了一个函数模板forward,称为完美转发,其可以自动识别到参数的左右值类型,从而将其转化为原来的值的类型。
void func(int&& t)
{
cout << "右值引用" << endl;
}
void func(const int&& t)
{
cout << "const右值引用" << endl;
}
void func(const int&t)
{
cout << "const左值引用" << endl;
}
void func(int& t)
{
cout << "左值引用" << endl;
}
template<class T>
void PerfectForward(T&& t)
{
func(forward<T>(t));
}
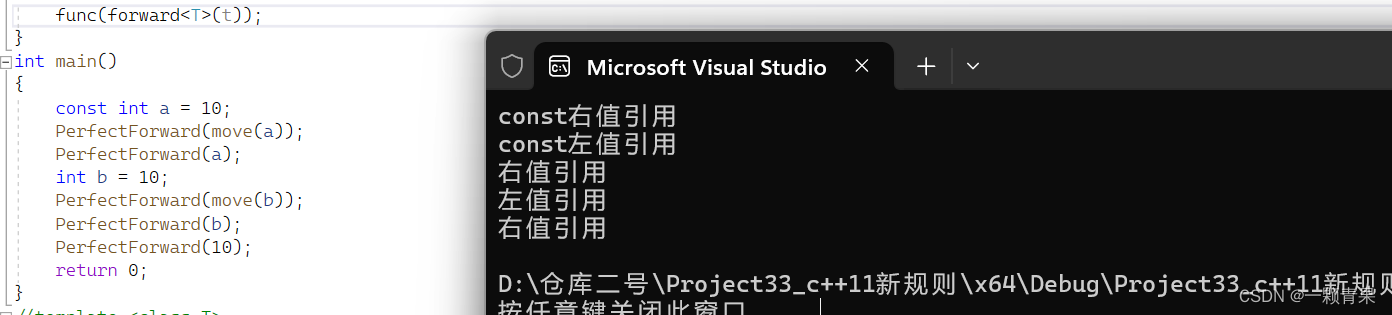
int main()
{
const int a = 10;
PerfectForward(move(a));
PerfectForward(a);
int b = 10;
PerfectForward(move(b));
PerfectForward(b);
PerfectForward(10);
return 0;
}
完美转发实际中的使用场景:
template<class T>
struct ListNode
{
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
T _data;
};
template<class T>
class List
{
typedef ListNode<T> Node;
public:
List()
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
void PushBack(T&& x)
{
//Insert(_head, x);
Insert(_head, std::forward<T>(x));
}
void PushFront(T&& x)
{
//Insert(_head->_next, x);
Insert(_head->_next, std::forward<T>(x));
}
void Insert(Node* pos, T&& x)
{
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = std::forward<T>(x); // 关键位置
// prev newnode pos
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
void Insert(Node* pos, const T& x)
{
Node* prev = pos->_prev;
Node* newnode = new Node;
newnode->_data = x; // 关键位置
// prev newnode pos
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
private:
Node* _head;
};
int main()
{
List<bit::string> lt;
lt.PushBack("1111");
lt.PushFront("2222");
return 0;
}总结:
我们今天学习了初始化、声明以及右值引用三个点,大概是学完了一半,剩下的就下次再讲啦。
🥰创作不易,你的支持对我最大的鼓励🥰
🪐~ 点赞收藏+关注 ~🪐
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









