







作者信息
Name :Zing ;
Ema i l : bwcxzsj@stu. hbnu. edu. cn
目录
1.def del_and_create_dir(filename):
4.def save_course_images(driver, num_images):
7.def get_MOOC(browser, url, search_text, sum_page, num_images):
简单说明
在上一篇博客中,我们了解了爬虫的基本概念和基础功能,并用python实现了一个简单的收集慕课网站上相关课程的评论的爬虫程序。在这篇文章中我们基于这个程序做了简单的改进,增加了一些新的功能,如增添了一个用户扫码登录功能,以及爬取到的内容不仅是评论的文字也能收集该课程的封面图片等。下面我将对这个爬虫程序进行详细的讲解。
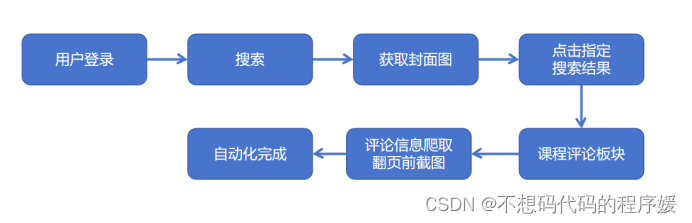
一、自动化流程介绍
该实战代码主要实现了通过扫码登录并利用Selenium爬取MOOC课程信息的完整流程。
1.1获取登录二维码
通过download_qr_code函数获取扫码登录页面的二维码图片及其对应的唯一标志key(pollKey)。该函数访问MOOC网站的扫码登录接口,下载并保存二维码图片,同时返回用于轮询登录状态的pollKey。
1.2用户扫描二维码
poll_server函数利用pollKey进行轮询,检查用户是否已扫码并确认登录。通过持续请求服务器,判断扫码状态是否变更为已扫码成功状态,一旦成功,则获取服务器返回的token。
1.3验证登录状态
login_with_token函数使用获取的token向服务器验证登录状态,并获取登录后的cookies。整个扫码登录流程通过qr_code_login函数协调执行,返回登录后的cookies。
在获取到登录后的cookies后,代码进入下一阶段。get_MOOC函数首先初始化Selenium的Edge浏览器驱动并打开MOOC网站。然后,通过调用qr_code_login函数获取登录后的cookies,并将这些cookies添加到Selenium浏览器会话中,确保浏览器具有登录状态。
1.4课程搜索及保存封面图片
代码进行课程搜索。在页面加载完成后,利用Selenium找到搜索框并输入搜索关键词,然后点击搜索按钮。搜索结果加载后,切换到新打开的窗口,保存指定数量的课程封面图片。
1.5点击指定搜索结果
在保存封面图片后,点击搜索结果中的第一个课程,进入课程详情页面。然后点击页面中的“课程评价”按钮,打开评价页面。
1.6获取课程评价信息
代码随后开始爬取评价信息。通过PyQuery解析页面内容,获取当前页面的所有评价文本,并保存到本地文件中。同时,代码会对当前页面截图保存。爬取当前页面的评价信息后,点击“下一页”按钮,重复上述过程,直到爬取完指定数量的页面。
以上是基于整个流程的总体介绍,下面我们来编写代码进行详细解释。
二、代码实现
(一)准备工作
a.自动化流程图
b.导入需要的包
import requests
import time
import os
import re
import xml.dom.minidom
import urllib.request
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery
注意:最开始导入这些库的时候,部分库可能不存在电脑上,需要手动在pycharm或其他编译软件终端 输入 (以requests库不存在为例)pip install requests 并按回车键
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









